




 Apache Kafka作为一个开源分布式事件流处理平台,被广泛应用于高性能数据管道、流分析与关键任务应用。本文概览了Kafka的核心特性,包括高吞吐量、可扩展性、持久化存储及高可用性,阐述了其生态系统、为何选择Kafka的原因,以及Kafka的体系结构,包括消息、主题、分区等概念。进一步探讨了Kafka的通信模型与协议,强调其灵活的可靠性保障机制,特别关注于集群架构与控制器角色。
Apache Kafka作为一个开源分布式事件流处理平台,被广泛应用于高性能数据管道、流分析与关键任务应用。本文概览了Kafka的核心特性,包括高吞吐量、可扩展性、持久化存储及高可用性,阐述了其生态系统、为何选择Kafka的原因,以及Kafka的体系结构,包括消息、主题、分区等概念。进一步探讨了Kafka的通信模型与协议,强调其灵活的可靠性保障机制,特别关注于集群架构与控制器角色。
前段时间leader让我选择一个东西深入研究下,我选择了Kafka,学习中以书籍为主,也在网上找了很多参考文献,其实Kafka主要就是网络通行和数据存储,更像是一个数据库,客户端的行为就是提交数据和获取数据,经过了一个月的陆陆续续的学历和文档整理,这次做一次整合怪,把总体的学习分享出来。下一步准备抽时间研究kafka源码。内容非常滴多,有兴趣的同学可以收藏起来慢慢看。
一 kafka摘要
Kafka摘要部分主要以摘取官方描述为主。主要包含了Kafka的设计定位,核心能力,生态以及Kafka的体系结构介绍,帮助读者对Kafka有一个总体的了解。
1.1 Kafka简介
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
--摘自Kafka官方
1.1.1 核心特性
1 HIGH THROUGHPUT(高吞吐量)
Deliver messages at network limited throughput using a cluster of machines with latencies as low as 2ms.
2 SCALABLE(可扩展)
Scale production clusters up to a thousand brokers, trillions of messages per day, petabytes of data, hundreds of thousands of partitions. Elastically expand and contract storage and processing.
3 PERMANENT STORAGE(持久化)
Store streams of data safely in a distributed, durable, fault-tolerant cluster.
4 HIGH AVAILABILITY(高可用)
Stretch clusters efficiently over availability zones or connect separate clusters across geographic regions.
1.1.2 Kafka生态
1 BUILT-IN STREAM PROCESSING
Process streams of events with joins, aggregations, filters, transformations, and more, using event-time and exactly-once processing.
2 CONNECT TO ALMOST ANYTHING
Kafka’s out-of-the-box Connect interface integrates with hundreds of event sources and event sinks including Postgres, JMS, Elasticsearch, AWS S3, and more.
3 CLIENT LIBRARIES
Read, write, and process streams of events in a vast array of programming languages.
4 LARGE ECOSYSTEM OPEN SOURCE TOOLS
Large ecosystem of open source tools: Leverage a vast array of community-driven tooling.
1.1.3 为什么是Kafka
1 MISSION CRITICAL(关键任务)
Support mission-critical use cases with guaranteed ordering, zero message loss, and efficient exactly-once processing.
2 TRUSTED BY THOUSANDS OF ORGS
Thousands of organizations use Kafka, from internet giants to car manufacturers to stock exchanges. More than 5 million unique lifetime downloads.
3 VAST USER COMMUNITY(强大的社区)
Kafka is one of the five most active projects of the Apache Software Foundation, with hundreds of meetups around the world.
4 RICH ONLINE RESOURCES
Rich documentation, online training, guided tutorials, videos, sample projects, Stack Overflow, etc.
1.2 Kafka体系结构
kafka的整体结构如下图,主要的元素包括消息,批次,主题,分区,生产者,消费者,偏移量,broker,集群以及保存Kafka元数据的zookeeper等。以下对他们分别做介绍

各个组件的官方介绍可参考https://kafka.apache.org/intro
1.2.1 消息和批次
Kafka的数据单元被称为消息,类似于数据库里的一条记录。消息可以有个可选的元数据也就是键,通过key可以用于控制消息落在哪一个分区(一般用在需要保证消费顺序时),或者业务上对消息进行标识等。为了提高效率,消息被分批次写入Kafka,批次就是一组消息,这些消息属于同一主题和分区。如果每 个消息都单独穿行于网络,会导致大的网络开销,把消息分成批次传输可以减少网络开销。不过,这要在时间延迟和吞吐量之间作出权衡:
1.2.2 主题和分区
Kaflca 的消息通过主题进行分类。主题就好比数据库的表,或者文件系统里的文件夹。主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。下图所示的主题有4个分区,消息被追加写入到每个分区的尾部。 Kafka 通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说, 一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。

1.2.3 生产者,消费,偏移量
Kaflca 的客户端就是 Kaflea 系统的用户,它们被分为两种基本类型 生产者和消费者。即使是Kafka管理客户端API内部也是集成了生产者和消费者组件。
生产者用于创建消息。一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为消息的键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
消费者读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。
偏移量属于一种元数据(属于消费者组和分区共同的元数据),它是个不断递增的整数值,在创建消息时, Kafka 会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的悄息偏移量保存Zookeeper(老版本)或者Kafka(新版本)上,这样当消费者关闭或重启的时候,它的读取状态不会丢失。
消费者是消费者组的一部分,会有一个或多个消费者共同读取一个主题,Kafka在同一个消费者组中保证每个分区只能被一个消费者使用 。下图所示的消费者组中,两个消费者各自读取一个分区,另外一个消费者读取其他两个分区。而不会出现多个消费者读取同一个分区的情况,消费者与分区之间的映射通常被称为消费者对分区的所有权关系,通过这种方式,消费者可以消费包含大量消息的主题。而且,如果 个消费者失效,群组里的其他消费者可以接管失效悄费者的工作。

1.2.4 broker和集群
一个独立的 Kafka 服务器被称为broker, broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征(顺序IO的读写速度其实很快),单个 broker 可以轻松处理数千个分区以及每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有一个broker同时充当了集群控制器controller的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker以及监控broker.。在集群中,一个分区从属于一个broker, 这个broker被称为这个分区的首领。一个分区可以分配给多个 broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个 broker 失效,其他 broker 可以接管领导权。不过,相关的消费者和生产者都要重新连接到新的首领。

controller选举过程
ZooKeeper 模式下的 controller的选举和掉线检测
Kafka 在早期版本(如 2.x 和 3.x 默认)使用 ZooKeeper 进行控制面协调,ZooKeeper 的 Watch 机制是实现 controller 掉线感知的核心
📌 控制器选举机制
所有 broker 启动时都会尝试在 ZooKeeper 中创建
/controller临时节点。只有一个 broker 能成功创建这个节点,成功者就成为 controller。
失败者会监听这个controller节点
这个节点是ephemeral(临时)节点,绑定 controller 的 ZooKeeper 会话。
⚠️ controller 掉线时的发现过程
controller 宕机或与 ZooKeeper 断开连接,ZooKeeper 会话失效;
/controller临时节点自动被 ZooKeeper 删除;所有 broker 监听了这个节点变化,会立即收到 Watcher 触发通知;
收到通知的 broker 会尝试竞争成为新的 controller;
成功创建
/controller节点的 broker 成为新的 controller。
KRaft 模式下的 controller 选举和掉线检测
从 Kafka 2.8 开始引入的 KRaft 模式,在 Kafka 3.4+ 逐步成为推荐模式,4开始完全移除了 ZooKeeper。
📌 控制器选举机制
KRaft 使用Raft 共识协议选举 controller;
集群中一部分节点是 controller quorum(控制器仲裁节点),例如 3 个节点中选出一个 leader。
⚠️ controller 掉线时的发现过程
当前的 controller(Raft leader)宕机;
剩余的 controller quorum 节点通过 Raft 协议检测到 leader 超时未响应(如心跳超时);
发起新的leader选举;
新leader上任并通知其他 broker;
1.2.5 多集群
随着 Kafka 部署数量的增加,往往会出现数据类型分离,安全需求隔离,多数据中心(灾难恢复)等需求。最好的建议是使用多个集群。
如果使用多个数据中心,就需要在它们之间复制消息。这样,在线应用程序才可以访问到多个姑点的用户活动信息。例如,如果一个用户修改了他的资料信息,不管从哪个数据中心都应该能看到这些改动。或者多个站点的监控数据可以被聚集到一个部署了分析程序和告警系统的中心位置。不过, Kafka 的消息复制机制只能在单个集群里进行,不能在多个集群之间进行。
Kafka 提供了 个叫作 Mirror Maker 的工具,可以用它来实现集群间的消息复制。Mirror Maker 的核心组件包含了一个生产者和一个消费者,两者之间通过一个队列相连。消费者从一个集群读取消息,生产者把消息发送到另一个集群上。下图展示了一个使MirrorMaker 的例子,两个“本地”集群的消息被聚集到一个“聚合”集群上,然后将该集群复制到其他数据中心。不过,这种方式在创建复杂的数据管道方面显得有点力不从心

。
1.3 Kafka官方及社区资源
官网:https://kafka.apache.org
GitHub:https://github.com/apache/kafka
Kafka 开发者邮件组社区:dev@kafka.apache.org
二 kafka通信
Kafka作为一个事件流平台,本质上就是提供了客户端往Kafka提交事件流(称为生产者客户端)和读取事件流(称为消费者客户端)的能力。这样便存在客户端和Kafka通信的问题,本章节讲解Kafka的通信部分的设计,包括Kafka的通信模型,协议以及流程梳理等。
2.1 Kafka通信模型
关于Kafka的通信模型,其实我早期找了很多资料,看了很多别人画的流程图,但是发现他们的流程图或者架构图理解起来都有冲突。直到后面我在啃完Kafka源码后发现他们的流程图和架构图都多多少少有点问题,不得已根据Kafka源码自己画了个消息流转图,但是我并不太擅长画图,可能比较丑或者不好理解的地方欢迎多指出来让我改进。
2.1.1 Kafka的主要网络组件介绍
KSelector
KSelector是kafka在java nio的selector上的一个增强封装,他其实类名也是叫Selector,只不过代码中为了和java nio的Selector类区分开,会给他取个别名,也就是KSelector,Kselector自己封装了一些主动拉取,读取请求,发送等方法,并且维护了一些读写缓冲区对性能进行优化,其实现监听的核心仍然是内置的java nio Selector
Acceptor
一个Acceptor本质上就是一个单独的线程(继承了AbstractServerThread类),一个kafka网络监听端口只会有一个Acceptor,用于接受网络请求并且转交给processor,他内置了一个java nio的Selector对象nioSelector用于监听网络请求的ACCEPT事件。
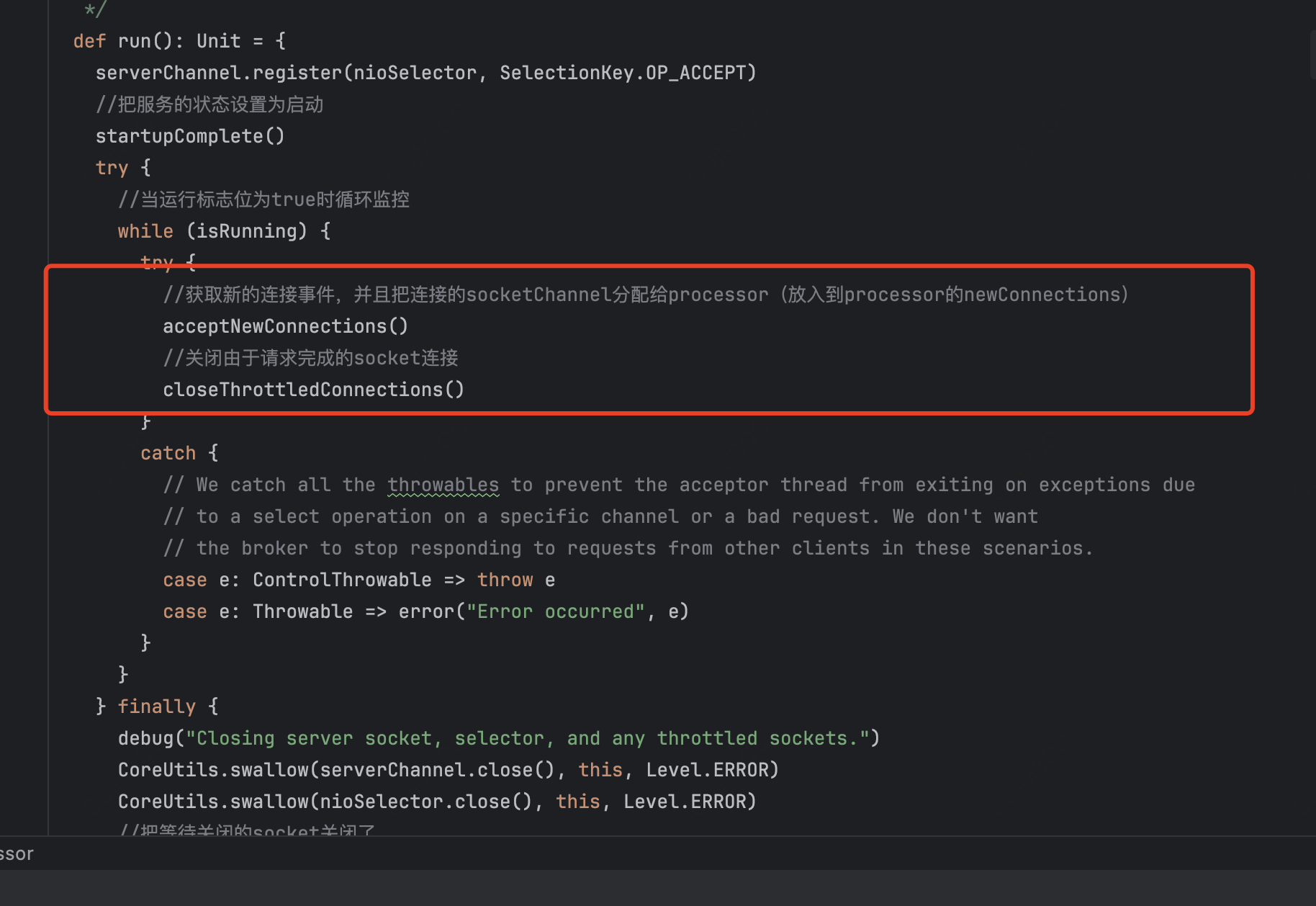
他的run方法会把serverChannel的ACCEPT事件注册到自己的nioSelector中并设置一些启动标志位,然后再在while循环中轮询地获取连接事件并且移交给Processor,同时也会关闭由于请求完成的socket连接。
Processor
Processor本质上也是一个线程(继承AbstractServerThread),他负责处理Acceptor给过来的请求,对请求进行响应并且负责请求的整个生命周期的流转控制,最终调用handler api进行对应的请求处理,可以理解为网络上的通用逻辑基本都是在processor做的。
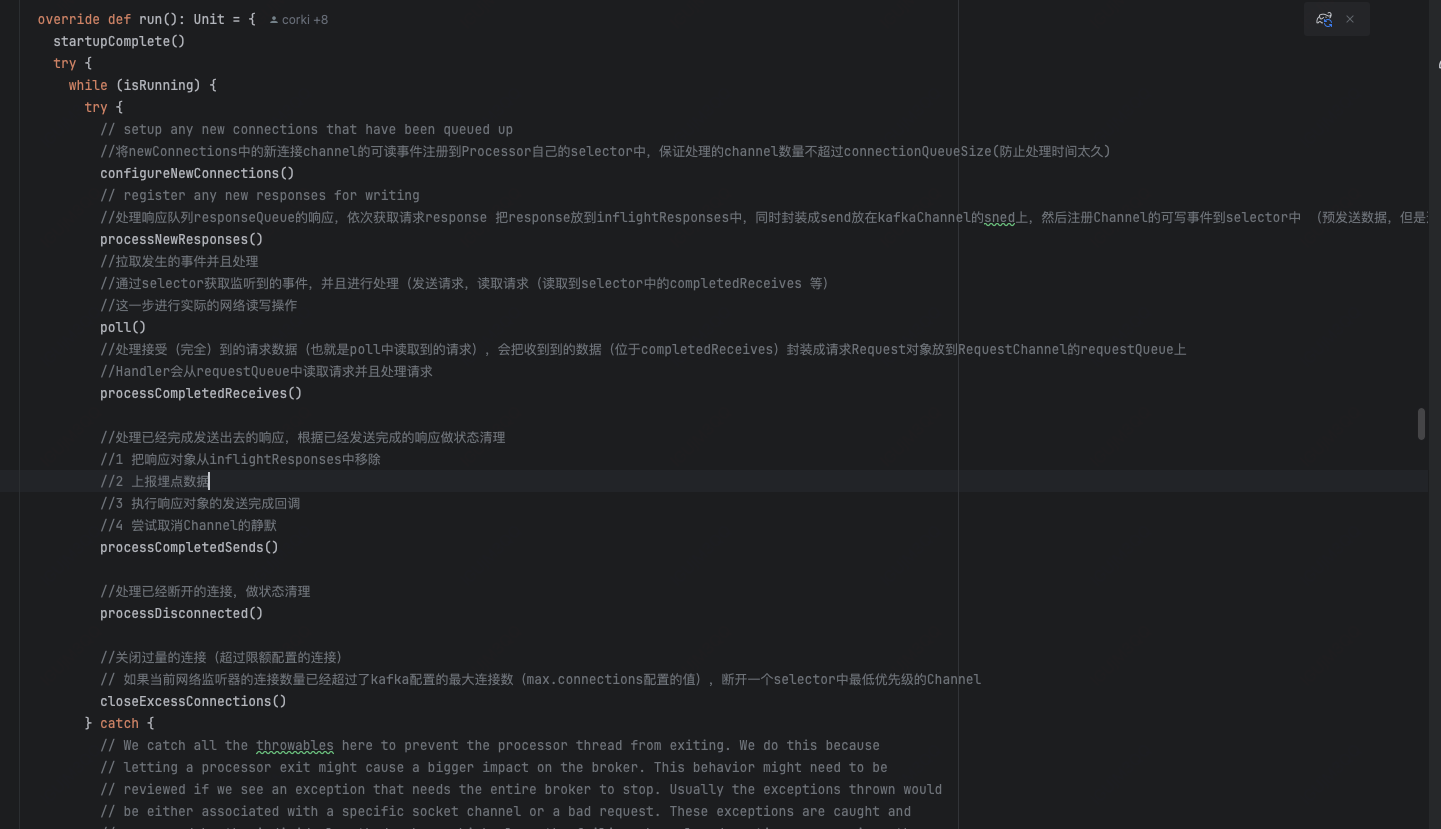
broker内部可以有多个processor(可以通过num.network.threads数来调整),可以提高并发量,processor有一个内部的KSelector(kafka在nio的selector上封装的一个selector),把acceptor给过来的新连接channel的可读事件注册到Processor自己的selector中,通过监听事件来进行流转和处理,他也是在run方法中循环地进行请求流转,具体包括下面7个工作内容。
1 将Acceptor给过来的已建立的连接的channel的可读事件注册到自己的selector中:
2 处理响应队列的响应,把队列里面的响应放到发送缓冲区上,然后注册对应Channel的可写事件到selector中 (预发送数据,但是还没有真正发送到到网络中)
3 拉取selector监听到的事件并且处理,可读就发送,可写就生成请求对象
4 处理接受到的请求数据
5 处理已经完成发送出去的响应,根据已经发送完成的响应做状态清理
6 处理已经断开的连接,做状态清理
7 关闭过量的连接(超过限额配置的连接)
Handler
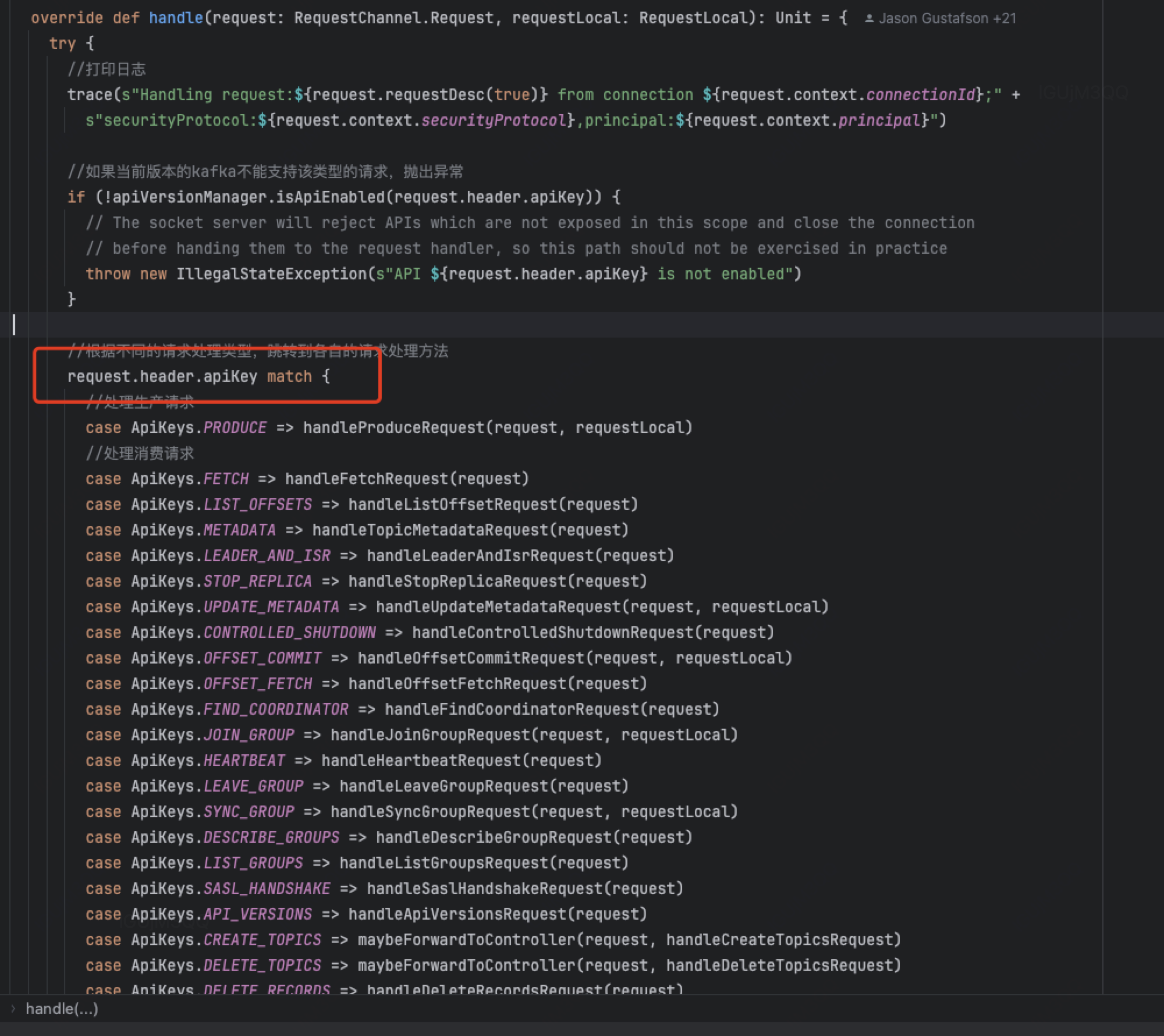
handler(KafkaRequestHandler)是真正处理各类请求的对象,KafkaRequestHandler本质是一个Runnable实例,其run方法是不断(while)在请求队列(由processor放请求)中获取请求并处理(具体是使用他的KafkaApis),他的业务处理代码比较朴实无华,通过Switch case判断请求类型并做处理
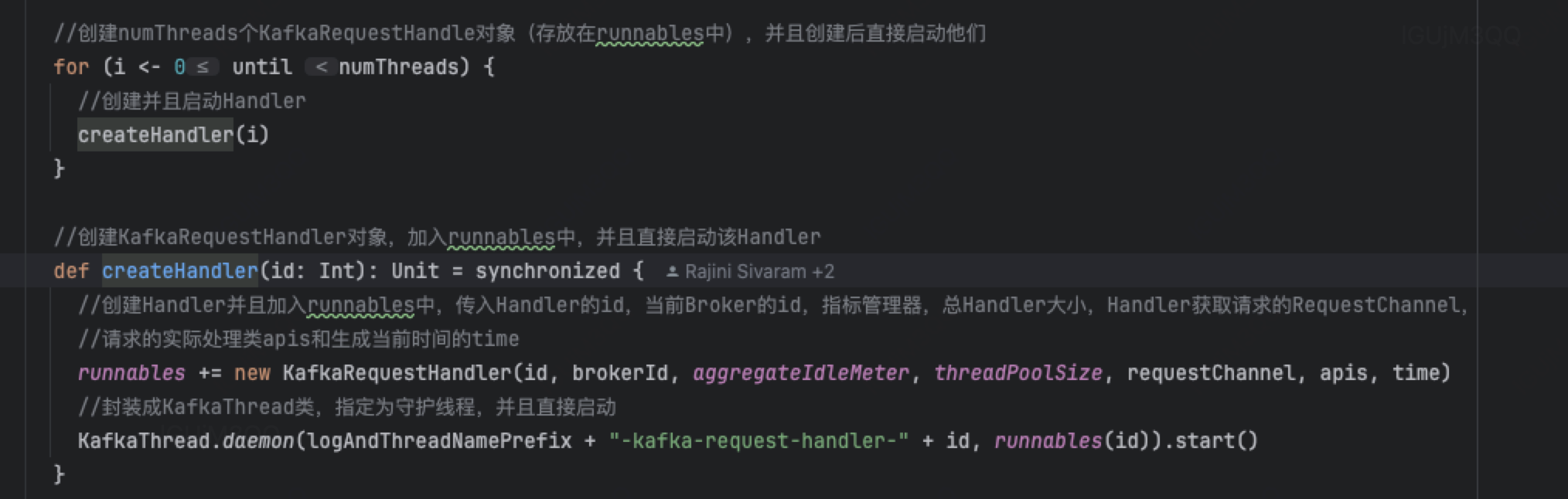
KafkaRequestHandlerPool中会使用KafkaRequestHandler创建并启动若干个(可以通过num.io.threads指定)新的线程,每个Handler都会抢占式地源源不断地在processor的RequestChannel成员requestChannel中获取请求处理,(各个processor用的是同一个requestChannel),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2281
2281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









