



 本文通过实例演示了如何使用Python的pandas库中的groupby函数进行数据分组、聚合操作,适合初学者理解其用法。
本文通过实例演示了如何使用Python的pandas库中的groupby函数进行数据分组、聚合操作,适合初学者理解其用法。
groupby函数是Python中pandas库中的一个重要函数,用于对数据进行分组。它可以将一个大的数据集划分为更小的组,以便进行聚合、过滤或转换等操作。
为了正清楚groupby 函数,这里举几个简单的小例子,
案例1,对数据进行分组
import pandas as pd
import numpy as np
#准备数据
df=pd.DataFrame(data={'sex':np.random.randint(0,2,size=300),
'class':np.random.randint(1,9,size=300),
'python':np.random.randint(0,151,size=300),
'keras':np.random.randint(0,151,size=300),
'Tensorflow':np.random.randint(0,151,size=300),
'java':np.random.randint(0,151,size=300),
'c++':np.random.randint(0,151,size=300)
})
#设置sex为索引列
df['sex']=df['sex'].map({0:'男', 1:'女'})
#按照sex进行单分组,这里按照sex分组,就会被分层两组
g=df.groupby(by='sex') #单分组
运行结果:
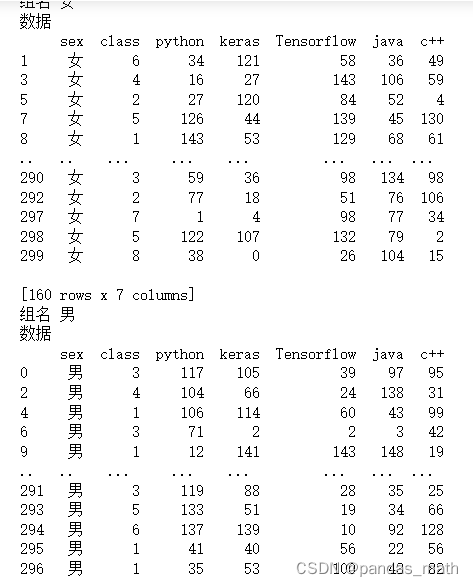
#按照sex 和class进行分组,就会被分成女,8个组,男8个组
g=df.groupby(by=['sex','class'])
for name,data in g:
print("组名",name)
print('数据',data)
#输出结果;
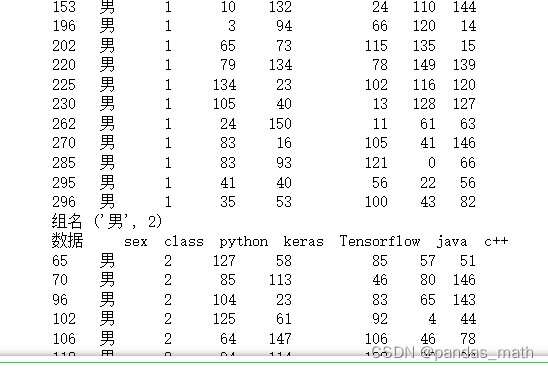
#还可进行组合后的计算
#数据求和
g=df.groupby(by=['sex','class'])["python"].sum()
结果:
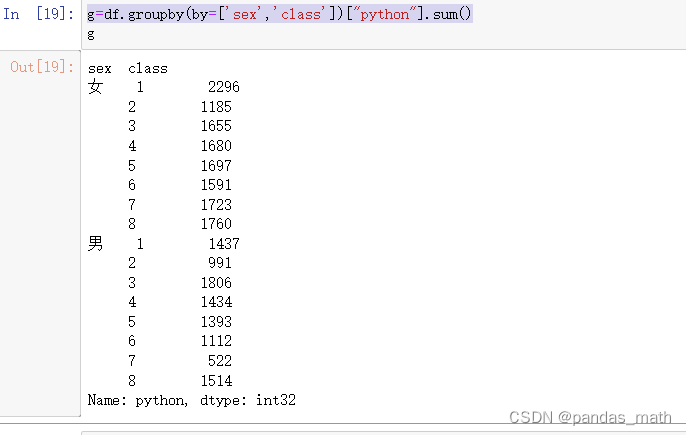
也可是是计算均值
g=df.groupby(by=['sex','class'])["python"].mean()
通过多次学习,相信对groupby函数会有更多的认识。

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









