



参考《数量经济技术经济研究》中钞小静(2024)、陈强(2024)等人的做法,从OpenCelliD(世界上最大的开放式手机基站数据库)中爬取全球5000万余条基站信息
筛选得到中国的基站信息,获取中国2G、3G、4G、5G基站的原始数据。覆盖年份为2006-2024年,总计183万余条,是具有价值的研究资料

一、数据介绍
数据名称:中国手机基站数据
数据范围:中国
时间范围:2006-2024年
样本数量:183.6万条
数据来源:OpenCelliD
数据整理:根据OpenCelliD历史数据整理
二、指标定义
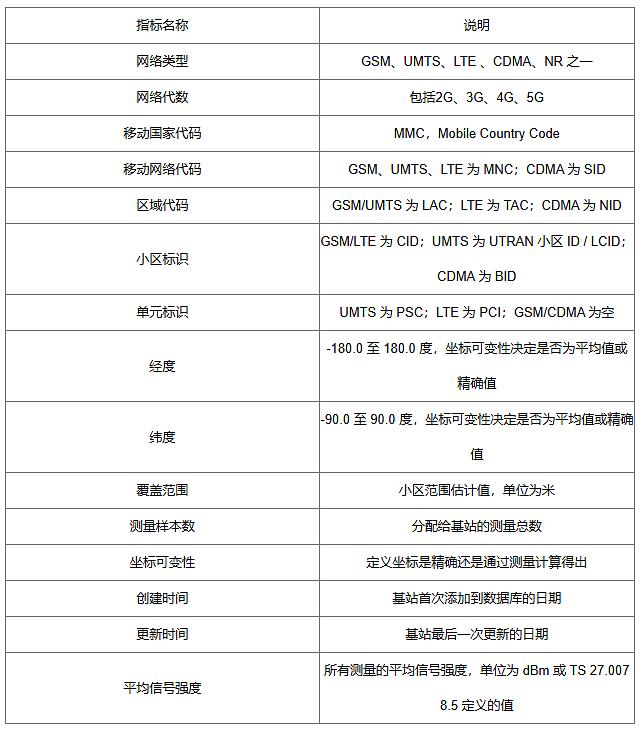
三、参考文献
[1]钞小静,薛志欣.新型信息基础设施对中国经济韧性的影响——来自中国城市的经验证据[J].经济学动态,2023,(08):44-62.
[2]陈强远,崔雨阳,蔡卫星.数字政府建设与城市治理质量:来自公共安全部门的证据[J].数量经济技术经济研究,2024,41(11):132-154.
[3]钞小静,廉园梅,元茹静,等.数字基础设施建设与产业链韧性——基于产业链恢复能力数据的实证分析[J].数量经济技术经济研究,2024,41(11):112-131.
[4]Ackermann, K., Awaworyi Churchill, S., & Smyth, R. (2021). Mobile phone coverage and violent conflflict. Journal of Economic Behavior & Organization, 188, 269–287.
四、数据概览
中国手机基站数据-分年份数据
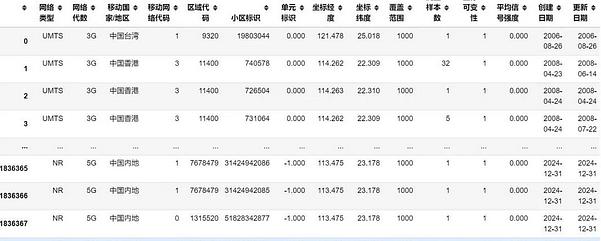
中国手机基站数据-数据概览
【下载→
方式一(推荐):主页↓个人↓简介
经管数据库-优快云博客
方式二:数据下载地址汇总-优快云博客

















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









