 快速排序优化与性能对比
快速排序优化与性能对比







 本文深入探讨了快速排序的基本原理及其实现过程,详细解释了如何通过取随机数作为基准和采用三路快排来优化算法,避免时间复杂度退化。并通过一千万级数据的对比实验证明了优化后的快排性能显著提升。
本文深入探讨了快速排序的基本原理及其实现过程,详细解释了如何通过取随机数作为基准和采用三路快排来优化算法,避免时间复杂度退化。并通过一千万级数据的对比实验证明了优化后的快排性能显著提升。
一、什么是快排
快速排序是图灵奖得主 C. R. A. Hoare 于 1960 年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
利用分治法可将快速排序的分为三步:
1、在数据集之中,选择一个元素作为”基准”(pivot)。
2、所有小于”基准”的元素,都移到”基准”的左边;所有大于”基准”的元素,都移到”基准”的右边。这个操作称为分区 (partition) 操作,分区操作结束后,基准元素所处的位置就是最终排序后它的位置。
3、对”基准”左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
二、基本实现
2.1、基本思路
假设现在有以下待排序的数组:
| i -> 0 | 1 | 2 | 3 | 4 | 5 | j-> 6 |
|---|---|---|---|---|---|---|
| 7 | 8 | 9 | 1 | 6 | 2 | 9 |
上面的一栏表示索引,下面的一栏表示数值
1、首先,确定左索引指针为i = 0(之后简称为指针),右指针为j = 6,基数为base,首先可以确定基数为最左边的数,即base=7
2、排序开始时,j指针从右往左走,当指到小于等于基数的数时停下,即此时j=5;i指针从左往右走,找到大于等于基数的数时停下,即i=1
| 0 | i -> 1 | 2 | 3 | 4 | j-> 5 | 6 |
|---|---|---|---|---|---|---|
| 7 | 8 | 9 | 1 | 6 | 2 | 9 |
3、此时i,j两者的数值交换,即得如下
| 0 | i -> 1 | 2 | 3 | 4 | j-> 5 | 6 |
|---|---|---|---|---|---|---|
| 7 | 2 | 9 | 1 | 6 | 8 | 9 |
4、重复第2、3步,得
| 0 | 1 | i -> 2 | 3 | j->4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 7 | 2 | 6 | 1 | 9 | 8 | 9 |
5、i、j指针相遇
| 0 | 1 | 2 | i-> 3 <-j | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 7 | 2 | 6 | 1 | 9 | 8 | 9 |
6、i、j指针同时指向3索引,此时用i索引的位置去交换基准值
| 0 | 1 | 2 | i-> 3 <-j | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 1 | 2 | 6 | 7 | 9 | 8 | 9 |
就这样,第一次排序即完成了,此时索引3左边的值都小于等于7,右边的值都大于等于7
7、分治递归
完成了以上之后,将7左边的数视为“左数组”,右边的数视为“右数组”,重复调用1~7步,直到数组中只含一个数为止,终止递归调用
| 0 | 1 | 2 |
|---|---|---|
| 1 | 2 | 6 |
| 4 | 5 | 6 |
|---|---|---|
| 9 | 8 | 9 |
2.2、代码实现
public void sort(int[] array) {
int left = 0;
int right = array.length - 1;
quickSort(array, left, right);
}
private void quickSort(int[] array, int left, int right) {
// 递归终止条件
if (left >= right) {
return;
}
// 先进行第一部分排序,获取到已排序的分割索引
int index = partition1(array, left, right);
// 进行左右两个部分的排序
quickSort(array, left, index - 1);
quickSort(array, index + 1, right);
}
/*
* @Author ARong
* @Description 快排基础版本,选择left为基准,但是如果本身已经有序,那么时间复杂度退化为O(n)
* @Date 2019/11/27 1:32 下午
* @Param
* @return
**/
private int partition1(int[] array, int left, int right) {
// 定义基准
int base = array[left];
// 定义左右指针
int i = left, j = right;
while (i < j) {
// j向左寻找比基准小的数
while (i < j && array[j] >= base) {
j--;
}
// i向右寻找比基准大的数
while (i < j && array[i] <= base) {
i++;
}
// 交换i, j
swap(array, i, j);
}
// 交换left, i
swap(array, left, i);
return i;
}
private void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
三、优化快排
上一版的快排并不是最优化的快排,快排的平均复杂度O(nlogn)针对的是数据重复少且几乎无序的状态,有以下几个原因会让快排退化:
时间复杂度退化的原因
快排的平均时间复杂度为O(nlogn),这时在数据量较大且重复少、几乎无序的情况下。有两种情况会导致快排的时间复杂度退化到O(n^2):
1、数组近乎有序:
当数组近乎有序的时候,时间复杂度退化到O(n^2),因为每次都取第一个元素作为基准的话,会出现无法均匀分割数组,从而使分割的数组变成链表状:
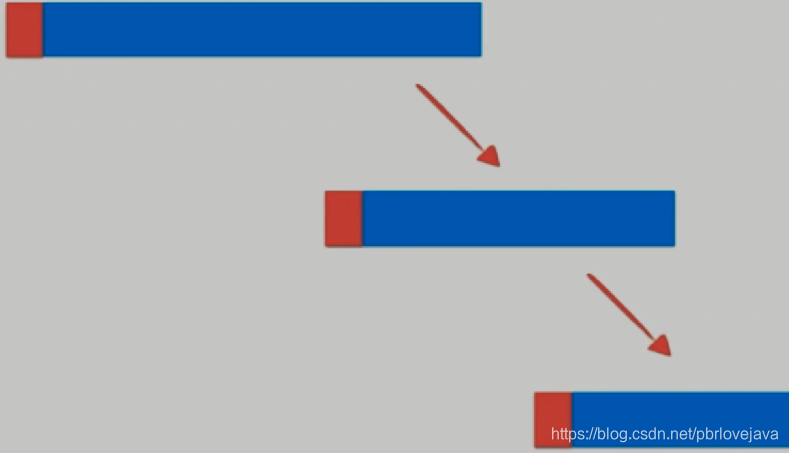
这时的解决办法是在数组中选取一个随机数作为基准,而不是取第一个数,这样子就能很好地避免在数组有序的情况下不能均匀切分数组的问题:
取随机数作为基准
public void sort(int[] array) {
int left = 0;
int right = array.length - 1;
quickSort(array, left, right);
}
private void quickSort(int[] array, int left, int right) {
// 递归终止条件
if (left >= right) {
return;
}
// 先进行第一部分排序,获取到已排序的分割索引
int index = partition2(array, left, right);
// 进行左右两个部分的排序
quickSort(array, left, index - 1);
quickSort(array, index + 1, right);
}
/*
* @Author ARong
* @Description 快排升级版本,随机选择基准,避免快排退化为O(n)
* @Date 2019/11/27 1:32 下午
* @Param
* @return
**/
private int partition2(int[] array, int left, int right) {
// 随机定义基准
int randomIndex = left + new Random().nextInt(1000) % (right - left + 1);
// 将随机基准和left交换
swap(array, left, randomIndex);
// 选取基准
int base = array[left];
// 定义左右指针
int i = left, j = right;
while (i < j) {
// j向左寻找比基准小的数
while (i < j && array[j] >= base) {
j--;
}
// i向右寻找比基准大的数
while (i < j && array[i] <= base) {
i++;
}
// 交换i, j
if (i < j) {
swap(array, i, j);
}
}
// 交换left, i
swap(array, left, i);
return i;
}
2、大数据量的数据重复:
当数组中的数据大量重复时,会出现分配不均匀问题切分不均匀问题,导致快排时间复杂度退化到O(n^2)

有一个思路非常常用,被称为三路快排,它的思想是将数组切分为三个部分:第一个部分小于baes,第二个部分等于base,第三个部分大于base,在下一次的迭代中,将小于base的部分继续排序,大于base的部分继续排序即可
三路快排
/**
* @Auther: ARong
* @Date: 2019/11/27 5:41 下午
* @Description: 三路快排,优化大量重复元素的情况
*/
public class _3_QuickSort3Ways {
@Test
public void fun() {
int[] array = new int[10];
for (int i = 0; i < array.length; i++) {
array[i] = new Random().nextInt(10);
}
System.out.println(Arrays.toString(array));
quickSort3Ways(array, 0, array.length - 1);
System.out.println(Arrays.toString(array));
}
public void quickSort3Ways(int[] array, int left, int right) {
if (left >= right) {
return;
}
// 获取随机索引并设置基准值
int randomIndex = left + new Random().nextInt(1000) % (right - left + 1);
swap(array, left, randomIndex);
int base = array[left];
// 定义i,j和cur
// [left + 1, i] < base
// [i + 1, cur - 1] == base
// [j, right] > base
int i = left, j = right + 1, cur = left + 1;
while (cur < j) {
if (i < j && array[cur] < base) {
swap(array, i + 1, cur);
i++;
cur++;
} else if (i < j && array[cur] > base) {
swap(array, cur, j - 1);
j--;
} else if (i < j && array[cur] == base) {
cur++;
}
}
swap(array, left, i);
// 划分两个子数组
quickSort3Ways(array, left, i - 1);
quickSort3Ways(array, j, right);
}
private void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
四、性能对比
先用一千万个范围在0~1000的数组进行排序对比普通快排和三路快排的速度:
public static void main(String[] args) {
//生成数据量
int n = 10000000;
int[] a = new int[n];
//取值区间
int k = 1000;
for (int i = 0; i < n; i++) {
a[i] = (int) (Math.random() * k);
}
long beginTime = new Date().getTime();
QuickSortNormal.quickSort(a, 0, a.length - 1);
long endTime = new Date().getTime();
System.out.println("用时:" + (endTime - beginTime) + "毫秒"); quickSort(a, 0, a.length - 1);
}
普通快排

三路快排

从实验结果可以看出,三路快排在千万级大重复数据量的情况下仍能在1s内进行排序,而普通快排花了27s,性能相差有27倍之多.


















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











