



信念空间规划中合适距离函数的重要性
扎卡里·利特菲尔德、德米特里·克利缅科、汉娜·库尔尼亚瓦蒂和科斯塔斯·E·贝克里斯
1 引言
不确定性无处不在,因为感知永远不会完美,执行器存在误差,且机器人的 工作环境通常是未知的。由于这些不完整的信息和误差,机器人的精确状态 永远无法被完全知晓。因此,许多方法不再在状态空间中寻找最优解,而是 将机器人状态的不确定性表示为概率分布,并在状态上的分布集合(称为信 念空间[12, 24, 25, 31])中进行规划。由于信念空间的大小随状态空间维度 呈双指数增长,因此在信念空间中的规划计算复杂度远高于在状态空间中的 规划。然而,最近的研究进展表明,信念空间中的运动规划正逐渐适用于许 多中等规模的问题[1, 6, 9, 32]。
背景:有趣的是,信念空间规划的进展是通过与确定性情况下使用的类似工具实现的。 特别是,这一进展是通过对一小部分代表性信念进行采样,并在信念空间中规划而实现的 仅针对这一小部分采样的信念。事实上,许多信念空间规划中的方法(例如 [3,18, 25])是确定性情况下基于采样方法的扩展,例如 PRM、RRT、 PRM∗ 和 RRG[4, 7]。这些方法通常将信念限制为由高斯参数表示,或考虑 状态的最大似然估计。
最近的研究表明,在确定性情况下,即使没有导向函数,也能实现渐近 最优性[15, 20],,这有望为将基于采样的规划器更直接地扩展到信念空间规 划提供可能。无导向函数的确定性规划与信念空间规划之间的相似性表明, 对确定性运动规划至关重要的性质,对于信念空间运动规划同样可能至关重 要。
与确定性情况下的基于采样方法类似,许多用于信念空间规划的等效方法依 赖于信念之间的距离函数来部分指导其采样和剪枝操作[8, 12, 29]。多种距离函 数都可能被使用,并且在信念空间规划中可能产生显著不同的影响。然而,在关 于信念空间规划的相关文献中,不同距离函数的有效性尚未得到研究。
本文重点研究在信念空间运动规划中常用的距离函数的适用性。常用的 函数,例如L1距离和库尔贝克‐莱布勒散度KL散度,通常忽略了状态空间中 的底层距离。因此,在状态空间中彼此接近但支撑集不重叠的两个信念,其 距离将与支撑集相距很远的两个信念相同。图1说明了这一问题。如果信念 的支撑集是无界的,则上述问题会有所缓解,但仍存在。虽然沃瑟斯坦距离 (即推土机距离,EMD)能够缓解上述问题,但在相关文献中却很少被使用 [11, 14]。本文对这些度量在两类信念空间规划中的影响进行了比较研究, 即非完全可观测马尔可夫决策过程(NOMDP)和部分可观测马尔可夫决策过 程(POMDP)。

图1 L1和KL距离问题的示意图。假设状态空间X为一维自然数,且距离d X(x, x′ ) = |x −x′|。则L1距离 D L1(b1 ,b2) = D L1(b1 ,b3),KL距离DKL(b1 ,b2) =D KL (b1 ,b3),以及EMD距离D W(b1 ,b2) <DW(b1 ,b3)
NOMDP评估
NOMDP 是信念空间规划中最简单的一类问题,属于在 不确定性下进行规划的挑战,其中没有任何观测可用。尽管其较为简单, NOMDP 仍常被用作解决复杂不确定性下规划问题的中间方案[10]。这类 问题的简单性使我们能够在各种复杂的运动规划问题上比较该度量,而这些 问题在部分可观测的情况下仍然难以解决。为了解决NOMDPs,这
信念空间规划中合适距离函数的重要性 685
本文利用了确定性运动规划中的最新成果,这些成果表明,可以通过不需要 导向函数的基于采样方法来计算渐近最优解[7]。这些方法被扩展用于求解 非完全可观测马尔可夫决策过程问题。与需要导向函数的方法相比,此类扩 展更为简单,因为在信念空间中计算一个良好的导向函数是相当困难的。仿 真结果表明,随着非完全可观测马尔可夫决策过程问题复杂性的增加,不同 距离函数在有效性上的差异变得十分显著。事实上,在维度超过4的状态空 间中,仅通过将L1或KL散度替换为EMD,求解问题的速度便大幅提高,问 题也从几乎无法求解转变为可求解。
POMDP评估
在我们的比较研究中,第二类问题是部分可观测马尔可 夫决策过程(POMDP)。为了解决POMDP问题,本文采用了蒙特卡洛值 迭代(MCVI)[2],这是一种专为具有连续状态空间的问题设计的离线 POMDP求解器。由于现有POMDP求解器在处理大规模动作空间问题上的 局限性,本文仅在POMDP框架下评估性能时,将各种度量应用于一个二维 导航问题。尽管这一限制意味着我们尚无法展示EMD在POMDP中的全部潜 力,但初步结果表明,EMD可以显著减少基于采样的POMDP求解器达到特 定解的质量所需的信念空间样本数量。
Overall Contributions
本比较研究的结果表明,EMD 比 L1 和 KL 更 为合适,尽管其计算成本可能更高,但能够显著提升信念空间规划的性能。 本文还描述了高效计算 EMD 的若干步骤。此外,本文表明 EMD 能够将状 态空间中代价函数的利普希茨连续性保持到信念空间中期望代价的利普希茨 连续性。这一性质非常有用,因为在若干渐进最优运动规划方法(包括无转 向函数[15, 20],的信念空间规划方法[12, 13])的收敛性分析中均使用了该性 质。
2 比较研究的问题设置
POMDP 是一种在离散时间下进行不确定性规划的数学原理框架。形式上, POMDP 被定义为一个元组 〈S, A, O, T, Z , R, b0, γ〉,其中 S 是状态集合, A 是动作集合,O 是观测集合。符号 T 表示运动不确定性,并被定义为条件 概率函数 T (s, a, s′) = P(s′|s, a),其中 s, s′ ∈S 且 a ∈A。符号 Z 表示感知 不确定性,并被定义为条件概率函数 Z (s′, a, o) = P(o|s′, a),其中 s′ ∈S, a ∈A,且 o ∈O。在每一步中,POMDP智能体处于状态 s ∈ S,执行动作 a ∈A,从 s 转移到终止状态 s′ ∈ S,感知到一个观测 o ∈ O,并因在状态 s 执行动作 a 而获得奖励 R(s, a)。然而,POMDP智能体从不知道其确切状 态,而是基于对状态的分布(称为信念)进行推理。在每一步,该智能体的
686 Z. 利特菲尔德 等人
信念估计会根据其刚刚执行的动作和感知到的观测进行更新。智能体的目标 是选择一个合适的动作序列,以最大化其期望总奖励,当智能体从初始信念 b0 开始时。当动作序列具有无限长度时,需指定一个折扣因子 γ ∈(0,1), 以使总奖励有限且问题定义良好。
POMDP问题的解是从信念到最佳动作的映射,称为最优策略。一个策 略π诱导出一个值函数Vπ(b),该函数指定了从信念b执行策略 π所获得的期 望总奖励,其计算公式为Vπ(b)=E[∑∞ t=0 γ tR(st,at)|b, π]。最优策略是对于 任意信念b,其值函数Vπ ∗(b)在所有可能策略中最高的那个策略π ∗。
NOMDP 是一类没有观测信息的 POMDP,即对于任意 s ∈S 和 a ∈A,Z(s, a, na)= 1。因此,NOMDP 的解是一条标称路径,该路径将时间步映射到最优动作。
NOMDPs和POMDPs的问题设置均面向运动规划问题,旨在寻找从一 个状态转移到另一个状态的策略。NOMDPs和POMDPs在状态空间和动作 空间的表示以及运动不确定性方面采用相同的方式。状态空间是一个连续的 度量空间,记为X,其微分同胚于Rn,其中n是X的维度。动作空间与控制空 间相同,记为U,通常其维度小于或等于X的维度。运动不确定性来源于执 行误差,并通过如下形式的随机动力系统表示:
$$
x(t+Δt)= x(t)+∫ t+Δt f(x(t), u˜(t))dt, \tag{1}
$$
其中x(t) ∈X, ˜u(t) ∈ U,且Δt为离散时间步。控制量 ˜u(t)是系统实际执行的控制量, 由于存在执行误差,其并不总是与输入控制量u(t)一致,即存在一个误差向量w,使得:
$$
u˜(t)= u(t)+ w. \tag{2}
$$
向量w是从概率分布中采样的加性噪声,该分布可以是任意类型的分布。
鉴于非可观测马尔可夫决策过程(NOMDPs)没有观测,因此NOMDPs与 POMDPs在目标函数上有所不同。NOMDPs采用的是一种常用于运动规划的目 标函数。本文定义的NOMDP问题包括寻找一个控制输入序列,使其成本最小化, 同时确保碰撞概率低于给定阈值,并且到达目标的概率高于给定阈值。更准确地 说,假设p=(u1, u2,… , um)是系统的控制输入序列。序列中的每个控制输入均 在一个单位时间步长内执行,并从初始信念b0开始。该执行过程将产生一条轨迹 π p b=(b0, b1, b2,… , bm),即当对信念b0的支持集中的状态应用公式 1 并结 合噪声模型w按照序列p执行时所产生的轨迹。轨迹π的持续时间记为Tπ。如果 轨迹π是由包含m个时间步长控制的序列p所诱导,则Tπ= m · Δt。沿轨迹的一 信念状态
信念空间规划中合适距离函数的重要性 687
在时间 t 的轨迹 π 表示为 π(t)。由 p 生成的轨迹 π p b0 的成本为 c(π p b0) =∑mi=1 ∫x∈Xcost (x, ui) · bi−1(x)dx。NOMDP求解器的目标是寻找一个控 制序列 p,该序列生成轨迹 π p b0,使得在时间 Tπ 处于目标区域的概率高 于阈值:P(π(Tπ) ∈XG)) > Pgoal,处于自由空间的概率高于阈值:P free( π p) > Pvalid,并且使成本 c(π) 最小化。
部分可观测马尔可夫决策过程(POMDP)的POMDP目标函数采用常用 的定义(第2节)。对于任意状态R(s,a)和动作s的奖励函数a,是碰撞代价 与到达目标的奖励之和。造成目标函数这种差异的原因在于,求解带有概率 约束的POMDP仍然是一个相对开放的问题。
3 信念空间规划的距离函数
计算最优POMDP策略在计算上难以处理[19]。然而,在过去几年中,已经 提出了能够快速计算出接近最优策略的近似方法。其中大多数方法依赖于采 样,并且依赖于距离函数。这些方法可以分为若干种不同的途径。
基于点的技术[12, 23, 27, 28]通过采样构建一个规模小但具有代表性的 信念集,并通过对采样得到的信念迭代计算贝尔曼回溯[23]来寻找近似最 优策略。关键在于采样策略,一些成功的方法使用距离函数来指导采样。 例如,PBVI[23]仅在新采样的信念与现有信念之间的L1距离大于某个阈值时 才保留该新信念,而GCS[13]使用EMD,另一种方法[8]则使用KL散度 进行类似的拒绝采样。一种快速的离线基于点的求解器[12]也使用L1距离 进行剪枝。基于点的方法可以处理任意类型的分布,但在解决大规模连续动 作空间的问题时存在困难。
本文评估了四种用于信念空间规划的距离函数。其中两种,即库尔贝克‐ 莱布勒(KL)和L1散度,是信念空间规划中常用的方法。一般来说,这两种函 数在计算信念之间的距离时未考虑底层状态空间距离。这一特性限制了它们 在引导信念空间中的采样和剪枝方面的有效性。为缓解这些问题,本文提出 了两种替代方法:Wasserstein(也称为推土机距离(EMD))和豪斯多夫距 离。这两种函数均基于底层状态空间距离来计算距离。尽管它们在信念空间 规划中尚未被广泛使用,但在计算机视觉和最优传输领域应用广泛,因此这 些距离计算已有大量高效实现。在下文中,信念被定义为在公共状态空间 X上的分布。
688 Z. 利特菲尔德 等人
A. Wasserstein距离/EMD
直观上,Wasserstein距离或EMD计算两个分布之 间的距离,即把一个分布的概率质量移动到另一个分布所需的工作量。更正式地, EMD定义为:
$$
D_W(b, b’)= \inf_f \left{ \int_{x \in X} \int_{x’ \in X} d_X(x, x’) f(x, x’) \partial x \partial x’ \mid b= \int_{x’} f(x, x’)dx’, b’(x’)= \int_x f(x, x’)dx \right}, \tag{3}
$$
其中 dX 是状态空间X中的距离,f 是联合密度函数 .
EMD 将状态空间中代价函数的利普希茨连续性延续到信念空间中期望 代价的利普希茨连续性。形式上,设 dX 为可分状态空间 X 上的距离函数, cost(x, u) 表示在状态 x ∈ X 处施加控制 u ∈U 在单位时间内的成本。设信 念 b 和 b′ 为 X 上的分布,并令关于信念 b 的代价函数为 cost(b, u)= ∫x∈X cost(x, u)b(x)dx。
定理 对于任意控制输入 u ∈U,如果代价函数在状态空间中满足Lipschitz连续性,即对 任意x ∈X,有 |cost(x, u) −cost(x′, u)| ≤C · dX(x, x′),则在使用EMD度量的信念空间 中,代价函数也是利普希茨连续的: |cost (b, u) −cost(b′, u)| ≤C · DW(b, b′)。
证明 该证明基于众所周知的Wasserstein距离[5]的Kantorovich对偶性。 Kantorovich距离定义为
$$
D_K(b, b’)= \sup_{g \in Lip_1} \left( \int_{x \in X} g(x)b(x) dx - \int_{x \in X} g(x)b(x) dx \right),
$$
其中 Lip1 是定义在 X 上的所有 1‐Lipschitz函数 的集合。现在,根据定义:
$$
\left| \int_{x \in X} cost(x, u)b(x) dx - \int_{x \in X} cost(x, u)b’(x) dx \right|. \tag{4}
$$
为了满足Kantorovich距离的1‐Lipschitz要求,我们可以在状态空间X中使用缩 放距离函数,即d′ X= C · dX。已知如果使用d′ X 作为状态空间距离,则信念空间 距离D′ W= C · DW= C · DK。最后一个等式源于Kantorovich与Wasserstein距 离的对偶性。这意味着,通过使用状态空间度量d′ X ,公式(4)可以被限定为: | 代价(b, u) −代价(b′, u)|≤C · DK(b, b′),因此| 代价 (b, u) −代价(b′, u)|≤C · DW(b, b′)。
从文献[11],中已知,当信念空间中的度量为EMD时,POMDPs中的值 函数是利普希茨连续的。上述定理采用了与先前工作[11]相似的证明策略, 但将结果推广到了状态空间中任意利普希茨连续的代价函数。
信念空间规划中合适距离函数的重要性 689
B. 豪斯多夫距离
豪斯多夫距离是计算机视觉中一种流行的度量。该函数通 过最大最小操作来计算两个集合之间的距离。在信念之间的距离方面,可以 基于信念的支持集来定义该函数。略微滥用参数的表示法,该函数可在信念 空间中定义为:
$$
D_H(b, b’)= \max { d_H(b, b’), d_H(b’, b) }
$$
where
$$
d_H(b, b’)= \max_{x \in support(b)} \left{ \min_{x’ \in support(b’)} { d_X(x, x’) } \right},
$$
并且
$$
support(b)={x \in X \mid b(x)> 0},
$$
而dX(x,x′)是状态空间距离。
豪斯多夫距离比EMD更容易计算。然而,由于豪斯多夫距离衡量的是 集合之间的距离,而非分布之间的距离,因此它忽略了概率值。这意味着, 如果两个分布在支撑集上完全相同,即使其概率值存在显著差异,这两个分 布也会被视为位于信念空间中的同一点。这个问题恰好与下面所述的L1距离 和KL散度所面临的问题相反。
C. KL散度-Divergence
在信念空间规划中常用的距离函数是库尔贝克‐莱布勒( KL)散度。它用于衡量两个分布之间信息量的差异。更正式地,KL散度定义为:
$$
D_{KL}(b, b’)= \int_{x \in X} b(x)(\ln b(x) - \ln b’(x)) dx. \tag{5}
$$
在一般情况下,KL散度不考虑底层状态空间距离。但对于某些分布, 它在一定程度上确实考虑了该距离。例如,当应用于高斯信念时,KL散度 部分基于均值的欧氏距离。更完整地说,两个多元高斯信念之间的KL散度, 记为 b1= N(μ1,Σ1) 和 b2= N(μ2,Σ2),是
$$
D_{KL}(b1, b2)= \frac{1}{2} \left( (\mu_2 - \mu_1)^T \Sigma^{-1}_1 (\mu_2 - \mu_1) + \text{tr}(\Sigma^{-1}_2 \Sigma_1) + \ln \left| \frac{\Sigma_1}{\Sigma_2} \right| - K \right), \tag{6}
$$
其中K是底层状态空间的维度。
当应用于具有连续状态空间的一般信念时,通常首先将状态空间X离散化为 均匀网格单元,然后使用公式(KL‐散度5)计算,就好像这些信念是离散分布一样。 这种计算意味着状态空间距离仅考虑网格单元分辨率范围内的信息,这非常有限。
only considered up to the resolution of the gridcells,which is very limited.
请注意,KL散度不具有对称性,因此不是真正的度量。可以通过加上 反向距离,或计算两个分布均值的距离来使其对称(即 $ D_{KL} (b, \frac{b + b’}{2}) + D_{KL} (b’, \frac{b + b’}{2}) $)。后一种策略称为詹森‐香农散度。在 accompanying 比较研究中,两种 使用了两种实现方法:(i) 詹森‐香农,以及 (ii) 使用高斯分布对信念进行近似, 如公式(6)所示。
D. L1 距离
在信念空间规划中另一种常用的距离函数,也是最简单易计算的, 即L1距离,其定义如下:
$$
D_{L1}(b, b’)= \int_{x \in X} |b(x) - b’(x)| dx.
$$
大多数信念空间规划器对离散分布使用L1距离,即X是离散的,且L1距离通过在X上 求和而非积分来计算。
当状态空间是连续的且使用L1距离时,状态空间会在合适的分辨率下进 行离散化,并将L1距离计算应用于离散化状态空间上的信念分布。这种离散 化意味着L1距离与KL散度类似,仅在状态空间离散化的分辨率范围内考虑 底层的状态空间距离,而该分辨率通常非常有限。
4 用于比较研究的算法
为了确定在给定复杂性的情况下哪种距离函数最适合信念空间规划,我们采用了 一种基于采样的框架。
A. 非可观测马尔可夫决策过程(NOMDP)
该框架遵循基于树采样的规划 器,基于RRT的BestNear变体[17,30],但被适配用于信念空间规划。已从 理论上证明——至少在确定性情况下——即使没有导向函数的访问权限,该 方法仍能随时间改善路径质量。收敛至最优性要求状态空间和控制空间满足 利普希茨连续性。
算法1:SPARSE_BELIEF_TREE(B,U,b0,N, Tmax, δn, δs)
G={顶点集V →{b0} ,边集E → 0};
进行 N 次迭代执行
bselected ←选择节点 (B,顶点集V,δn);
bnew ←随机_传播 (bselect, U, Tmax);
如果 IsNodeLocallyBest (bnew, S, δs)则
顶点集V ←顶点集V ∪{bnew};
边集E ←边集E ∪{b select → b new};
Prune_Dominated_Nodes(bnew,顶点集V,边集E, δ s) ;
算法框架的概述如算法1所示。作为输入,规划器接收信念空间B、控制空 间U、初始信念b0以及数量
在信念空间规划中合适的距离函数的重要性 691
迭代次数N。此外,算法1接收一个最大传播持续时间Tmax和两个半径参数 δn与 δs,其含义将在下文说明。选择过程(第3行)在算法2中进行了总结。首先在 信念空间B中随机采样一个 δ‐信念分布brand,并计算距离阈值 δn范围内的信念分 布集合Bnear。若在此阈值范围内未找到任何信念,则返回最近的分布,类似于 基本RRT方法。如果集合DB中存在信念,则返回成本最优(例如轨迹持续时间 最短)的那个。
算法2: 选择节点(B, V, δn)
brand ←样本_信念(B);
Bnear ←临近(V,brand, δn);
如果 Bnear= ∅ 返回 最近邻(V,brand);
否则返回 arg minb∈Bnear成本(b);
算法1的第4行是用于向树中添加新信念状态的传播原语。该子程序在算 法3中详细说明。首先,时间持续长度被均匀采样,直至最大时间Tmax。为 了满足分段常数控制输入的要求,所采样的时间必须是最小Δt的常数倍, 控制输入在时间持续长度确定后进行采样。根据这些控制输入,可以通过转 移模型更新信念分布。
算法3: Random_Prop(bprop, U, Tmax)
t ←样本(0, Tmax); ϒ ←样本(U, t);
return bnew ← ∫ t
为了进行剪枝,算法 算法1 的树数据结构 V G(V,E)中的节点集被划分 为两个子集 Vactive 和 Vinactive。在以自身为中心、半径为 δs 的邻域内,V active 中的节点具有从起点出发的最优成本,这些节点将被算法考虑用于扩展。 而在局部邻域内,在路径成本上被其他节点支配的节点是: 如果是叶子节点或在 Vactive 中没有子节点,则将其剪枝。 或者如果它们在Vactive中有子节点,则被添加到集合Vinactive中。集合Vinactive中的节 点不会被选中进行传播。
算法4 详细描述了一种简单的操作,用于确定如何修剪树中已存在的节点。仅当 新的信念分布bnew在其局部 δs邻域中具有最优成本时,才会调用该算法。随后, 将路径成本方面处于劣势的现有节点集合设为非活动状态。如果这些节点同时也 是树的叶节点,则会从树中移除。若父节点也处于非活动状态,则此过程可沿树 向上持续进行。该操作有助于减小存储树的规模,并促进选择路径质量较好的节 点。
692 Z. Littlefield 等人
算法4: 剪枝(bnew, G, δs)
Bdominated ←查找被支配的(G,bnew, δs);
对于 b ∈ Bdominated 执行
b.set_inactive();
当 IsLeaf(b) 且 b 为非活动状态 时执行
xparent ←Parent(b);
边集E ←边集E{bparent → b};
顶点集V ←V{b};
b ← bparent;
显然,在基于采样的信念空间规划框架的整个运行过程中,频繁地调用 距离函数,并且在很大程度上依赖于距离函数的选择。
B. 部分可观测马尔可夫决策过程(POMDP)[2],
该框架采用一种基于点 的方法,类似于蒙特卡洛值迭代(MCVI)[12],后者是SARSOP的扩展。 SARSOP被认为是求解连续状态空间问题 fastest 的离线通用POMDP求解器。 MCVI方法经过轻微修改,使用距离函数对采样信念进行剪枝。算法5详细 描述了用于POMDP的算法,其中将SARSOP作为其采样策略(第6行)。
第7行和第8行中的函数最近邻(b)返回树T中与信念b最接近的信念。对 MCVI所做的唯一修改是在第7行添加了条件,当新采样的信念在T中的最近 邻位于给定阈值范围内时,该信念将被拒绝。
算法5: ModifiedMCVI(b0)
通过将b0设为树T的根节点来初始化信念树T;
使用空图初始化 策略图;
将值函数的上界V初始化为∞;
将值函数的下界V初始化为‐∞;
当 |V(b0)−V(b0)| > ε时执行循环
采样新信念b;
如果distance(b, Nearest(b))< δth成立
则b ← Nearest(b);
否则
将b添加到T;
MCVI Backup(, b);
V= UpdateUpperBound(b);
V=UpdateLowerBound(b);
C. 提高速度的算法细节
距离函数的实现经过优化以减少计算时间。KL散度和 L1距离被
信念空间规划中合适距离函数的重要性 693
通过分箱实现。不需要完整的状态空间网格,只需非零条目箱即可。这使得 能够处理高维问题,节省空间并减少计算时间。豪斯多夫和EMD函数虽然 不需要分箱,但使用分箱后效率会大大提高。在求解非可观测马尔可夫决策 过程(NOMDPs)时,分箱宽度的选择应确保多个单独的箱子可以包含在 剪枝半径 δs内。这种离散化引入了近似误差。
为了进一步加快EMD计算速度,采用了一种近似方法来偶尔替代对标 准方法的昂贵调用。该方法的动机源于以下事实:如果两个分布相距太远, 则它们的EMD距离接近于其质心之间的距离。因此,如果根据分布的直径 及其离散化判断这两个分布存在重叠,则执行对EMD计算的标准调用;否 则,使用两个质心之间的距离作为替代,这是一种快速操作。
在以下实验中KL‐高斯表示将一组粒子近似为高斯分布,并使用公式6中的闭式表达计算距离。该距离函数不使用分箱,因为高斯参数化提供了高效的表示。
信念空间规划中合适距离函数的重要性
5 实验评估
5.1 非可观测马尔可夫决策过程(NOMDP)
所有距离度量均在图2所示的场景中进行评估。由于非线性动力学,所有场 景均产生非高斯信念分布。目标是以至少90%的概率到达状态空间中的目标 区域。有效的轨迹必须满足碰撞概率低于20%。

图2 所考虑的场景,建议彩色查看。该二维刚体(左)必须从 左侧 移动到 右侧。汽车 (左中)必须穿过3个走廊之一。固定翼飞机(中右)必须在避开圆柱体的同时移动到对 角角落。机械手(右)必须将圆形物体推入位于 右上角 的存储位置
二维刚体
这个引入示例描述了一个在两条狭窄走廊之间移动的二维刚体。 由于执行误差以及避障要求,机器人只能通过下方走廊。状态空间是二维的 (x, y),控制空间也是二维的(v, θ),其中v ∈[0, 10]和 θ ∈[−π,π]。动力学 遵循此模型:
$$
\dot{x}= \tilde{v} \cos(\tilde{\theta}), \quad \dot{y}= \tilde{v} \sin(\tilde{\theta}),
$$
其中 $\tilde{v}= v+ N(0,1)$ 和 $\tilde{\theta}= \theta+ N(0,0.3)$。数值积分采用欧拉积分进行。
2nd阶汽车
一辆具有动力学特性的四轮车辆需要到达目标区域,同时确保较 低的碰撞概率。状态空间为5维 $(x,y, \theta,v, \omega)$,控制空间为2维 $(a, \dot{\omega}) \in([-1, 1],[-2, 0.2])$,执行误差为 $(N(0,0.05),N(0,0.002))$,其动力学为:
$$
\dot{x}= v \cos(\theta) \cos(\omega), \quad \dot{y}= v \sin(\theta) \cos(\omega), \quad \dot{\theta}= v \sin(\omega), \quad \dot{v}= \tilde{a}.
$$
使用四阶龙格‐库塔法(RK4)进行数值积分。环境比之前更加复杂,因为 每条3个走廊中都存在多条可行路径。
固定翼飞机
一架在多个圆柱体之间飞行的飞机。状态空间为9维(x,y, z, v, α, β, θ,ω, τ), 控制空间为3维(τdes ∈[4, 8], αdes ∈[−1.4, 1.4], βdes ∈[−1, 1]),其动力学方程为(来自 [21]):
$$
\begin{aligned}
\dot{x}&= v \cos(\omega) \cos(\theta), \
\dot{y}&= v \cos(\omega) \sin(\theta)), \
\dot{z}&= v \sin(\omega), \
\dot{v}&= \tau \ast \cos(\beta) - C_d k v^2 - g \sin(\omega), \
\dot{\omega}&= \cos(\alpha)\left( \frac{\tau \sin(\beta)}{v}+ C_l k v \right) - \frac{g \cos(\omega)}{v}, \
\dot{\theta}&= \frac{v \sin(\alpha) \cos(\omega)}{} \left( \frac{\tau \sin(\beta)}{v}+ C_l k v \right), \
\dot{\tau}&=\tilde{\tau}
{des} - \tau, \
\dot{\alpha}&=\tilde{\alpha}
{des} - \alpha, \
\dot{\beta}&=\tilde{\beta}_{des} - \beta,
\end{aligned}
$$
其中 $\tilde{\tau} {des}= \tau {des}+ N(0,0.03)$,$\tilde{\alpha} {des}= \tau {des}+ N(0,0.01)$,以及 $\tilde{\beta} {des}= \beta {des}+ N(0,0.01)$。数值积分采用RK4方法进行。该问题的状态空间 通常大于大多数信念空间规划器在计算上可处理的范围。利用具有合适距离 函数的基于采样的技术,使得对飞机模型进行规划成为可能。
非抓取式机械手
任务是推动一个物体到达目标。状态空间是5维的(xman,yman,xobj, yobj, θmanip),控制空间是2维的(v, θ),其中v ∈[0, 10]和 θ ∈[−π,π]。动力学方程为:
$$
\dot{x}
{man}= \tilde{v} \cos(\tilde{\theta}), \quad \dot{y}
{man}= \tilde{v} \sin(\tilde{\theta}),
$$
其中 $\tilde{v}= v+ U(-1,1)$ 和 $\tilde{\theta}= \theta+ U(-0.3,0.3)$。数值积分采用 RK4方法进行。除非机械手朝物体方向移动并推动物体,否则物体不会移动, 这意味着机械手与物体之间存在接触。一旦被推动,物体将如同附着在机械 手上一般随之移动。需要注意的是,本设置中使用的噪声模型为均匀分布, 因此得到的信念分布明显是非高斯的。
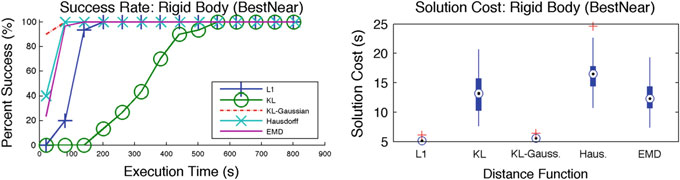
图3 二维刚体的结果——建议彩色查看
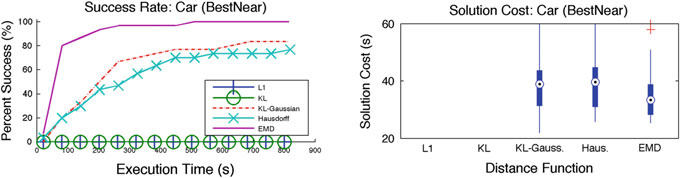
图4 汽车的结果。L1和KL未能在时间约束内生成解决方案
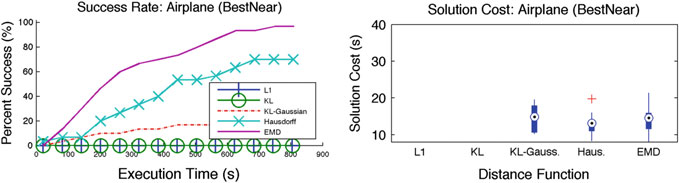
图5 飞机的结果。L1和KL未能在时间约束内生成解决方案
实验设置与结果 :每种距离函数与算法的组合均在上一节所述的四种场景中 进行评估。关键标准是在规定时间内找到解决方案的成功率。针对每种度量 的距离阈值被选择为使得所有替代方法中保留的节点数量相近。这允许公平 地比较度量对样本放置质量的影响。实验在配备英特尔至强E5‐4650 0处理器 @ 2.70GHz 的机器上执行。每次实验重复30次,使用不同的随机种子。 结果在这30次运行中取平均,并在图3、4、5和6中展示。
在大多数情况下,考虑底层状态空间距离的信念度量(如EMD、豪斯多夫和KL‐高斯)的表现明显优于不考虑状态空间距离的度量。KL和L1度量 仅考虑到状态空间离散化的分辨率对应的状态空间距离(见第4节)。当状 态空间较小时,这种考虑已足够(如图3所示)。随着状态空间规模的增大
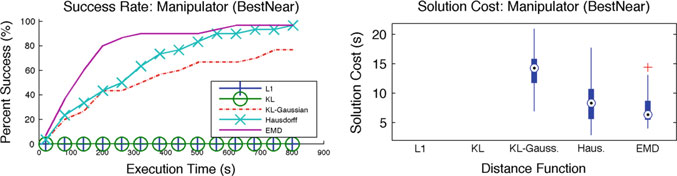
图6 操作结果。L1距离和KL散度未能在时间约束内生成解决方案
随着空间增大,这已不再足够。这些结果证实了关于在计算信念之间距离时 考虑底层状态空间距离重要性的假设。
EMD由于考虑了状态空间距离和分布,因此表现明显优于替代方法。 豪斯多夫距离由于仍考虑了底层状态空间距离,因此优于L1和KL散度。但 豪斯多夫距离未考虑分布,因此不如EMD。KL‐高斯由于考虑了相应高斯分 布的均值和方差,从而间接考虑了底层状态空间距离,因此优于L1和KL散 度。然而,该距离函数的有效性取决于高斯分布对实际分布的近似程度。
不同度量在成功运行中的路径代价相近。因此,成功率是评估不同度量 对信念空间规划器性能影响的关键标准。
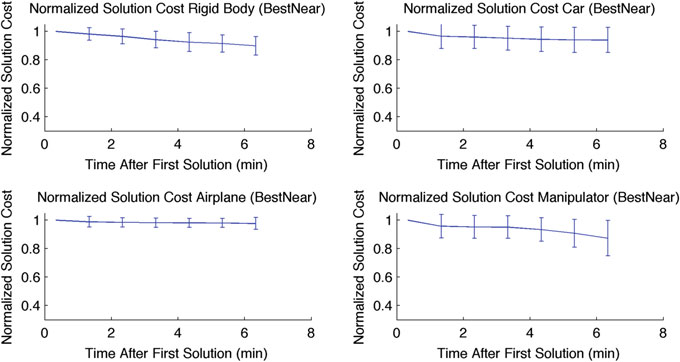
图7 EMD的归一化代价随时间变化显示了提供改进解的优势。每次试验的初始解均被归一化为1。图中显 示了随时间变化的代价及其一个标准差
成本随时间降低的结果 :图7将使用EMD的算法每次运行中生成的第一个解 归一化为1。随后,所有路径代价的改进均相对于初始代价进行绘制。该图 对所有运行进行了平均,所有运行均显示出随时间的改进。这种改进在机械 手实验中最显著。此比较仅针对EMD进行,因为它提供了最佳性能。使用豪 斯多夫和KL‐高斯度量时路径代价也可能随时间改善,但由于这些度量的成 功率较低,可用的数据点较少,难以得出有用的结论。
5.2 部分可观测马尔可夫决策过程(POMDPs)
不同的距离函数在二维导航问题上进行了测试(图8a)。机器人是一个点机 器人,可以从蓝色区域标记的任意位置开始。其任务是尽快到达目标区域 (右侧的大型圆形区域),同时尽可能避免与障碍物(灰色多边形)发生碰 撞。机器人的运动被离散化为5种动作,即向北、东北、东、东南和南方向 移动一个单位距离。其运动存在误差,表示为有界均匀分布。机器人只能在 障碍物左侧的小型圆形区域内以一定精度进行自我定位。该问题被建模为一 个POMDP,具有连续状态空间,但具有离散动作和观测空间。该POMDP模 型的奖励函数由目标奖励、碰撞惩罚和移动成本组成。
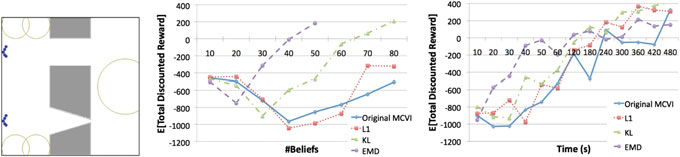
图8 部分可观测马尔可夫决策过程(POMDP)问题的比较研究
实验设置 :分别对原始和改进的MCVI方法(算法5)在L1、KL和EMD度量 下进行评估。为了设定所需参数(如距离阈值),先进行了若干次简短的初 步运行以测试不同参数组合,并保留每种方法的最佳参数。随后,每种方法 均使用相应的最佳参数执行,生成15组不同的策略。为生成每组策略,方法 持续运行直至初始信念的上界和下界之差小于给定阈值,从而确保运行结束 时不同方法生成的策略质量相近。在整个运行过程中,该方法在每次迭代时 输出中间策略 时间间隔内,每当策略图达到特定大小时。每个策略通过1,000次模拟运行 进行评估。一种方法的预期总折扣奖励计算为同一时间间隔内该方法生成的 所有策略在所有模拟运行中的平均总折扣奖励。
结果 :结果如图8b–c 所示。它们表明,EMD显著改善了采样信念的放置。 然而,使用EMD所带来的优势随着时间推移而减弱。原因是采用了距离计算 的朴素实现,即检查新的采样信念与信念树中所有已有信念之间的距离。随 着时间增加,信念树的规模增大,该计算所需的时间也随之增加。这一步骤 对EMD计算的影响远大于其他度量,因为每次EMD评估的开销更高。不过, 已有大量关于加速EMD计算[22, 26],的研究,有助于缓解这一问题。
值得探讨的是,EMD在POMDP评估中面对与NOMDP场景规模相似的 问题时的表现。然而,现有的POMDP求解器无法处理动作空间和规划范围 像NOMDP案例中那样大且长的问题(即超出二维刚体场景的情况)。尽管 如此,从NOMDP的结果可以看出,随着问题复杂性的增加,EMD的优势 变得更加明显。这一点在POMDP中很可能同样成立。在当前POMDP测试 案例中,奖励计算的成本可以忽略不计。但在更复杂的运动规划问题中,奖 励计算通常包含昂贵的碰撞检测。对于此类问题,能够以较少数量的采样信 念来解决问题的能力将更有优势,因为它减少了回溯操作的次数(从而减少 了奖励计算的次数)。因此,可以预期,当POMDP问题代表更复杂的规划 问题时,EMD将展现出额外的优势。
6 讨论与结论
本研究表明,在信念空间规划中使用Wasserstein距离相较于常用的替代方 法(如库尔贝克‐莱布勒散度和L1距离)具有显著改进。这种优势在高维系 统的规划中尤为明显。通过在信念空间中采用合适的度量,可以受益于基于 采样的规划领域的最新进展,从而实现路径质量不断提高的轨迹计算。
随着信念空间规划新方法的兴起,现在是时候退一步来理解使信念空间 规划器表现良好的关键组件了。本文旨在提供此类见解的初步尝试。


















 30
30

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









