





目录
架构
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
接下来,我们来介绍一下 Flink 架构中的重要方面。
处理有界与无界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
- 无界流:
- 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流:
- 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
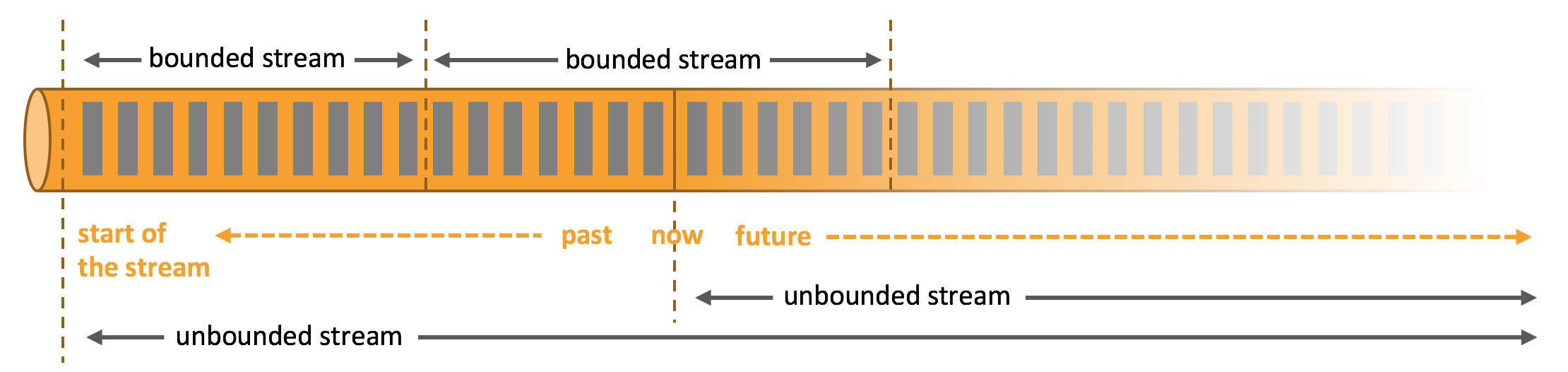
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
举个例子通俗理解:
- 无界流:假如要监听mysql的数据变化去做后续业务处理,那么其中mysql的数据变化,是一个没有开始结束的过程,会一直持续的新增、修改、删除操作,因此这种操作的可以被理解为是一种无界流的数据
- 无界流:假如商品有个活动页,规定了时间开始和结束,时间外不会再有数据进来,这样的数据是一种有限的数据,可以进行批量处理,也叫做批处理数据,有界流数据通常用于离线处理,对数据进行聚合、分组、统计等应用。
部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
Flink还提供了管理界面对Flink中提交的任务进行管理,也可以通过Flink提供的REST API嵌入到应用的业务中快速集成。
运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink 用户报告了其生产环境中一些令人印象深刻的扩展性数字
- 处理每天处理数万亿的事件,
- 应用维护几TB大小的状态,
- 应用在数千个内核上运行。
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
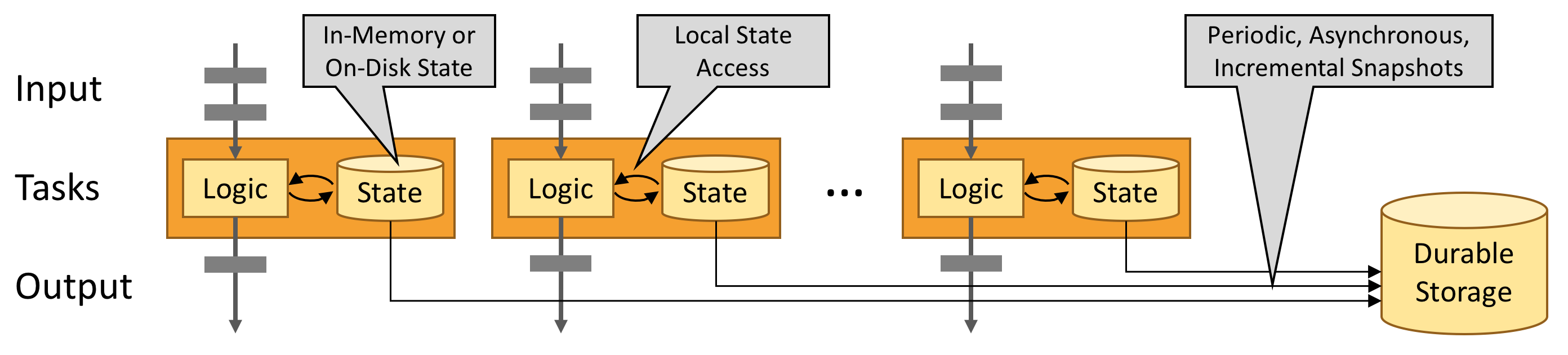
注意:Flink的初始化以及运行时,一定要根据当前服务器内存进行参数配置,避免占用大量内存,导致服务器宕机情况发生。
流应用
Flink 自底向上在不同的抽象级别提供了多种 API,并且针对常见的使用场景开发了专用的扩展库。在这里,将介绍 Flink 所提供的这些简单易用、易于表达的 API 和库,可以进行一个简单的基础入门。
流处理应用的基本组件
可以由流处理框架构建和执行的应用程序类型是由框架对 流、状态、时间 的支持程度来决定的
流
(数据)流是流处理的基本要素。然而,流也拥有着多种特征。这些特征决定了流如何以及何时被处理。Flink 是一个能够处理任何类型数据流的强大处理框架。
- 有界 和 无界 的数据流:流可以是无界的;也可以是有界的,例如固定大小的数据集。Flink 在无界的数据流处理上拥有诸多功能强大的特性,同时也针对有界的数据流开发了专用的高效算子。
- 实时 和 历史记录 的数据流:所有的数据都是以流的方式产生,但用户通常会使用两种截然不同的方法处理数据。或是在数据生成时进行实时的处理;亦或是先将数据流持久化到存储系统中——例如文件系统或对象存储,然后再进行批处理。Flink 的应用能够同时支持处理实时以及历史记录数据流。
状态
只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的。任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3268
3268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









