




 本文深入讲解Scrapy框架的模块功能、工作流程及安装方法,演示如何创建项目、爬虫,定义爬取字段,配置settings,使用logging,以及在PyCharm中调试。此外,文章还介绍了如何使用pipeline保存数据,包括JSON文件保存方式、异步数据存储到MySQL,以及发送POST请求的方法。
本文深入讲解Scrapy框架的模块功能、工作流程及安装方法,演示如何创建项目、爬虫,定义爬取字段,配置settings,使用logging,以及在PyCharm中调试。此外,文章还介绍了如何使用pipeline保存数据,包括JSON文件保存方式、异步数据存储到MySQL,以及发送POST请求的方法。
Python爬虫之Scrapy框架的使用(一)
一:scrapy框架介绍
Scrapy官方文档:
https://docs.scrapy.org/en/latest/intro/tutorial.html
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
Scrapy使用Twisted异步网络框架,可以加快下载速度。
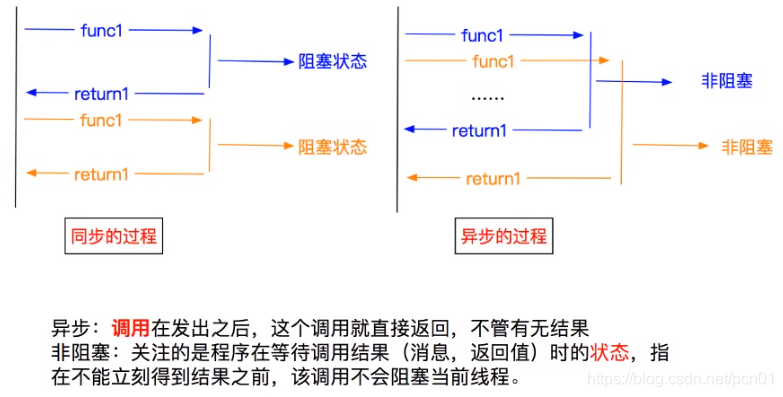
异步与非阻塞的区别:
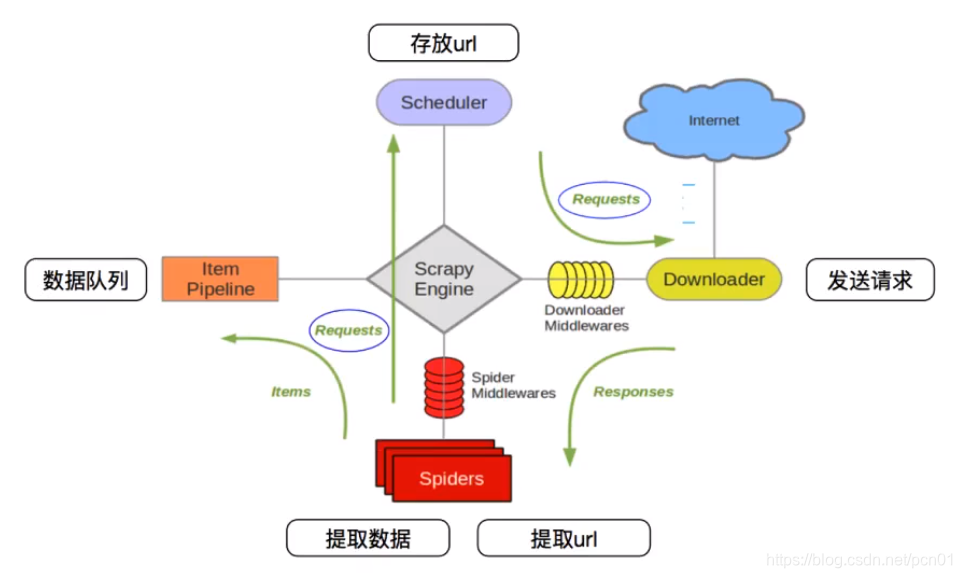
1.1 Scrapy框架模块功能
Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
1.2 Scrapy爬虫流程
1.3 安装scrapy
# Scrapy官方文档:
http://doc.scrapy.org/en/latest
# Scrapy中文文档:
http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Linux系统上安装:
# Ubuntu16.04上安装
apt-get install python3-dev build-essential python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
# 如果是在虚拟环境中安装上面的命令不执行,直接执行下面的命令即可
pip install scrapy
Win系统上安装:
# win上虚拟环境中安装
# 以下两个模块都要安装
pip install scrapy
# 如果在windows系统下,提示这个错误ModuleNotFoundError: No module named 'win32api',那么使用以下命令可以解决
pip install pypiwin32
如果是在Win系统上安装出错,可到下面的地址下载scrapy,Twisted 两个程序。注意选择对应的版本。
https://www.lfd.uci.edu/~gohlke/pythonlibs/
然后在scrapy程序下载的目录中打开命令窗口,使用以下命令进行安装
pip install -i https://pypi.douban.com/simple Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl # cp37指的是win上安装的python版本为3.7
pip install -i https://pypi.douban.com/simple Scrapy-2.1.0-py3-none-any.whl
# Scrapy所需要的依赖会从douban源进行下载
二:scrapy框架的使用
2.1 创建scrapy项目
要使用Scrapy框架创建项目,需要通过命令来创建。首先进入到你想把这个项目存放的目录。然后使用以下命令创建:
# scrapy startproject [项目名称]
scrapy startproject qiushi
目录结构介绍:
# 以下介绍下主要文件的作用
items.py:用来存放爬虫爬取下来数据的模型。
middlewares.py:用来存放各种中间件的文件。
pipelines.py:用来将items的模型存储到本地磁盘中。
settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。
scrapy.cfg:项目的配置文件。
spiders包:以后所有的爬虫,都是存放到这个里面。
2.2 创建爬虫
然后进入到项目目录,创建一个爬虫:
# scrapy genspider 爬虫名 域名
cd qiushi
scrapy genspider qs qiushibaike.com
# 创建了一个名字叫做qs的爬虫,并且能爬取的网页只会限制在qiushibaike.com这个域名下
默认会在spiders目录下自动创建一个名为qs.py的文件,在该文件下可编写要爬取的url数据:
import scrapy
from qiushi.items import QiushiItem
class QsSpider(scrapy.Spider):
name = 'qs'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
content = response.xpath('//div[@class="col1 old-style-col1"]/div') # 获取前面div下的所有子div元素
for con in content:
author = con.xpath('.//h2/text()').extract_first()
contents = con.xpath('.//div[@class="content"]/span/text()').extract_first()
item = QiushiItem(author = author, content = contents)
yield item
# 获取下一页url
next_url = response.xpath('//ul[@class="pagination"]/li[last()]/a/@href').extract_first()
if not next_url: return
yield scrapy.Request(parse.urljoin(response.url, next_url), callback = self.parse)
2.3 items中定义要爬取的字段
# 在items.py文件中定义需要的字段
import scrapy
class QiushiItem(scrapy.Item):
author = scrapy.Field()
article = scrapy.Field()
2.4 settings配置文件配置
在做一个爬虫之前,一定要记得修改setttings.py中的设置。两个地方是强烈建议设置的。
ROBOTSTXT_OBEY设置为False。默认是True,即遵守机器协议,那么在爬虫的时候,scrapy首先去找robots.txt文件,如果没有找到。则直接停止爬取。
DEFAULT_REQUEST_HEADERS添加User-Agent。这个也是告诉服务器,我这个请求是一个正常的请求,不是一个爬虫。
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11' # 添加此行
}
# 需要用到pipelines时在settings配置文件中取消下面三行的注释
ITEM_PIPELINES = {
'myspider.pipelines.MyspiderPipeline': 300,
# 值300表示距离引擎的远近(权重)。值越小表示距离引擎越近。
# 在scrapy中可以定义多个pipelines,该值表示数据经过离引擎的顺序,先经过离引擎最近的pipelines
}
############ 以下是增加的配置项 #################
LOG_LEVEL = "WARNING" # 控制台只输出WARNING及以上等级的日志
2.5 loggin模块的使用
在settings配置文件中配置日志选项:
############ 以下是增加的配置项 #################
LOG_LEVEL = "WARNING" # 控制台只输出WARNING及以上等级的日志
LOG_FILE = './log.log' # 指定log输入的文件路径(有此项配置日志不会在控制台输出,只会输入到文件)
# 日志输出到文件在开发阶段可注释
使用方法如下:
import scrapy
import logging
logger = logging.getLogger(__name__) # 实例化loggin,传入__name__参数会输出当前日志是由哪个文件输出的
class ItcastSpider(scrapy.Spider):
name = 'itcast' # 爬虫名
allowed_domains = ['itcast.cn'] # 允许爬取的范围
start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 最开始请求的URL地址
def parse(self, response): # 这里的函数名必须为parse
# 处理start_url地址对应的响应
# result = response.xpath("//div[@class='li_txt']//h30/text()").extract()
# # extract()没有取到数据返回一个空列表
# print(result)
li_list = response.xpath("//div[@class='tea_con']//li")[:5]
# print(li_list)
for li in li_list:
item = {}
item['name'] = li.xpath(".//h3/text()").extract_first()
# extract_first()取不到数据返回None
item['title'] = li.xpath(".//h4/text()").extract_first()
# print(item)
logger.warning(item) # 这里使用warning是因为在settings配置文件中配置了warning
# yield item # 将数据传递给pipeline处理
日志输出结果如下:

2.6 pycharm中调试scrapy
在命令行中执行命令运行scrapy不方便代码的调试
scrapy crawl qs # qs为spider名
在项目目录下新建start.py文件(文件名随意),内容如下:
from scrapy.cmdline import execute
import sys, os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy', 'crawl', 'qs'])
然后可以运行start.py文件即可运行scrapy程序,或者debug调试模式启动
2.7 pipeline保存数据
使用pipeline的前提是在settings配置文件中启用pipeline:
# 取消注释以下几行
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 300,
}
1:保存为Json文件
import json
class QiushiPipeline:
'''该类中有三个方法会常用到:open_spider, close_spider,process_item'''
def __init__(self):
self.fp = open('duanzi.json', 'w', encoding='utf-8')
def open_spider(self, spider):
# 当爬虫打开时被调用
print('start...')
def process_item(self, item, spider):
# 当爬虫有item传过来时被调用,传递过来的item是一个<class 'qiushi.items.QiushiItem'>对象,所以下面需要将item转换成字典才能被正常序列化
self.fp.write(json.dumps(dict(item), ensure_ascii=False) + '\n')
return item
def close_spider(self, spider):
# 当爬虫关闭时被调用
self.fp.close()
print('finish...')
保存的文件内容如下图:

2:使用JsonItemExporter保存Json文件
from scrapy.exporters import JsonItemExporter
class QiushiPipeline:
'''该类中默认会执行三个方法:open_spider, close_spider,process_item'''
def __init__(self):
self.fp = open('duanzi.json', 'wb')
self.exporter = JsonItemExporter(self.fp, ensure_ascii = False, encoding = 'utf-8')
self.exporter.start_exporting()
def open_spider(self, spider):
print('start...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.fp.close()
print('finish...')
# 最后保存的文件为一个列表中多个字典数据
3:使用JsonLinesItemExporter保存Json文件
from scrapy.exporters import JsonLinesItemExporter
class QiushiPipeline:
'''该类中默认会执行三个方法:open_spider, close_spider,process_item'''
def __init__(self):
self.fp = open('duanzi.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii = False, encoding = 'utf-8')
def open_spider(self, spider):
print('start...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()
print('finish...')
# 最后保存到文件中的数据就是一个个的字典
JsonItemExporter与JsonLinesItemExporter方法都要用二进制的方式来写
首先我们从名字里大致可以看出来了,两者区别 Lines 也就是行的意思。也就是说 前者是一起写进json文件里,后者是我们每次parse函数yield的item,经过处理就直接写入json里面。那么我们可以想一下,前者,既然是一起写入,假如我们爬取的的数据有上万条,那就很吃内存了。后者是一条一条的存,对内存很友好,他每次写入的是一个 dict,但读取的时候,没有前者友好。
2.8 爬虫面试题
面试题:将爬到的数据一份存储到本地,一份存储到数据库,如何实现?
解答:
- 管道文件中一个管道类对应的是将数据存在到一种平台
- 爬虫文件提交的item只会给管道文件中优先级最高的管道类
- process_item中的return item表示将item传递给下一个即将被执行的管道类
案例如下:
import pymysql
class QuishiPipeline:
fp = None
# 重写父类的一个方法:该方法只在开始爬虫时被调用一次
def open_spider(self, spider):
print('开始爬虫...')
self.fp = open('./qiubai.txt', 'w', encoding='utf-8')
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法没接收到一个item对象就会被调用一次
def process_item(self, item, spider):
author = item['author']
content = item['content']
self.fp.write(author + ':' + content + '\n')
return item # 这里会将item传递给下一个管道类。不管有没有下一个管道类,都要将item return
def close_spider(self, spider):
print('结束爬虫...')
self.fp.close()
# 管道文件中一个管道类对应将一组数据存储到一个平台或载体中
# 爬虫文件提交的item类型的对象,最终会提交给哪一个管道类呢?给的一定是优先级高的那个管道
class MysqlPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='172.17.2.36', port=3306, user='root', password='xxxxxxx', db='spider', charset = 'utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into qiubai values(null, "%s", "%s")' % (item["author"], item["content"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
2.9 Scrapy异步保存数据到mysql
import pymysql
from itemadapter import ItemAdapter
from twisted.enterprise import adbapi
class JianshuPipeline:
# 同步保存数据
def __init__(self):
db_params = {
'host': '172.17.2.36',
'port': 3306,
'user': 'root',
'password': 'xxxxx',
'database': 'spider',
'charset': 'utf8'
}
self.conn = pymysql.connect(**db_params)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pubdate'], item['origin_url'], item['article_id']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = 'insert into article(id, title, content, author, avatar, pubdate, origin_url, article_id) values(null, %s, %s ,%s, %s, %s, %s, %s)'
return self._sql
class JianShuTwistedPipeline:
# 异步保存数据
def __init__(self):
db_params = {
'host': '172.17.2.36',
'port': 3306,
'user': 'root',
'password': 'xxxxx',
'database': 'spider',
'charset': 'utf8',
'cursorclass': pymysql.cursors.DictCursor
}
self.db_pool = adbapi.ConnectionPool('pymysql', **db_params)
self._sql = None
@property
def sql(self):
if not self._sql:
self._sql = 'insert into article(id, title, content, author, avatar, pubdate, origin_url, article_id) values(null, %s, %s ,%s, %s, %s, %s, %s)'
return self._sql
def process_item(self, item, spider):
defer = self.db_pool.runInteraction(self.insert_item, item)
defer.addErrback(self.handle_error, item)
return item
def insert_item(self, cursor, item):
cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pubdate'], item['origin_url'], item['article_id']))
def handle_error(self, error, spider):
print('=' * 10 + 'error' + '=' * 10)
print(error)
三:发送post请求
scrapy默认每次发送请求是get请求,如果要发送post请求,需要重写start_requests方法
import scrapy
class RrSpider(scrapy.Spider):
name = 'rr'
allowed_domains = ['renren.com']
start_urls = ['http://renren.com/']
# scrapy默认发送的是get请求,因为要登录发送post请求,所以重写start_requests方法
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
data = {'email': 'ginvip@qq.com', 'password': 'xxxxxxxx'}
# FormRequest方法可以post表单数据
request = scrapy.FormRequest(url, formdata = data, callback=self.parse_page)
yield request
def parse_page(self, response):
request = scrapy.Request(url = 'http://www.renren.com/875198389/profile', callback = self.parse_profile)
yield request
def parse_profile(self, response):
with open('profile.html', 'w', encoding='utf-8') as fp:
fp.write(response.text)
四:附录
4.1 urllib.parse模块使用
url.parse :定义了url的标准接口,实现url的各种抽取
parse模块的使用:url的解析,合并,编码,解码
1:urlparse()实现URL的识别和分段
url = 'https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog'
"""
url:待解析的url
scheme='':假如解析的url没有协议,可以设置默认的协议,如果url有协议,设置此参数无效
allow_fragments=True:是否忽略锚点,默认为True表示不忽略,为False表示忽略
"""
result = parse.urlparse(url=url,scheme='http',allow_fragments=True)
print(result)
print(result.scheme)
# (scheme='https', netloc='book.qidian.com', path='/info/1004608738', params='', query='wd=123&page=20', fragment='Catalog')
"""
scheme:表示协议
netloc:域名
path:路径
params:参数
query:查询条件,一般都是get请求的url
fragment:锚点,用于直接定位页
面的下拉位置,跳转到网页的指定位置
"""
2:urlunparse()可以实现URL的构造
url_parmas = ('https', 'book.qidian.com', '/info/1004608738', '', 'wd=123&page=20', 'Catalog')
# components:是一个可迭代对象,长度必须为6
result = parse.urlunparse(url_parmas)
print(result)
"""
https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog
"""
3:urljoin()传递一个基础链接,根据基础链接可以将某一个不完整的链接拼接为一个完整链接
base_url = 'https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog'
sub_url = '/info/100861102'
# 注意:sub_url的值前面必须要有一个/,如果没有/会将sub_url直接拼接到base_url的后面
full_url = parse.urljoin(base_url,sub_url)
print(full_url) # https://book.qidian.com/info/100861102
# 理解:将base_url中的scheme='https', netloc='book.qidian.com',后面的不要,然后与sub_url进行拼接
4:urlencode()将字典构形式的参数序列化为url编码后的字符串(常用来构造get请求和post请求的参数)k1=v1&k2=v2
parmas = {
'wd':'123',
'page':20
}
parmas_str = parse.urlencode(parmas)
print(parmas_str)
"""
page=20&wd=123
"""
parse_qs()将url编码格式的参数反序列化为字典类型
parmas_str = 'page=20&wd=123'
parmas = parse.parse_qs(parmas_str)
print(parmas)
"""
{'page': ['20'], 'wd': ['123']}
"""
5:quote()可以将中文转换为URL编码格式
word = '中国梦'
url = 'http://www.baidu.com/s?wd='+parse.quote(word)
print(parse.quote(word))
print(url)
"""
%E4%B8%AD%E5%9B%BD%E6%A2%A6
http://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%A2%A6
"""
unquote:可以将URL编码进行解码
url = 'http://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%A2%A6'
print(parse.unquote(url))
"""
http://www.baidu.com/s?wd=中国梦
"""
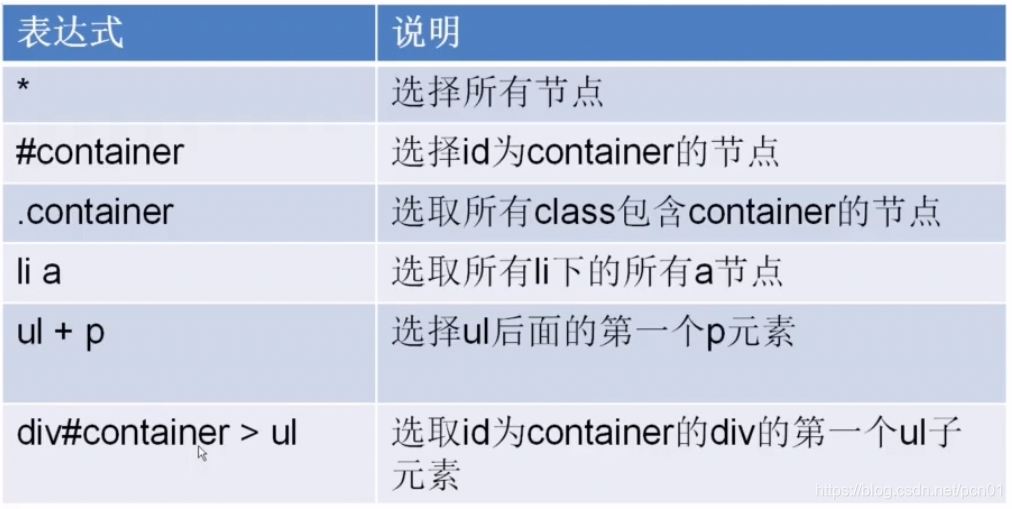
4.2 xpath的css选择器


class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
def parse(self, response):
post_nodes = response.css('#news_list .news_block')[:1]
for post_node in post_nodes:
image_url = post_node.css('.entry_summary a img::attr(href)').extract_first()
post_url = post_node.css('h2 a::attr(href)').extract_first()
yield scrapy.Request(url = parse.urljoin(response.url, post_url), meta = {'front_image_url': image_url}, callback = self.parse_detail)
# next url
next_url = response.css('div.pager a:last-child::text').extract_first()
if 'Next' in next_url:
next_url = response.css('div.pager a:last-child::attr(href)').extract_first()
yield scrapy.Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
# https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=661951
content_id = re.match('.*?(\d+)', response.url)
content_id = content_id.group(1)
if content_id:
title = response.css('#news_title a::text').extract_first()
create_date = response.css('#news_info .time::text').extract_first()
content = response.css('#news_content').extract_first()
tag_list = response.css('.news_tags a::text').extract()
tags = ','.join(tag_list)
json_url = parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(content_id))
html = requests.get(json_url)
data = html.json()
praise_num = data.get('DiggCount')
fav_nums = data.get('TotalView')
comment_nums = data.get('CommentCount')
pass
4.3 Scrapy的Request与Response
# Request源码
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
if not isinstance(priority, int):
raise TypeError("Request priority not an integer: %r" % priority)
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError('callback must be a callable, got %s' % type(callback).__name__)
if errback is not None and not callable(errback):
raise TypeError('errback must be a callable, got %s' % type(errback).__name__)
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
self._cb_kwargs = dict(cb_kwargs) if cb_kwargs else None
self.flags = [] if flags is None else list(flags)
.......................
Request对象:
Request 对象表示一个HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成Response 有请求才有响应
Request 对象在我们写爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有:
url (string) 这个request对象发送请求的url。
callback(callback) 在下载器下载完相应的数据后执行的回调函数。
method (string) 请求的方法。默认为GET方法,常用还有 POST ,注意是大写。
headers(dict) 请求头,对于一些固定的设置,放在 settings.py 中指定就可以了。对于那些非固定的,可以在发送请求的时候指定。
body(str或unicode) 请求体。如果unicode传递了a,那么它被编码为 str使用传递的编码(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个str(不会是unicode或None)。
cookie(dict或list) 请求cookie。这些可以以两种形式发送。
meta(dict) 比较常用。用于在不同的请求之间传递数据用的。
encoding 编码。默认的为utf-8,使用默认的就可以了。
priority(int) 此请求的优先级(默认为0)。调度器使用优先级来定义用于处理请求的顺序。具有较高优先级值的请求将较早执行。允许负值以指示相对低优先级。
dont_filter(boolean) 表示不由调度器过滤。在执行多次重复的请求的时候用得比较多, 默认为False。
errback(callback) 在发生错误的时候执行的函数。
Response对象:
Response 对象一般是由Scrapy给你自动构建的。因此开发者不需要关心如何创建Response对象,而是如何使用他。Response 对象有很多属性,可以用来提取数据的。主要有以下属性:
meta 从其他请求传过来的meta 属性,可以用来保持多个清求之向的数据连接。
encoding 返回当前字符串编码和解码的格式。
text 将返回来的数据为 unicode 字符串返回。
body 将返回来的数据作为 bytes 字符串返回。
xpath xapth迭代器。
css css迭代器。
发送POST靖求:
有吋候问想要在请求数据的吋候发送POST请求,那么这吋候需要使用Request的子类FormRequest 来实现。如果想要在爬虫一开始的时候就发送POST请求,那么需要在爬虫类中重写 start. requests(self) 方法,并且不再调用 start_urls里的 url。


















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









