




 本文整理自尚硅谷Kafka3.0教程,介绍了Kafka生产者工作流程,包括main线程构造消息、拦截器处理、序列化、分区等环节,还阐述了生产者调优方法,如提高吞吐量、数据可靠性、避免数据重复和保证数据有序的策略。
本文整理自尚硅谷Kafka3.0教程,介绍了Kafka生产者工作流程,包括main线程构造消息、拦截器处理、序列化、分区等环节,还阐述了生产者调优方法,如提高吞吐量、数据可靠性、避免数据重复和保证数据有序的策略。
本文内容整理自尚硅谷Kafka3.0教程
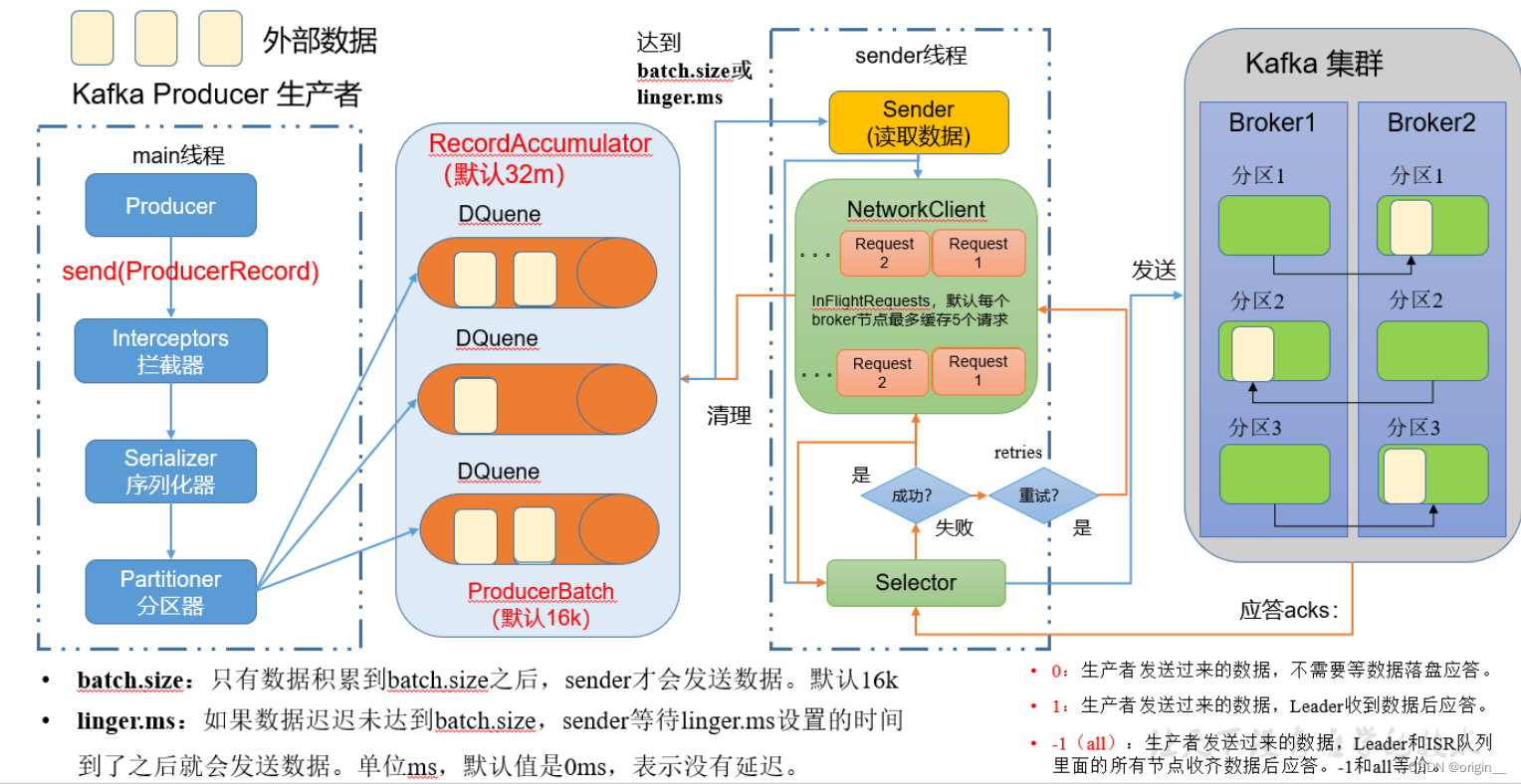
生产者工作流程
-
main线程
- Producer
- 构造消息 调用send方法
- Interceptors 拦截器
- 对消息进行定制化处理,可以有多个,形成链
- Serializer 序列化器
- 对key-value进行序列化,value是消息内容,key是一个标记,为了保证相同key在一个分区
- Partitioner 分区器
- 按照既定的分区策略发到不同的RecordAccumulator
- DefaultPartitioner 默认分区器
- 指定Partition值则按指定的来
- 未指明Partition但设置了Key,则将
hashcode(key)%partitionTotalNum作为分区值 - 均未指明,则使用黏性策略。随机选一个分区,将该分区的batch填满,再随机选下一个分区
- Producer
-
RecordAccumulator 缓冲队列
-
双端队列,每个队列存放发到各个分区的消息,默认32M
- batch.size
- 数据累积到batch.size后,才会发送,默认值16k
- linger.ms
- sender等待时间达到linger.ms后,才会发送,默认值0ms
- batch.size
-
-
sender线程
-
以ProducerBatch为单位读取消息,默认16k
-
NetworkClient
- 将消息封装成请求,以broker为key,消息为value形成队列
- 默认每个broker节点最多缓存5个请求
-
Selector
- 将请求发送到kafka服务器,失败则重试
- retry.backoff.ms 重试时间间隔 默认100ms
-
ack
- 0:不需要数据落盘即可应答
- 1:需要Leader应答
- -1:Leader和ISR队列应答
- ISR:Leader + 存活的follower
- 应答时间高于replica.lag.time.max.ms的follower,被踢出ISR
- ISR:Leader + 存活的follower
-
生产者调优
-
如何提高吞吐量
- 适当增大linger.ms
- 可以增加每批次处理的数据大小,降低发送次数
- 适当增大batch.size
- 同上,如果待发送的数据较多的情况
- 适当增大RecordAccumulator大小
- 同上
- 设置数据压缩 compression.type
- 降低单条消息的数据量
- 适当增大linger.ms
-
如何提高数据可靠性
- ack = -1
- replica > 1
- 一个follower挂了还有另一个
- min.insync.replicas > 1
- 最小应答副本数起码要有一个follower,不能只有leader应答
- 但也不能设成和ISR队列长度一样,不然有个点挂了永远不能成功应答
- ack = 1适合允许丢失少部分数据的情况,如重要性一般的日志
-
如何保证数据不重复
-
幂等性
- 相同消息broker只会持久化一条
- “相同”通过<PID, Partition, SeqNumber>判断
- PID:生产者编号,每次启动分配一个新的
- SeqNumber:消息序列号,单增
- 幂等性能保证同个会话内,某个分区内消息不重复
- enable.idempotence = true 开启,默认开启
-
事务
-
开启事务前必须开启幂等性
-
流程
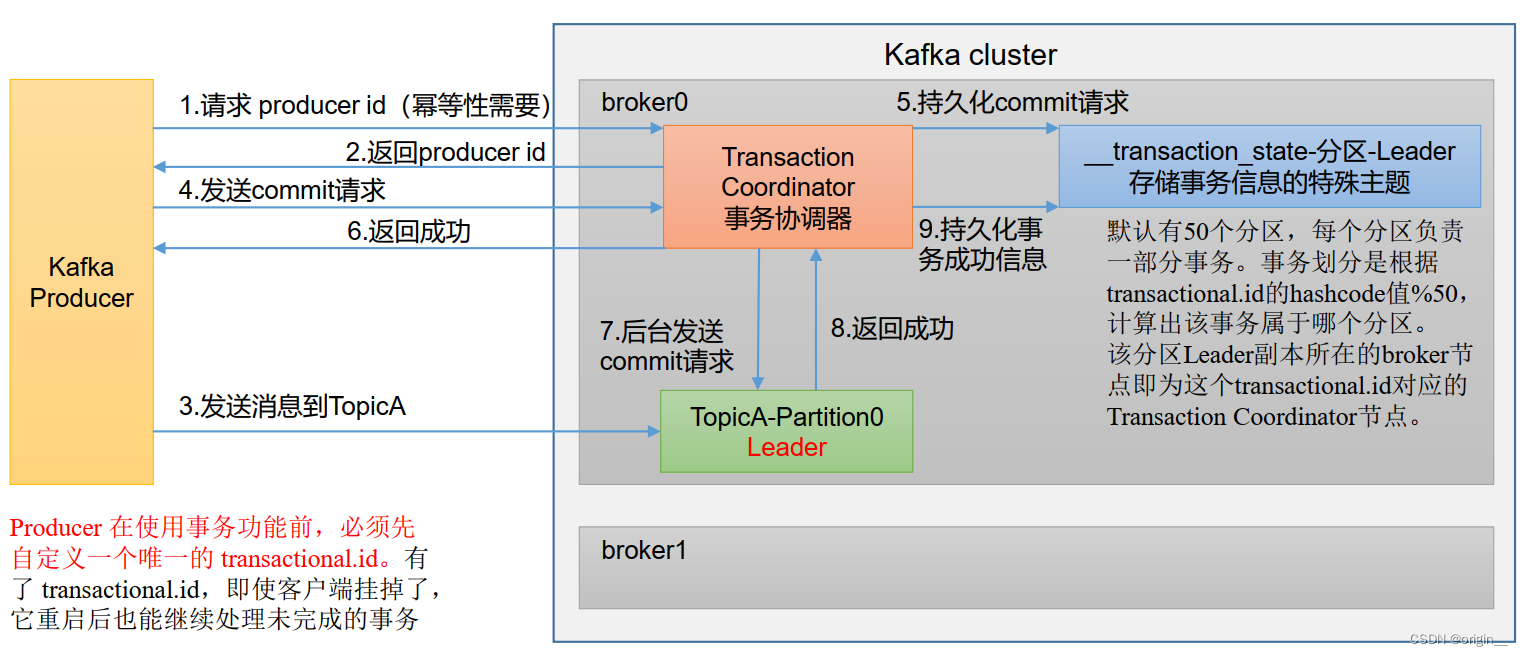
-
-
-
如何保证数据有序
- 不同分区有序无法保证,因为在不同broker上
- 单分区可保证有序
- 无序的原因是重试导致先发的消息后到
- max.in.flight.requests.per.connection = x //TODO
- 被Broker阻止前,未通过acks确认的发送请求最大数
- kafka服务器会缓存最近收到的x个请求,并重新排序,保证单分区有序。开启幂等的情况下可设 x <= 5
- 如果想要严格排序,可以设置 x = 1,但会造成性能下降


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









