





先看看安装部署后的效果,
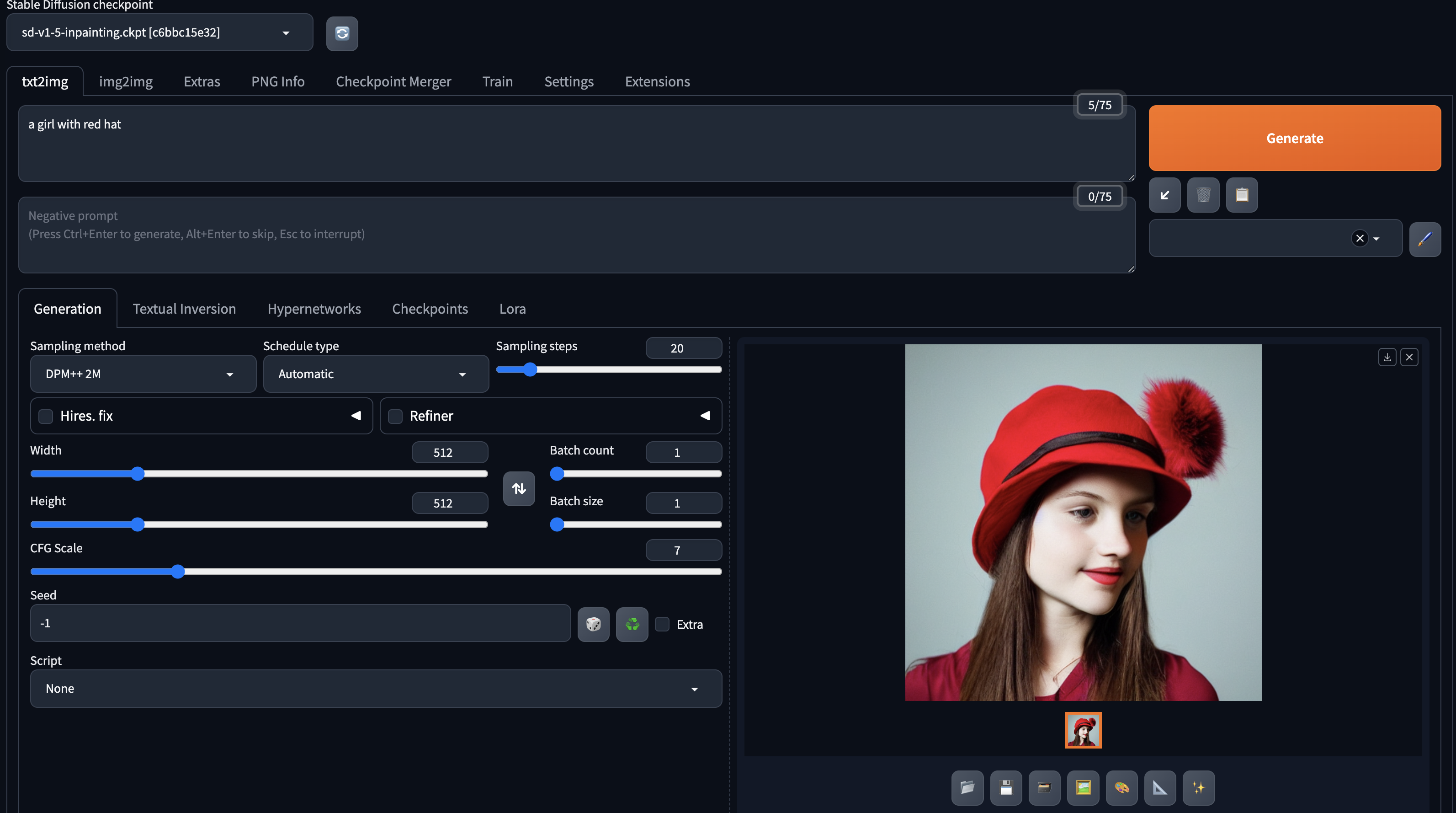
stable diffusion webui docker 离线部署
AI 绘画工具 stable diffusion 离线安装第二弹
在上两篇文章,我们在一台可以联网的机器上,准备好了安装所需要的资源,如模型文件、 apt 包、 pip 包、 git 仓库等,并把它们传送到无法联网的机器上。
其中,下载 git 仓库部分,我们直接克隆了仓库,没有切换到指定的 commit ,在后续使用相应的 git 仓库时,需要注意切换到对应的 commit 。 https://github.com/Stability-AI/stablediffusion.git 下载后的仓库需重命名为 stable-diffusion-stability-ai ,否则会报以下错误,
webui-docker-auto-1 | Installing extension dependencies (if any)
webui-docker-auto-1 | Traceback (most recent call last):
webui-docker-auto-1 | File "/stable-diffusion-webui/webui.py", line 13, in <module>
webui-docker-auto-1 | initialize.imports()
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/initialize.py", line 26, in imports
webui-docker-auto-1 | from modules import paths, timer, import_hook, errors # noqa: F401
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/paths.py", line 34, in <module>
webui-docker-auto-1 | assert sd_path is not None, f"Couldn't find Stable Diffusion in any of: {possible_sd_paths}"
webui-docker-auto-1 | AssertionError: Couldn't find Stable Diffusion in any of: ['/stable-diffusion-webui/repositories/stable-diffusion-stability-ai', '.', '/']
webui-docker-auto-1 exited with code 1
接下来,我们继续分析 stable-diffusion-webui-docker/services/AUTOMATIC1111 目录下的 Dockerfile 文件内容,原来的 Dockerfile 可看这里 https://github.com/AbdBarho/stable-diffusion-webui-docker/blob/master/services/AUTOMATIC1111/Dockerfile 。
1、基础镜像的使用,
原始 Dockerfile 分为两个阶段:一个用于下载资源的阶段(使用 alpine/git 镜像),一个用于实际应用的阶段(使用 pytorch/pytorch 镜像)。修改后去掉下载资源的阶段,通过离线准备,直接从 pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime 镜像开始构建。
# Use PyTorch base image with CUDA
FROM pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime as base
2、定义环境变量
设置了一些环境变量,将需要克隆的 Git 仓库的 commit 定义为环境变量后续使用。
# Set environment variables
ENV DEBIAN_FRONTEND=noninteractive PIP_PREFER_BINARY=1
# Define commit hashes as environment variables
ENV STABLE_DIFFUSION_WEBUI_ASSETS_COMMIT=6f7db241d2f8ba7457bac5ca9753331f0c266917
ENV STABLE_DIFFUSION_STABILITY_AI_COMMIT=cf1d67a6fd5ea1aa600c4df58e5b47da45f6bdbf
ENV BLIP_COMMIT=48211a1594f1321b00f14c9f7a5b4813144b2fb9
ENV K_DIFFUSION_COMMIT=ab527a9a6d347f364e3d185ba6d714e22d80cb3c
ENV CLIP_INTERROGATOR_COMMIT=2cf03aaf6e704197fd0dae7c7f96aa59cf1b11c9
ENV GENERATIVE_MODELS_COMMIT=45c443b316737a4ab6e40413d7794a7f5657c19f
ENV GFPGAN_COMMIT=8d2447a2d918f8eba5a4a01463fd48e45126a379
ENV CLIP_COMMIT=d50d76daa670286dd6cacf3bcd80b5e4823fc8e1
ENV OPEN_CLIP_COMMIT=v2.20.0
3、复制本地资源,
将本地准备好的资源复制到镜像中,包括 apt 包、 pip 包, git 仓库。
# Copy all local resources at once
COPY local_resources/apt-packages /local_resources/apt-packages
COPY local_resources/pip-packages /local_resources/pip-packages
4、安装必要的软件包,
通过 dpkg 安装本地的 apt 包,并使用 apt-get -f install 修复依赖关系。
# Install necessary packages
RUN dpkg -i /local_resources/apt-packages/*.deb || true && \
apt-get -f install -y --no-install-recommends && \
apt-get clean
5、准备 stable-diffusion-webui,
将本地的 stable-diffusion-webui 资源复制到镜像中,切换到特定的 commit ,安装依赖。
# Create stable-diffusion-webui directory and copy files
COPY local_resources/git-repos/stable-diffusion-webui /stable-diffusion-webui
WORKDIR /stable-diffusion-webui
# Checkout specific commit and install dependencies
RUN git reset --hard v1.9.4 && \
pip install --no-index --find-links=/local_resources/pip-packages -r requirements_versions.txt
6、准备 Git 仓库资源,
将本地准备好的 Git 仓库资源复制到 repositories 目录,切换到特定的 commit ,
ENV ROOT=/stable-diffusion-webui
# Set up repositories from the copied resources
# stable-diffusion-stability-ai https://github.com/Stability-AI/stablediffusion.git
COPY local_resources/git-repos ${ROOT}/repositories/
COPY local_repos/openai ${ROOT}/openai
RUN cd ${ROOT}/repositories/stable-diffusion-webui-assets && git reset --hard $STABLE_DIFFUSION_WEBUI_ASSETS_COMMIT \
&& cd ${ROOT}/repositories/stable-diffusion-stability-ai && git reset --hard $STABLE_DIFFUSION_STABILITY_AI_COMMIT && rm -rf assets data/**/*.png data/**/*.jpg data/**/*.gif \
&& cd ${ROOT}/repositories/BLIP && git reset --hard $BLIP_COMMIT \
&& cd ${ROOT}/repositories/k-diffusion && git reset --hard $K_DIFFUSION_COMMIT \
&& cd ${ROOT}/repositories/clip-interrogator && git reset --hard $CLIP_INTERROGATOR_COMMIT \
&& cd ${ROOT}/repositories/generative-models && git reset --hard $GENERATIVE_MODELS_COMMIT \
&& mkdir ${ROOT}/interrogate \
&& cp ${ROOT}/repositories/clip-interrogator/clip_interrogator/data/* ${ROOT}/interrogate
7、安装必要的 Python 包,
安装指定版本的 cython 、 pyngrok 、 xformers 、 GFPGAN 、 CLIP 和 open_clip 。
# Install additional Python packages
RUN pip install --no-index --find-links=/local_resources/pip-packages cython pyngrok xformers==0.0.26.post1
# Clone and install specific git repositories with environment variables
RUN git clone ${ROOT}/repositories/GFPGAN /tmp/GFPGAN && \
cd /tmp/GFPGAN && \
git checkout ${GFPGAN_COMMIT} && \
pip install --no-index --find-links=/local_resources/pip-packages .
RUN git clone ${ROOT}/repositories/CLIP /tmp/CLIP && \
cd /tmp/CLIP && \
git checkout ${CLIP_COMMIT} && \
pip install --no-index --find-links=/local_resources/pip-packages .
RUN git clone ${ROOT}/repositories/open_clip /tmp/open_clip && \
cd /tmp/open_clip && \
git checkout ${OPEN_CLIP_COMMIT} && \
pip install --no-index --find-links=/local_resources/pip-packages .
8、安装 libgoogle-perftools 并设置 LD_PRELOAD 。
# Install libgoogle-perftools and set LD_PRELOAD
RUN dpkg -i /local_resources/apt-packages/libgoogle-perftools*.deb || apt-get -f install -y && apt-get clean
ENV LD_PRELOAD=libtcmalloc.so
9、应用的其余部分不修改,
# Copy the rest of the application
COPY . /docker
# Modify gradio/routes.py and set git config
RUN sed -i 's/in_app_dir = .*/in_app_dir = True/g' /opt/conda/lib/python3.10/site-packages/gradio/routes.py && \
git config --global --add safe.directory '*'
WORKDIR ${ROOT}
ENV NVIDIA_VISIBLE_DEVICES=all
ENV CLI_ARGS=""
EXPOSE 7860
# Set entry point and command
ENTRYPOINT ["/docker/entrypoint.sh"]
CMD python -u webui.py --listen --port 7860 ${CLI_ARGS}
下面是离线部署过程中遇到的一些问题,
问题一:缺少 openai/clip-vit-large-patch14 ,报错信息, OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14' is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
详细日志如下:
webui-docker-auto-1 | creating model quickly: OSError
webui-docker-auto-1 | Traceback (most recent call last):
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/threading.py", line 973, in _bootstrap
webui-docker-auto-1 | self._bootstrap_inner()
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
webui-docker-auto-1 | self.run()
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/threading.py", line 953, in run
webui-docker-auto-1 | self._target(*self._args, **self._kwargs)
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/initialize.py", line 149, in load_model
webui-docker-auto-1 | shared.sd_model # noqa: B018
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/shared_items.py", line 175, in sd_model
webui-docker-auto-1 | return modules.sd_models.model_data.get_sd_model()
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/sd_models.py", line 620, in get_sd_model
webui-docker-auto-1 | load_model()
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/sd_models.py", line 723, in load_model
webui-docker-auto-1 | sd_model = instantiate_from_config(sd_config.model)
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py", line 89, in instantiate_from_config
webui-docker-auto-1 | return get_obj_from_str(config["target"])(**config.get("params", dict()))
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 1650, in __init__
webui-docker-auto-1 | super().__init__(concat_keys, *args, **kwargs)
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 1515, in __init__
webui-docker-auto-1 | super().__init__(*args, **kwargs)
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 563, in __init__
webui-docker-auto-1 | self.instantiate_cond_stage(cond_stage_config)
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 630, in instantiate_cond_stage
webui-docker-auto-1 | model = instantiate_from_config(config)
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py", line 89, in instantiate_from_config
webui-docker-auto-1 | return get_obj_from_str(config["target"])(**config.get("params", dict()))
webui-docker-auto-1 | File "/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/encoders/modules.py", line 103, in __init__
webui-docker-auto-1 | self.tokenizer = CLIPTokenizer.from_pretrained(version)
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 1809, in from_pretrained
webui-docker-auto-1 | raise EnvironmentError(
webui-docker-auto-1 | OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14' is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
手工下载 openai/clip-vit-large-patch14 放到本地资源库 local_repos/openai ,同时在 Dockerfile 中增加内容,
COPY local_repos/openai ${ROOT}/openai
问题2,线程创建失败,报错信息如下,
webui-docker-auto-1 | OpenBLAS blas_thread_init: pthread_create failed for thread 63 of 64: Operation not permitted
webui-docker-auto-1 | OpenBLAS blas_thread_init: RLIMIT_NPROC -1 current, -1 max
webui-docker-auto-1 | Traceback (most recent call last):
webui-docker-auto-1 | File "/stable-diffusion-webui/webui.py", line 13, in <module>
webui-docker-auto-1 | initialize.imports()
webui-docker-auto-1 | File "/stable-diffusion-webui/modules/initialize.py", line 17, in imports
webui-docker-auto-1 | import pytorch_lightning # noqa: F401
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/pytorch_lightning/__init__.py", line 35, in <module>
webui-docker-auto-1 | from pytorch_lightning.callbacks import Callback # noqa: E402
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/pytorch_lightning/callbacks/__init__.py", line 14, in <module>
webui-docker-auto-1 | from pytorch_lightning.callbacks.batch_size_finder import BatchSizeFinder
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/pytorch_lightning/callbacks/batch_size_finder.py", line 24, in <module>
webui-docker-auto-1 | from pytorch_lightning.callbacks.callback import Callback
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/pytorch_lightning/callbacks/callback.py", line 25, in <module>
webui-docker-auto-1 | from pytorch_lightning.utilities.types import STEP_OUTPUT
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/pytorch_lightning/utilities/types.py", line 27, in <module>
webui-docker-auto-1 | from torchmetrics import Metric
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/__init__.py", line 26, in <module>
webui-docker-auto-1 | from torchmetrics import functional # noqa: E402
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/functional/__init__.py", line 14, in <module>
webui-docker-auto-1 | from torchmetrics.functional.audio._deprecated import _permutation_invariant_training as permutation_invariant_training
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/functional/audio/__init__.py", line 14, in <module>
webui-docker-auto-1 | from torchmetrics.functional.audio.pit import permutation_invariant_training, pit_permutate
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/functional/audio/pit.py", line 22, in <module>
webui-docker-auto-1 | from torchmetrics.utilities import rank_zero_warn
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/utilities/__init__.py", line 14, in <module>
webui-docker-auto-1 | from torchmetrics.utilities.checks import check_forward_full_state_property
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/utilities/checks.py", line 25, in <module>
webui-docker-auto-1 | from torchmetrics.metric import Metric
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/metric.py", line 42, in <module>
webui-docker-auto-1 | from torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE, plot_single_or_multi_val
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/torchmetrics/utilities/plot.py", line 26, in <module>
webui-docker-auto-1 | import matplotlib.axes
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/axes/__init__.py", line 1, in <module>
webui-docker-auto-1 | from . import _base
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/axes/_base.py", line 14, in <module>
webui-docker-auto-1 | from matplotlib import _api, cbook, _docstring, offsetbox
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/offsetbox.py", line 33, in <module>
webui-docker-auto-1 | import matplotlib.text as mtext
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/text.py", line 16, in <module>
webui-docker-auto-1 | from .font_manager import FontProperties
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/font_manager.py", line 1588, in <module>
webui-docker-auto-1 | fontManager = _load_fontmanager()
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/font_manager.py", line 1582, in _load_fontmanager
webui-docker-auto-1 | fm = FontManager()
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/site-packages/matplotlib/font_manager.py", line 1042, in __init__
webui-docker-auto-1 | timer.start()
webui-docker-auto-1 | File "/opt/conda/lib/python3.10/threading.py", line 935, in start
webui-docker-auto-1 | _start_new_thread(self._bootstrap, ())
webui-docker-auto-1 | RuntimeError: can't start new thread
webui-docker-auto-1 exited with code 1
在 docker-compose.yml 中增加配置 privileged: true 。
微信公众号「padluo」,分享数据科学家的自我修养,既然遇见,不如一起成长。关注【老罗说AI】公众号,后台回复【文章】,获得整理好的【老罗说AI】文章全集。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









