




 本文介绍如何通过修改Elasticsearch模板和自定义Logstash模板,优化ELK日志系统,包括调整索引配置和字段类型,以提高查询效率。
本文介绍如何通过修改Elasticsearch模板和自定义Logstash模板,优化ELK日志系统,包括调整索引配置和字段类型,以提高查询效率。
在搭建ELK日志系统时,由Logstash输出到ES中的索引是按照Logstash默认的template创建mapping的,在ES的单点模式下,Kibana的Index management中看到的每个索引都是黄色的,这是因为从Logstash到ES使用默认的template创建的索引默认配置的副本数为1,而ES只有一个节点,所以健康状态显示黄色,虽然可以直接在Kibana上修改副本数为0,从而使索引的健康状态显示为绿色,但是当索引数量很多时,或者需要改变分片数或副本数等配置时,一个个的去配置就显得很鸡肋,于是就想到了修改ES template 或自定义Logstash的template来达到目的。我这里修改 template 还有一个目的就是设置字段的类型,文章最后会讲到。
一、修改ES template
在Kibana的Dev Tools中执行你配好的mapping,只要ES Mapping配置正确,执行后旧的索引不受影响,新的索引生成的时候就会按照Mapping中的配置来,如果需要某个索引立即生效,那就先删掉索引再建立索引,下面贴上示例:
PUT /_template/francis-template
{
"index_patterns": ["*"],
"version" : 60001,
"order": 1,
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "11s",
"lifecycle" : {
"name": "watch-history-ilm-policy"
}
},
"mappings": {
"dynamic_templates": [
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "keyword",
"ignore_above": 256
}
}
}
],
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
注释:
- index_patterns是新版本的属性,老版本叫template属性,虽然兼容,但是执行时会提示警告,示例是匹配所有索引。
- order的默认值是0,值越大merge的时候优先级越高
- number_of_shards为分片数,number_of_replicas为副本数,refresh_interval为写入flush时间间隔。
- lifecycle.name:为索引配置生命周期策略,可以自己定义策略,watch-history-ilm-policy 为默认生成的策略,需要手动为索引配置上才生效。
- dynamic_templates作用:如果该索引中某个字段没有在properties中配置,那么就按dynamic_templates中的来匹配,动态模板的优点是可动态添加任意字段,但如果添加的字段非常多,有可能造成es集群宕机。
- properties中配置的就是从Logstash中输出到ES且展示在Kibana中的字段,示例中只处理@timestamp。
- 如果还有其他类型字段需要处理的,只需在dynamic_templates加上一段匹配规则即可。
友情提示: 如果有多次PUT template操作,可以通过执行 GET _template/ 来查看所有template,然后找到并删掉自己PUT 进去的template,这样做是为了避免多个template相互干扰造成不必要的问题。
当然,上面那段template还有一种写法,示例如下:
PUT /_template/francis-template
{
"index_patterns": ["*"],
"version" : 60001,
"order": 1,
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "11s"
}
},
"mappings": {
"dynamic_templates": [
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
},
{
"dates": {
"match": "@timestamp",
"match_mapping_type": "string",
"mapping": {
"type": "date"
}
}
}
]
}
}
执行成功后,我们可以看到新生成的索引的mapping如下图:
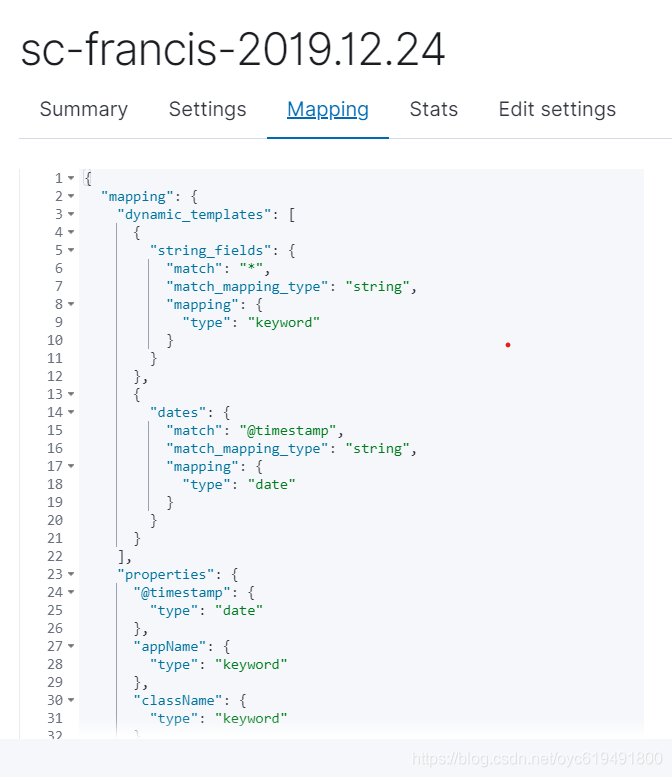
然后可以看到索引的设置如下图:
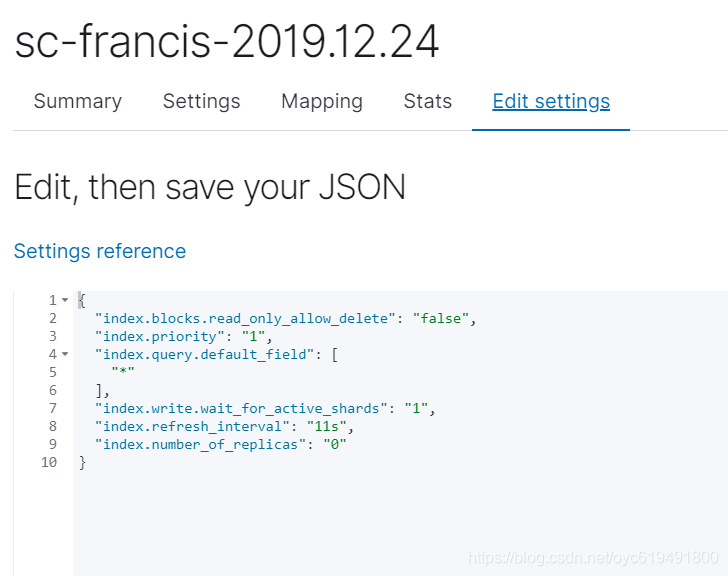
到这里我们会发现,索引的设置生效了,字段类型也按照设定的生成,目的达到。
二、自定义Logstash的template
在现实中,根据业务场景不同,第一种方法和第二种方法选择一种即可。
- 在logstash的config/logstash.conf的output中如下配置:
output {
elasticsearch {
hosts => [“http://192.168.2.101:9200”]
index => “test-francis-%{+YYYY.MM.dd}”
manage_template => false # 关闭logstash自动管理模板功能
template => "/usr/local/logstash/config/francis-template.json"
template_name => "francis-template" # 默认是logstash
template_overwrite => true # 默认false,覆盖默认template
}
}
- 在config目录下新建francis.json文件,并输入:
{
"index_patterns": ["*"],
"version" : 60001,
"order": 1,
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "10s"
}
},
"mappings": {
"dynamic_templates": [
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
三、字段类型 text 和 keyword 区别
当我们使用Logstash默认的template去创建索引及生成mapping时,我们会发现一部分字段会保存text和keyword两种类型,具体体现在Kibana创建Index Patterns 时,创建完成后你会在列表中看到形如: appName 和 appName.keyword 这样的字段名,然后当你在Discover视图中做Add Filter操作时你也会发现有appName 和 appName.keyword 两种,下面讲讲这两种类型的区别,从官网翻译而来:
keyword:
用于索引结构化内容(例如ID,电子邮件地址,主机名,状态代码,邮政编码或标签)的字段。
它们通常用于过滤(找到我的所有博客文章,其中 status为published),排序,和聚合。关键字字段只能按其确切值进行搜索。
如果您需要索引全文内容(例如电子邮件正文或产品说明),则可能应该使用一个text字段。
text:
用于索引全文值的字段,例如电子邮件的正文或产品的描述。这些字段是analyzed,也就是说,它们通过分析器传递,以便 在被索引之前将字符串转换为单个术语的列表。通过分析过程,Elasticsearch可以在 每个全文字段中搜索单个单词。文本字段不用于排序,很少用于聚合(尽管 重要的文本聚合 是一个明显的例外)。
如果您需要对结构化内容(例如电子邮件地址,主机名,状态代码或标签)建立索引,则可能应该使用keyword字段。
有时,在同一字段中同时具有全文本(text)和关键字(keyword)版本会很有用:一个用于全文本搜索,另一个用于聚合和排序。这可以通过multi-fields实现
参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/text.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/keyword.html
相信大家看区别完后对两种类型有了一个大概的了解了,结合我们ELK日志系统的业务场景,其实我们并不需要对显示在Kibana上的字段做分词处理,所以直接设置成keyword即可,理论上来讲是可以提高效率的,查询的时候直接根据关键字完全匹配或模糊查询即可。

















 1524
1524




 到【灌水乐园】发言
到【灌水乐园】发言







