




常用内建模块(battery included)
datetime
-
datetime是Python处理日期和时间的标准库。
-
获取当前日期和时间
datetime.datetime.now()>>> from datetime import datetime >>> datetime.now() datetime.datetime(2022, 5, 5, 21, 43, 5, 856610) >>> type(datetime.now()) <class 'datetime.datetime'> >>> print(datetime.now()) 2022-05-05 21:43:25.768222 -
获取指定日期和时间
datetime(2022, 5, 5, 21, 45, 20)>>> dt = datetime(2022, 5, 5, 21, 45, 20) # 注意数字前面不能写0, 05会报错的 >>> print(dt) 2022-05-05 21:45:20 -
datetime 转换为 timestamp
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为
0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。你可以认为:timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00 timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
转换为timestamp只需要简单调用datetime.timestamp()方法, 得到的是一个浮点数,单位是秒,某些语言(java, javascript)中用整数表示毫秒,这个时候除1000就可以得到python的这种形式了。
>>> datetime.now().timestamp()
1651758707.357037
-
timestamp 转 datetime
使用
datetime提供的fromtimestamp()方法, 由于timestamp是浮点数没有时区的概念,在这种转换中默认是转换为本地时间。datetime.utcfromtimestamp()这样可以把timestamp转换为UTC时间。>>> t = 1651758707.357037 >>> print(datetime.fromtimestamp(t)) 2022-05-05 21:51:47.357037 >>> print(datetime.utcfromtimestamp(t)) 2022-05-05 13:51:47.357037 -
str 转换为 datetime
转换方法是通过
datetime.strptime()实现,需要一个日期和时间的格式化字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。详细的说明请参考Python文档。注意转换后的datetime是没有时区信息的。
>>> cday = datetime.strptime('2022-05-05 22:01:01', '%Y-%m-%d %H:%M:%S') >>> print(cday) 2022-05-05 22:01:01 -
datetime 转换为 str
转换方法是通过
strftime()实现的,同样需要一个日期和时间的格式化字符串>>> print(datetime.now().strftime('%a, %b %d %H:%M:%S')) Thu, May 05 22:04:52 -
datetime加减
实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用
+和-运算符,不过需要导入timedelta这个类。>>> from datetime import datetime, timedelta >>> now = datetime.now() >>> now datetime.datetime(2022, 5, 5, 22, 8, 13, 535989) >>> now + timedelta(hours=2) datetime.datetime(2022, 5, 6, 0, 8, 13, 535989) >>> now - timedelta(days=2, hours=10) datetime.datetime(2022, 5, 3, 12, 8, 13, 535989) -
本地时间转换为UTC时间
一个
datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,除非强行给datetime设置一个时区,如果系统时区恰好是UTC+8:00,那么代码就是正确的,否则,不能强制设置为UTC+8:00时区。>>> from datetime import datetime, timedelta, timezone >>> utc_8 = timezone(timedelta(hours=8)) # 设置utc+8时区 >>> now = datetime.now() >>> now datetime.datetime(2022, 5, 5, 22, 12, 9, 68899) >>> now.replace(tzinfo=utc_8) datetime.datetime(2022, 5, 5, 22, 12, 9, 68899, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800))) # 加了时区后的时间应该和上面的时间完全一样,才证明你的时区加的是正确的 -
时区转换
我们可以先通过
datetime.utcnow()拿到当前的UTC时间,再转换为任意时区的时间, 时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。利用带时区的
datetime,通过astimezone()方法,可以转换到任意时区。(不一定要从UTC+0:00开始)
>>> dt_now = datetime.utcnow().replace(tzinfo=timezone.utc) # 拿到UTC时间并设时区为UTC
>>> dt_now
datetime.datetime(2022, 5, 5, 14, 18, 2, 882685, tzinfo=datetime.timezone.utc)
>>> bst = dt_now.astimezone(timezone(timedelta(hours=8))) # 从UTC转为北京时间
>>> bst
datetime.datetime(2022, 5, 5, 22, 18, 2, 882685, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800)))
>>> jst = bst.astimezone(timezone(timedelta(hours=9))) # 从BST转为日本时间
>>> jst
datetime.datetime(2022, 5, 5, 23, 18, 2, 882685, tzinfo=datetime.timezone(datetime.timedelta(seconds=32400)))
eg:假设你获取了用户输入的日期和时间如2015-1-21 9:01:30,以及一个时区信息如UTC+5:00,均是str,请编写一个函数将其转换为timestamp
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
from datetime import datetime, timedelta, timezone
def to_timestamp(dt_str, tz_str):
dt = datetime.strptime(dt_str, '%Y-%m-%d %H:%M:%S')
m = re.search(r'([-+]\d+):(\d+)', tz_str)
h = int(m.group(1)) #提取小时
mins = int(m.group(2)) #提取分钟
tz = timezone(timedelta(hours=h, minutes=mins)) # 创建时区
dt_tz = dt.replace(tzinfo=tz) # 强制设置时区
ts = dt_tz.timestamp()
return ts
t1 = to_timestamp('2015-6-1 08:10:30', 'UTC+7:30')
assert t1 == 1433119230.0, t1
t2 = to_timestamp('2015-5-31 16:10:30', 'UTC-09:00')
assert t2 == 1433121030.0, t2
print('ok')
base64
Base64是一种用64个字符来表示任意二进制数据的方法。即为二进制转字符串。
Base64的出现是为了解决一些二进制文件包含很多无法显示和打印的字符问题。
电子邮件刚问世的时候,只能传输英文,但后来随着用户的增加,中文、日文等文字的用户也有需求,但这些字符并不能被服务器或网关有效处理,因此Base64就登场了。随之,Base64在URL、Cookie、网页传输少量二进制文件中也有相应的使用。
Base64的编码原理
Base64的原理比较简单,每当我们使用Base64时都会先定义一个类似这样的数组:
[‘A’, ‘B’, ‘C’, … ‘a’, ‘b’, ‘c’, … ‘0’, ‘1’, … ‘+’, ‘/’]
上面就是Base64的索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符,这是标准的Base64协议规定。在日常使用中我们还会看到“=”或“==”号出现在Base64的编码结果中,“=”在此是作为填充字符出现,后面会讲到。
具体转换步骤
第一步,将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。
第二步,将上面的24个二进制位每6个一组,共分为4组。
第三步,在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。

第四步,根据Base64编码对照表(见下图)获得对应的值。
-
0 A 17 R 34 i 51 z
-
1 B 18 S 35 j 52 0
-
2 C 19 T 36 k 53 1
-
3 D 20 U 37 l 54 2
-
4 E 21 V 38 m 55 3
-
5 F 22 W 39 n 56 4
-
6 G 23 X 40 o 57 5
-
7 H 24 Y 41 p 58 6
-
8 I 25 Z 42 q 59 7
-
9 J 26 a 43 r 60 8
-
10 K 27 b 44 s 61 9
-
11 L 28 c 45 t 62 +
-
12 M 29 d 46 u 63 /
-
13 N 30 e 47 v
-
14 O 31 f 48 w
-
15 P 32 g 49 x
-
16 Q 33 h 50 y
从上面的步骤我们发现:
-
Base64字符表中的字符原本用6个bit就可以表示,现在前面添加2个0,变为8个bit,会造成一定的浪费。因此,Base64编码之后的文本,要比原文大约三分之一。
-
为什么使用3个字节一组呢?因为6和8的最小公倍数为24,三个字节正好24个二进制位,每6个bit位一组,恰好能够分为4组。
Python内置的base64可以直接进行base64的编解码:
关于网页http://jandan.net/girl/MjAyMjAxMjUtOTY=#comments 的加密:
import base64
str1 = "MjAyMjAxMjUtOTY="
result = base64.b64decode(str1)
b'20220125-96' # 使用.decode变为str
str = '20220125-96'
>>> base64.b64encode(str.encode()) #.encod变为二进制
b'MjAyMjAxMjUtOTY='
python bytes和str两种类型可以通过函数encode()和decode()相互转换,
- str→bytes:encode()方法。str通过encode()方法可以转换为bytes。
- bytes→str:decode()方法。
如果一个字符串缺少“=”,使用下面的方法可以补全“=”再解码
def safe_base64_decode(s):
while len(s) % 4: #补全“=”凑4的倍数字符好解码
s += "="
return base64.b64decode(s)
assert b'abcd' == safe_base64_decode('YWJjZA=='), safe_base64_decode(
'YWJjZA==')
assert b'abcd' == safe_base64_decode('YWJjZA'), safe_base64_decode('YWJjZA')
print('ok')
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_:
>>> base64.b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd++//'
>>> base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd--__'
>>> base64.urlsafe_b64decode('abcd--__')
b'i\xb7\x1d\xfb\xef\xff'
示例说明
以下图的表格为示例,我们具体分析一下整个过程。

- 第一步:“M”、“a”、"n"对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。
- 第二步:如图红色框,将24位每6位二进制位一组分成四组。
- 第三步:在上面每一组前面补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。
- 第四步:用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。
位数不足情况
上面是按照三个字节来举例说明的,如果字节数不足三个,那么该如何处理?
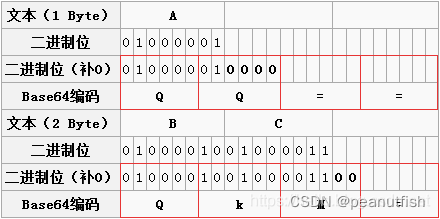
-
一个字节:一个字节共8个二进制位,依旧按照规则进行分组。此时共8个二进制位,每6个一组,则第二组缺少4位,用0补齐,得到两个Base64编码,而后面两组没有对应数据,都用“=”补上。因此,上图中“A”转换之后为“QQ==”;
-
两个字节:两个字节共16个二进制位,依旧按照规则进行分组。此时总共16个二进制位,每6个一组,则第三组缺少2位,用0补齐,得到三个Base64编码,第四组完全没有数据则用“=”补上。因此,上图中“BC”转换之后为“QKM=”;
collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
格式:# namedtuple('名称', [属性list]):
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
>>> Point = namedtuple('Point', ['x', 'y'])
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
>>> isinstance(p, tuple) # 创建的`Point`对象是`tuple`的一种子类
True
>>> p.x = 1 # 属于tuple对象不能修改的
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈,deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
>>> from collections import deque
>>> dq = deque(['y', 'x', 'z'])
>>> dq.append('q')
>>> dq.appendleft('a')
>>> dq
deque(['a', 'y', 'x', 'z', 'q'])
>>> dq.popleft()
'a'
>>> dq
deque(['y', 'x', 'z', 'q'])
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict,除此之外的defaultdict的行为跟dict是完全一样的。
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
OrderedDict
使用dict时,Key是无序的。如果要保持Key的顺序,可以用OrderedDict,注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> list(od.keys()) # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
from collections import OrderedDict
class LastUpdateordereddict(OrderedDict):
def __init__(self, capacity):
self._capacity = capacity
super().__init__()
def __setitem__(self, key, value):
containkey = 1 if key in self else 0
if len(self) - containkey >= self._capacity:
last = self.popitem(last=False)
print('remove item', last)
if containkey:
del self[key]
print('set',(key, value) )
else:
print('add', (key, value))
super().__setitem__(key, value)
ludict = LastUpdateordereddict(3)
ludict['a'] = 1
ludict['b'] = 2
ludict['c'] = 3
print(ludict)
ludict['a'] = 4
ludict['d'] = 5
print(ludict)
>>>t3.py
add ('a', 1)
add ('b', 2)
add ('c', 3)
LUordereddict([('a', 1), ('b', 2), ('c', 3)])
set ('a', 4)
remove item ('b', 2)
add ('d', 5)
LUordereddict([('c', 3), ('a', 4), ('d', 5)])
ChainMap
ChainMap可以把一组dict串起来并组成一个逻辑上的dict。ChainMap本身也是一个dict,但是查找的时候,会按照顺序在内部的dict依次查找。
什么时候使用ChainMap最合适?举个例子:应用程序往往都需要传入参数,参数可以通过命令行传入,可以通过环境变量传入,还可以有默认参数。我们可以用ChainMap实现参数的优先级查找,即先查命令行参数,如果没有传入,再查环境变量,如果没有,就使用默认参数。
下面的代码演示了如何查找user和color这两个参数:
from collections import ChainMap
import os, argparse
# 构造缺省参数:
defaults = {
'color': 'red',
'user': 'guest'
}
# 构造命令行参数:
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = { k: v for k, v in vars(namespace).items() if v }
# 组合成ChainMap:
combined = ChainMap(command_line_args, os.environ, defaults)
# 打印参数:
print('color=%s' % combined['color'])
print('user=%s' % combined['user'])
结果:
$ python3 use_chainmap.py # 没有任何参数时,打印出默认参数
color=red
user=guest
$ python3 use_chainmap.py -u bob # 当传入命令行参数时,优先使用命令行参数
color=red
user=bob
$ user=admin color=green python3 use_chainmap.py -u bob # 同时传入命令行参数和环境变量,命令行参数的优先级较高
color=green
user=bob
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for i in "atomosphere":
... c[i] += 1
...
>>> c
Counter({'o': 2, 'e': 2, 'a': 1, 't': 1, 'm': 1, 's': 1, 'p': 1, 'h': 1, 'r': 1})
>>> c.update('hello') # 将hello里面字符次数加到前面的结果中
>>> c
Counter({'o': 3, 'e': 3, 'h': 2, 'l': 2, 'a': 1, 't': 1, 'm': 1, 's': 1, 'p': 1, 'r': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出每个字符出现的次数。
struct
Python没有专门处理字节的数据类型。但由于b'str'可以表示字节,所以,字节数组=二进制str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
Python提供了一个struct模块来解决bytes和其他二进制数据类型的转换。
struct的pack函数把任意数据类型变成bytes:
>>> import struct
>>> struct.pack('>I', 10240099)
b'\x00\x9c@c'
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。
unpack把bytes变成相应的数据类型:
>>> struct.unpack('>IH', b'\xf0\xf0\xf0\xf0\x80\x80')
(4042322160, 32896)
根据>IH的说明,后面的bytes依次变为I:4字节无符号整数和H:2字节无符号整数。
所以,尽管Python不适合编写底层操作字节流的代码,但在对性能要求不高的地方,利用struct就方便多了。
struct模块定义的数据类型可以参考Python官方文档:
https://docs.python.org/3/library/struct.html#format-characters
Windows的位图文件(.bmp)是一种非常简单的文件格式,我们来用struct分析一下。
首先找一个bmp文件,没有的话用“画图”画一个。
读入前30个字节来分析:
>>> s = b'\x42\x4d\x38\x8c\x0a\x00\x00\x00\x00\x00\x36\x00\x00\x00\x28\x00\x00\x00\x80\x02\x00\x00\x68\x01\x00\x00\x01\x00\x18\x00'
BMP格式采用小端方式存储数据,文件头的结构按顺序如下:
两个字节:'BM'表示Windows位图,'BA'表示OS/2位图; 一个4字节整数:表示位图大小; 一个4字节整数:保留位,始终为0; 一个4字节整数:实际图像的偏移量; 一个4字节整数:Header的字节数; 一个4字节整数:图像宽度; 一个4字节整数:图像高度; 一个2字节整数:始终为1; 一个2字节整数:颜色数。
所以,组合起来用unpack读取:
>>> struct.unpack('<ccIIIIIIHH', s)
(b'B', b'M', 691256, 0, 54, 40, 640, 360, 1, 24)
# 结果显示,`b'B'`、`b'M'`说明是Windows位图,位图大小为640x360,颜色数为24。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









