



数据简介
数据风险暴露变量作为量化企业数据安全管理水平的核心指标,是衡量上市公司在数字化转型进程中数据治理能力与风险防控实力的关键标尺。随着《中华人民共和国数据安全法》《个人信息保护法》等法规的密集出台,数据风险已成为影响企业持续经营的重要因素,该变量通过文本挖掘技术将企业数据风险相关的定性信息转化为可量化的定量指标,有效填补“数据风险识别—风险程度度量—治理效果评估”分析链条中的数据空白,为监管部门完善数据安全监管政策、高校开展数据治理研究、投资者评估企业运营风险提供权威可靠的数据支撑。
本数据核心来源为2010-2024年中国A股上市公司年度报告中“管理层讨论与分析(MD&A)”部分的文本信息。数据构建过程严格遵循“基础关键词界定—语义拓展—精准匹配—清洗校验”的标准化流程:首先参考《工业和信息化领域数据安全风险信息报送与共享工作指引(2021)》(试行)及和国家互联网信息办公室印发的《国家网络安全事件应急预案(2017)》中对数据风险和网络风险的定义和具体分类,考虑到企业应用数字技术类型的差异还包括了各种数字技术的具体风险,界定了数据泄露、数据窜改、数据滥用、违规传输四大类基础关键词;随后基于Word2vec模型对基础关键词进行语义拓展,形成包含基础词与拓展词的完整关键词词典;再通过在MD&A文本中抓取相关内容并统计词频,最终以词频值作为数据风险暴露变量的核心度量,完整呈现2010-2024年各上市公司数据风险暴露的时序特征。
数据信息
- 数据格式:excel
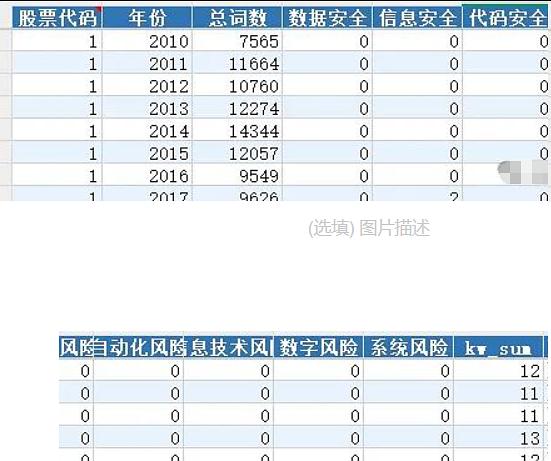
- 数据字段:股票代码、年份、kw_sum、总词数
注:剩余“数据风险暴露”关键词已整合到txt文档中(如下图)

数据截图
参考文献
[1]陆瑶,施函青,周欣怡.中国企业数字技术风险暴露对企业价值的影响——来自大语言模型的文本分析证据[J].经济研究,2025,60(02):73-89.
【下载→
方式一(推荐):主页 ↓个人↓简介
方式二:数据下载地址汇总_-优快云博客

















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









