




1. 安装ES
1.1 安装ES
安装es: 官网下载解压
-
启动
bin/elasticsearch -d(后台启动) -
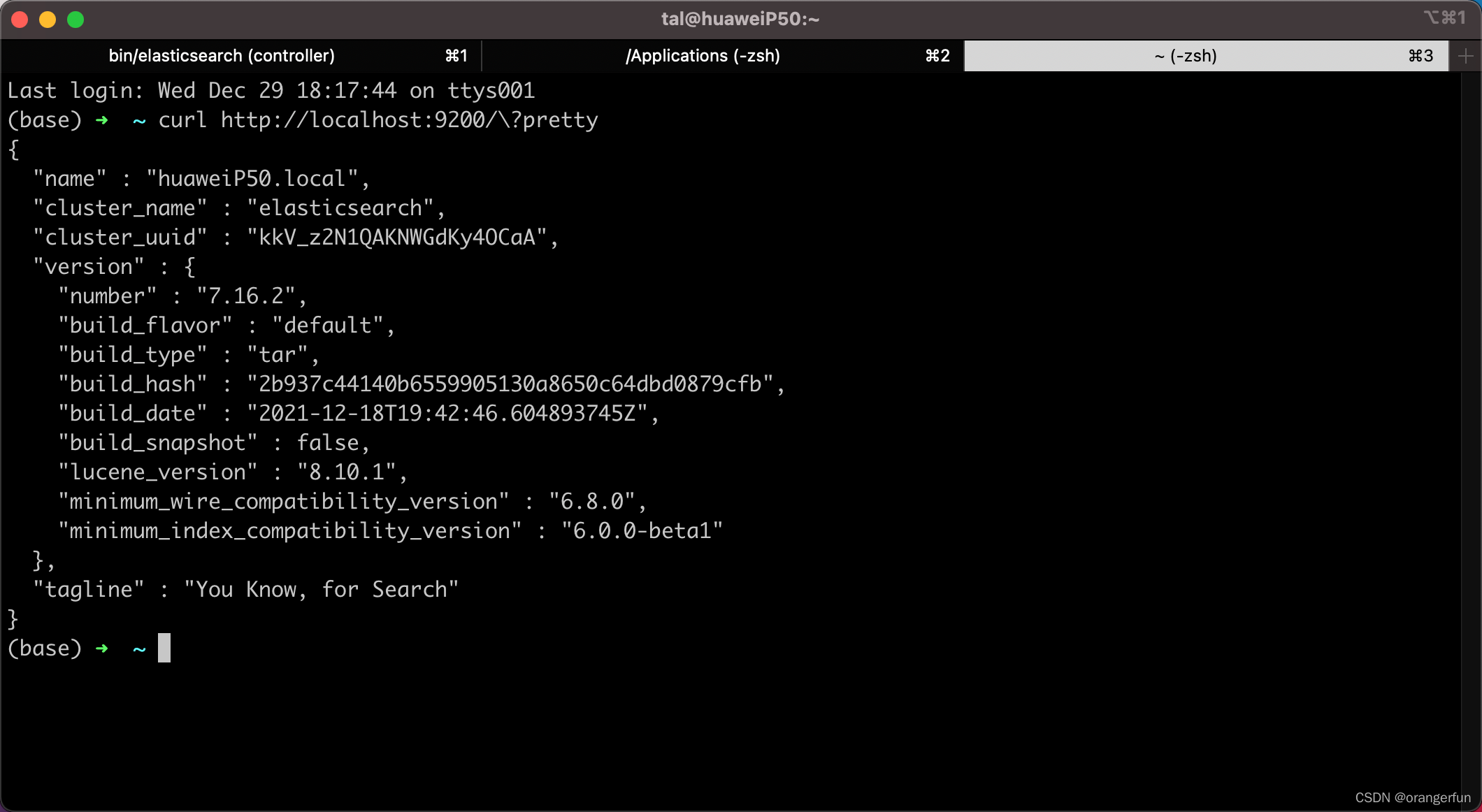
判断是否成功的标志
curl http://localhost:9200/?pretty
9200是es的默认端口,可以在config/elasticsearch.yml中修改启动成功如下图所示:
1.2. 安装插件
-
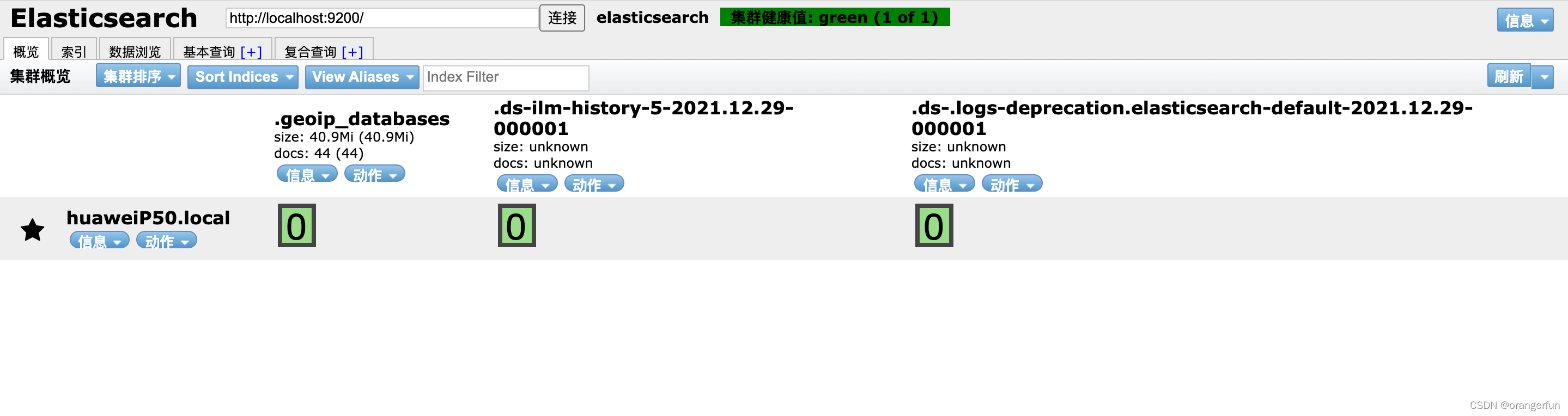
head 插件
head插件是es的一个可视化插件,类似于workbench跟mysql的关系进入github head github 按照readme 文件安装,我这里选择的是以谷歌浏览器插件的方式安装,如下图
-
marvel插件
marvel插件主要是用来监控的,也可以用来当console来使用 -
postman
用于和es交互,发送请求
2. ElasticSearch添加密码验证
1. 修改配置文件
在es包下的config目录修改es的默认配置文件elasticsearch.yml,在该文件后追加如下配置
xpack.security.enabled: true
## 加密方式
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
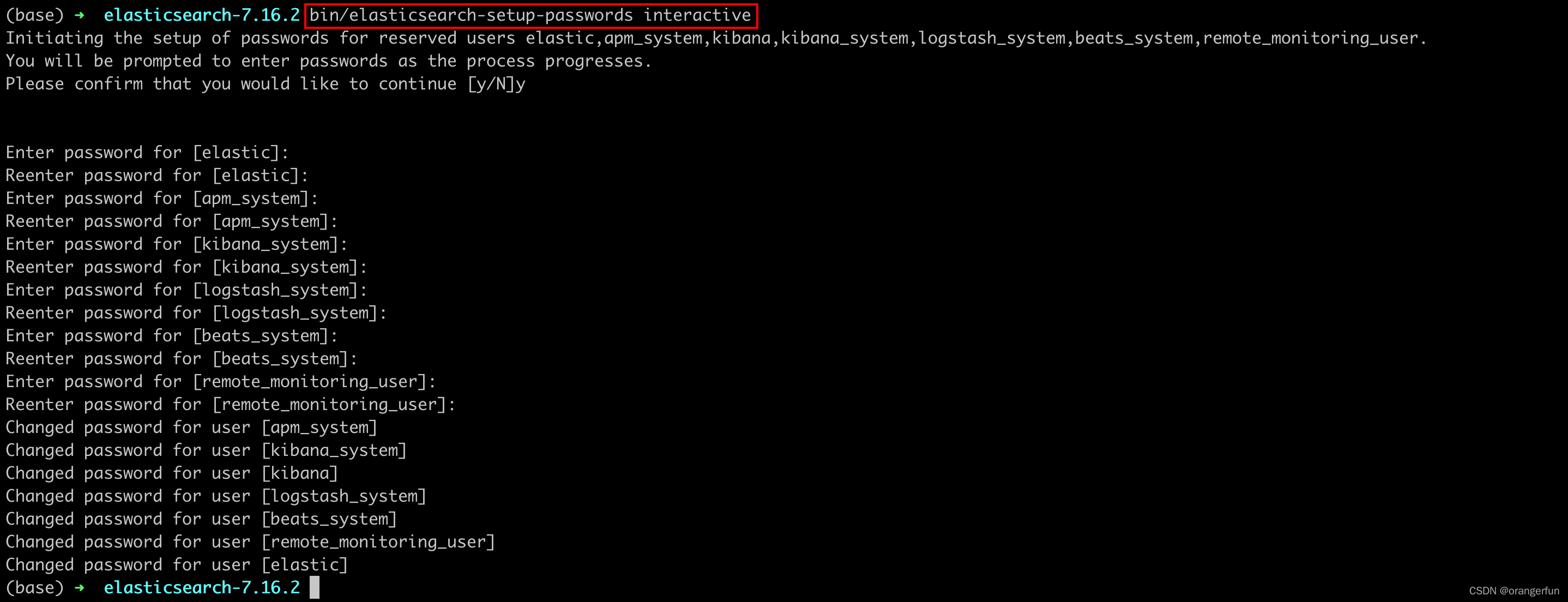
2. 设置密码
重启es让配置文件生效,再到es包下bin目录执行以下命令
.\elasticsearch-setup-passwords interactive
效果如下
3. postman中登录
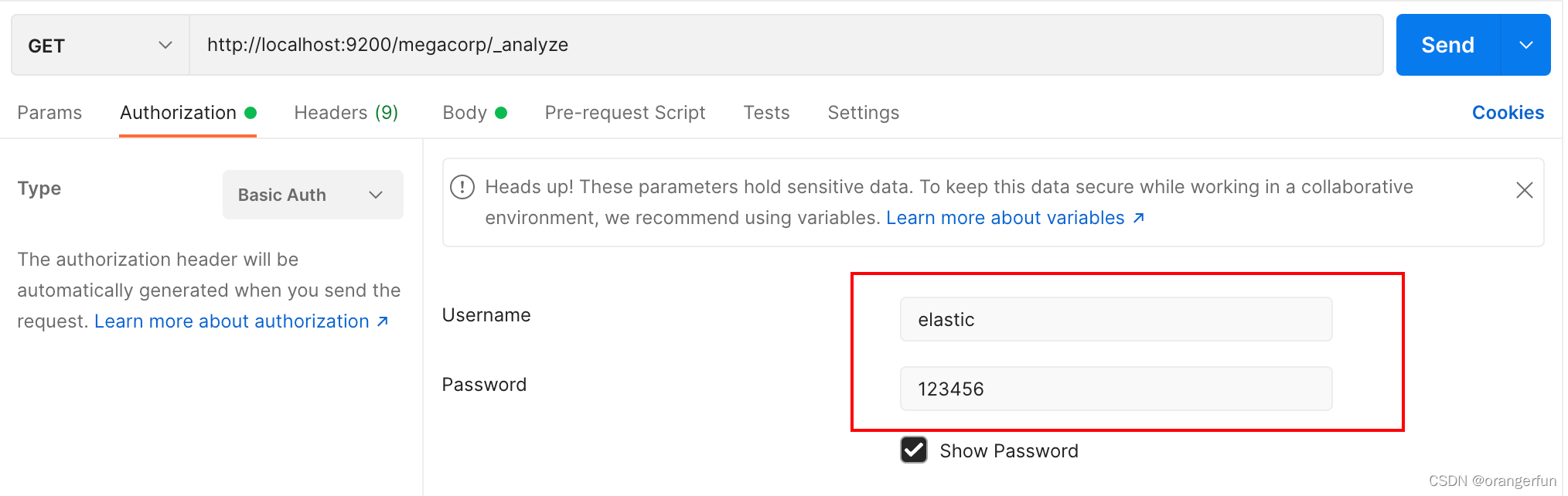
其他地方也是使用同样的方法登录,用户名为:elastic,密码为:123456
3. 概念及用postman初体验
3.1 基本概念:索引、文档、映射
节点 Node、集群 Cluster 和分片 Shards
ElasticSearch 是分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个实例。单个实例称为一个节点(node),一组节点构成一个集群(cluster)。分片是底层的工作单元,文档保存在分片内,分片又被分配到集群内的各个节点里,每个分片仅保存全部数据的一部分。
索引 Index、类型 Type 和文档 Document
如果我们要访问一个文档元数据应该包括囊括 index/type/id 这三种类型
对比 MySQL 数据库:
index → db
type → table
document → row
每一条数据就是一个document, 此处id可以在插入数据时指定,不指定也会自动生成
映射
映射(mapping) 是用来事先定义插入数据中字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。在 Elasticsearch 中,映射可分为动态映射和静态映射,静态映射是写入数据之前对字段的属性进行手工设置,动态映射是可直接创建索引并写入文档,文档中字段的类型是 Elasticsearch 自动识别的,不需要在创建索引的时候设置字段的类型。
参考 Elasticsearch 索引映射类型及mapping属性详解
3.2 创建数据
所有语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信。一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB是 HTTP 方法,可选 : GET、 POST、 PUT、 HEAD 或者 DELETEPROTOCOL即 http 或者 httpsHOSTElasticsearch 集群中任意节点的主机名,用 localhost 代表本地机器上的节点PORT运行 Elasticsearch HTTP 服务的端口号,默认是 9200PATHAPI 的终端路径(例如 _count 将返回集群中文档数量)Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvmQUERY_STRING任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)BODY一个 JSON 格式的请求体
HTTP 命令PUT新建文档, GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT
下面使用postman和es来交互进行数据创建和查询:
创建数据
创建员工目录,为每个员工的文档(document)建立索引,每个文档包含了相应员工的所有信息
- 每个文档的类型为employee
- employee类型归属于索引megacorp
- megacorp索引存储在Elasticsearch集群中
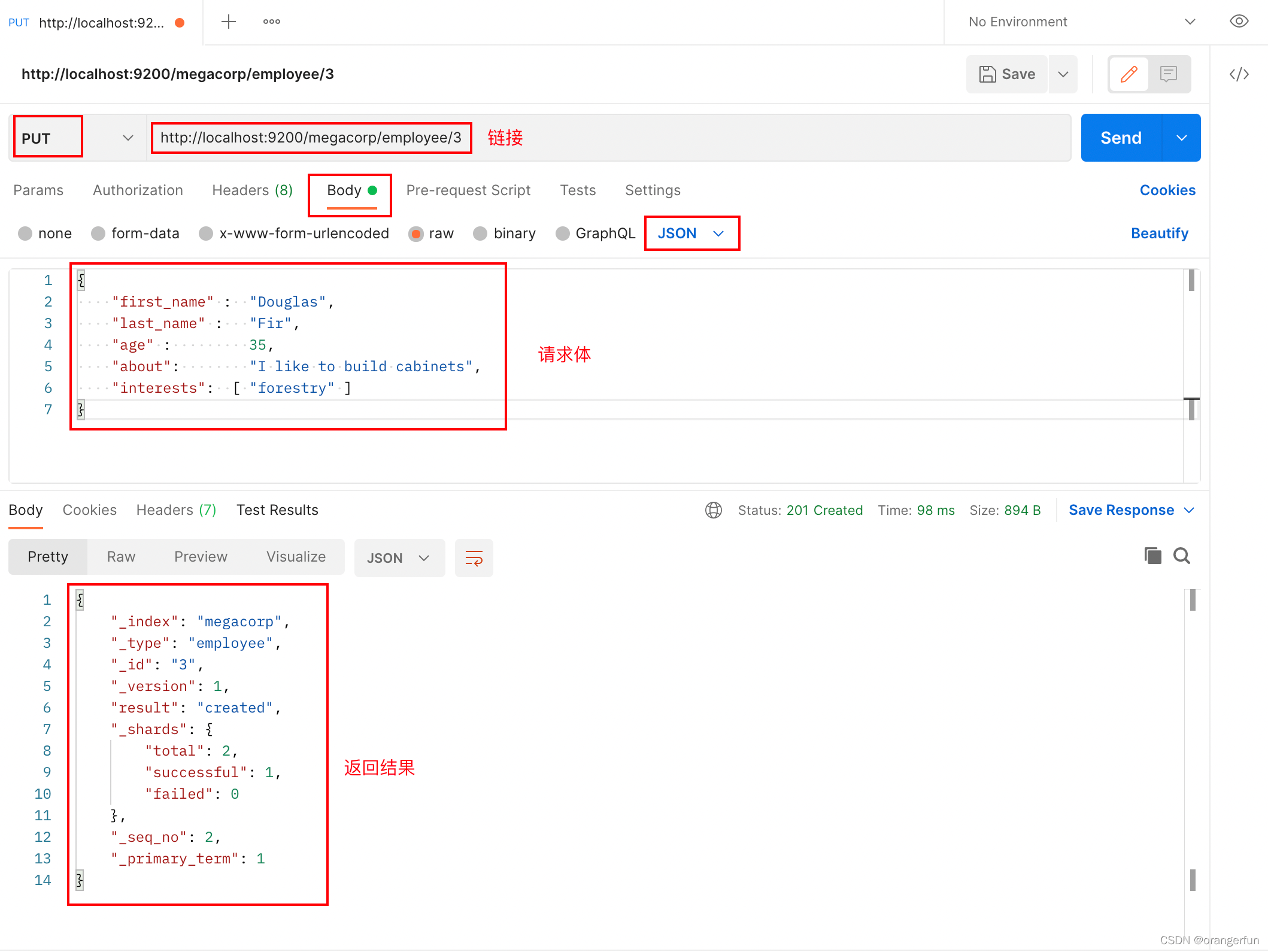
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
在postman中操作如下
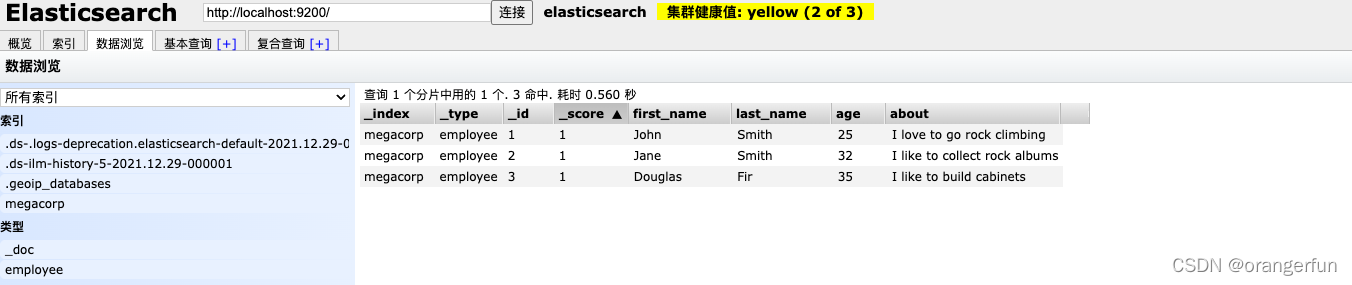
插入三个数据可以使用head插件查看相关信息:
3.3 查询数据
可以通过http get来获信息
GET /megacorp/employee/1
返回
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
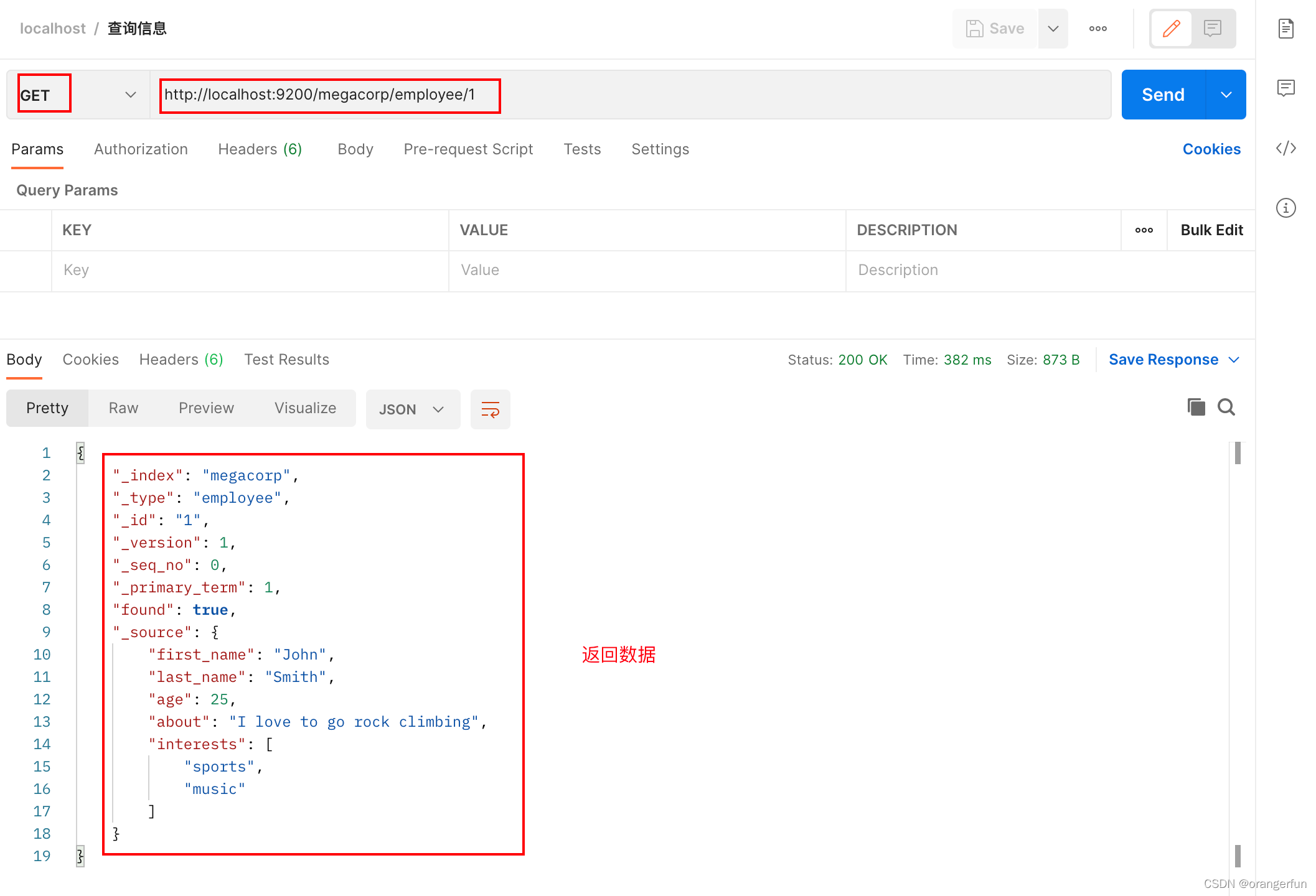
_index 索引名称
_type 类型名称
_id id(这个id可以自己指定也可以自动生成)
_version 版本号,每次改动会+1
found true表示在document存在
_source document的全部内容
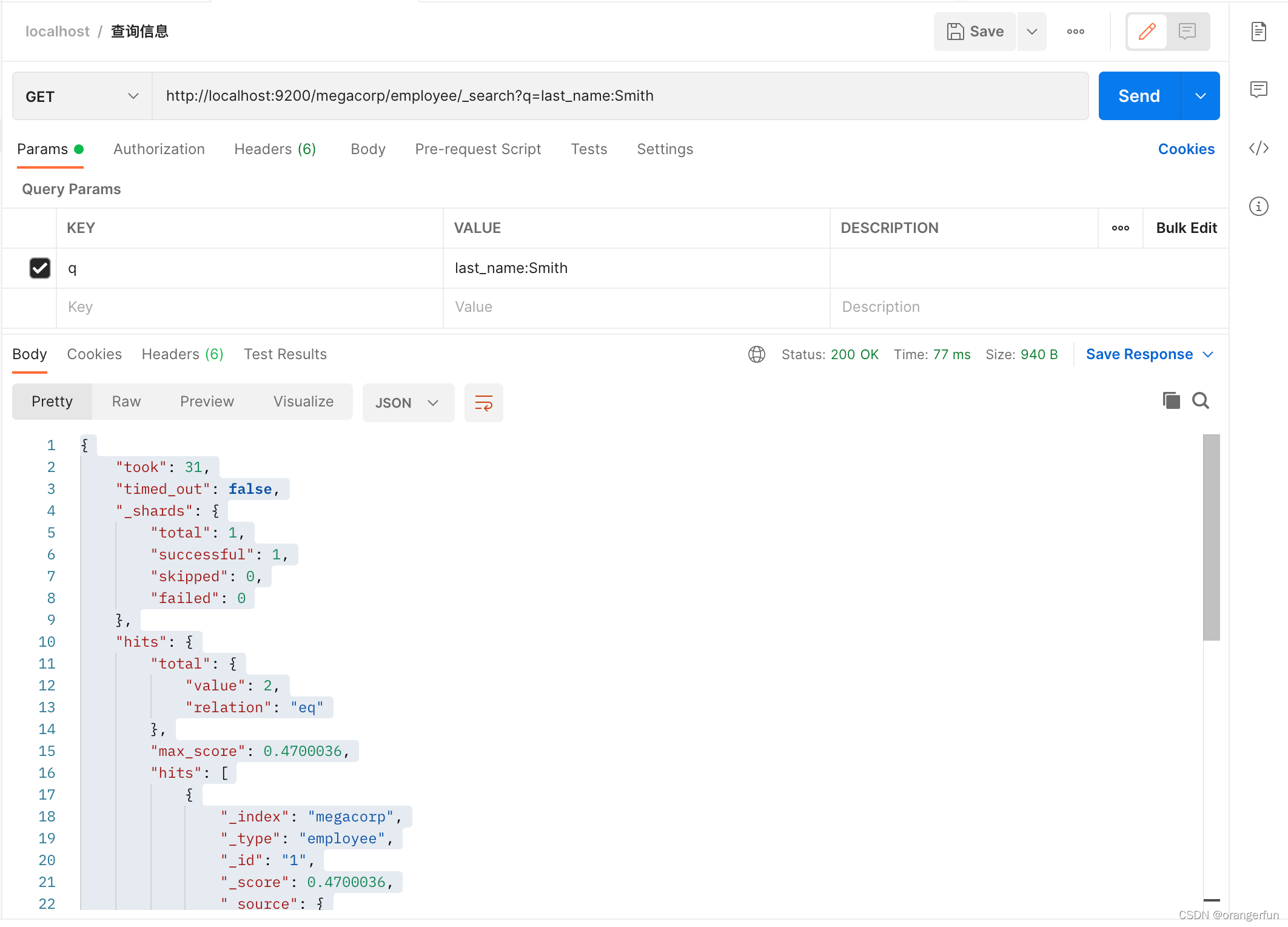
轻量级搜索
查询字符串
GET /megacorp/employee/_search?q=last_name:Smith
返回
{
"took": 31,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.4700036,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.4700036,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.4700036,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。我们可以这样表示之前关于“Smith”的查询
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
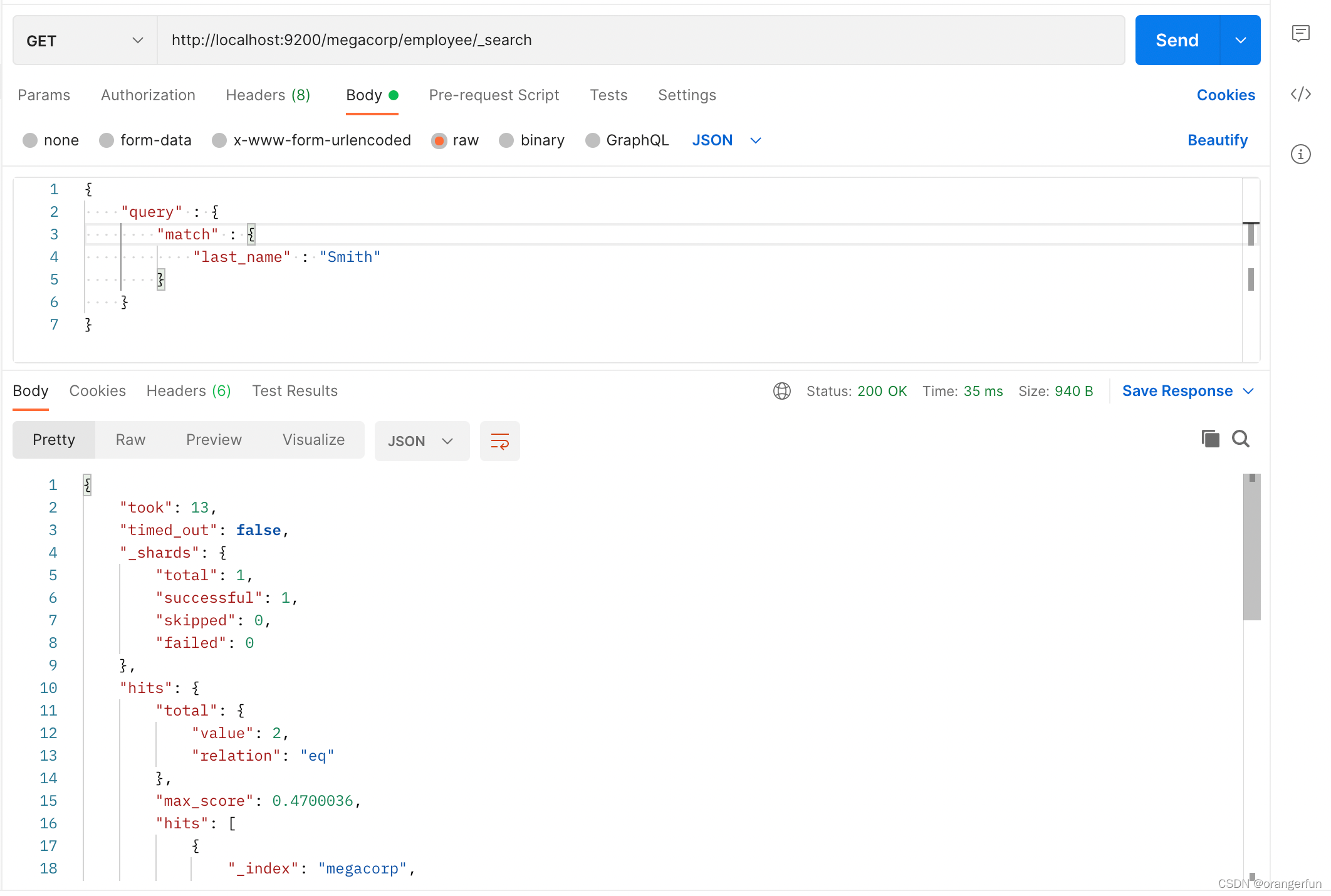
过滤器
更复杂的搜索,使用过滤器(filter)来实现sql中where的效果,比如:你想要搜索一个叫Smith,且年龄大于30的员工,可以这么检索.
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"must": {
"match": {
"last_name": "Smith"
}
}
}
}
}
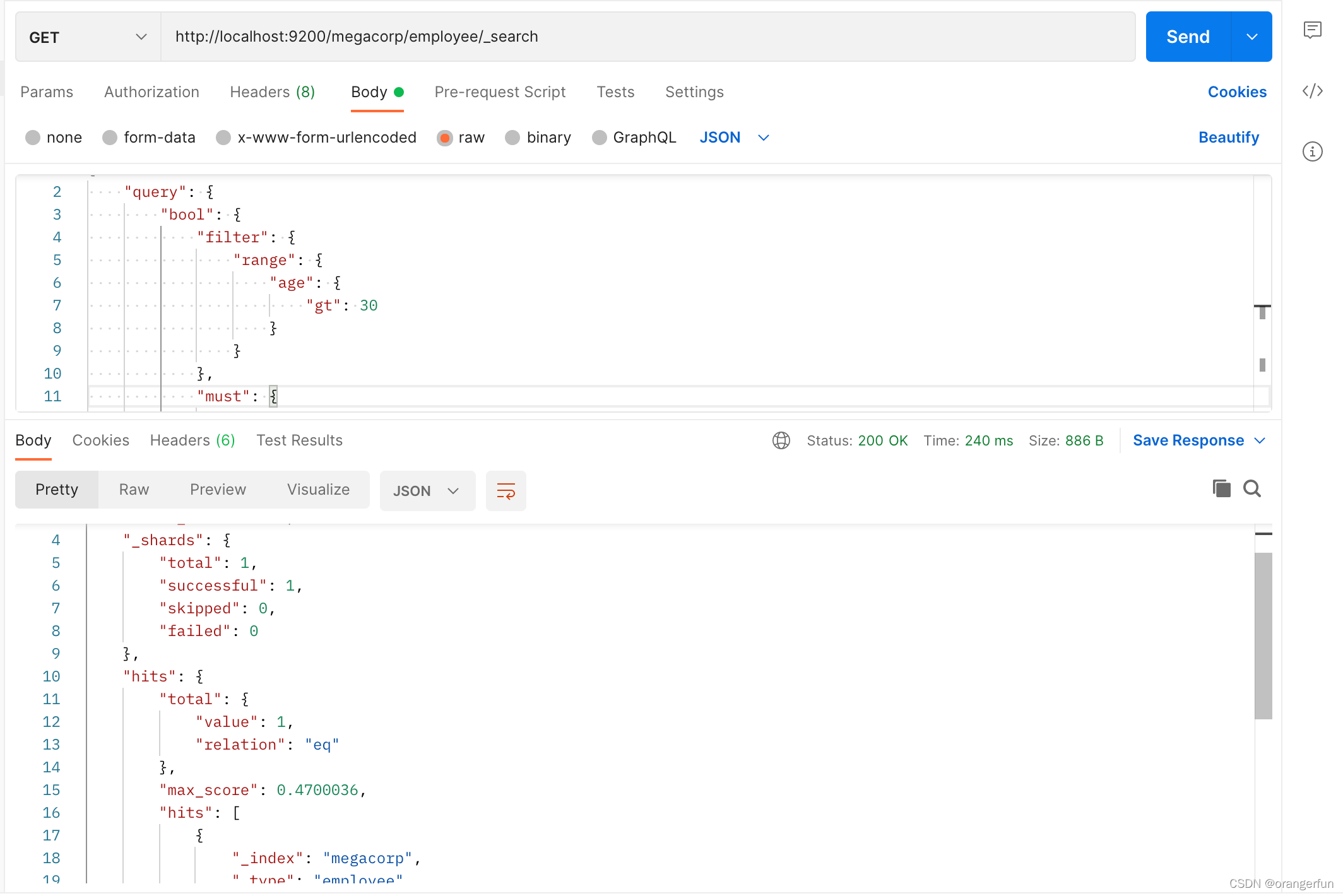
短语搜索
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
match_phrase与match的区别在于,前者会把rock climbing(搜索条件)作为一个整体,而后者会命中rock balabala climbing(后者只要命中其中一个词就算命中,比如rock climbing中命中rock就算匹配中了,就会返回结果)
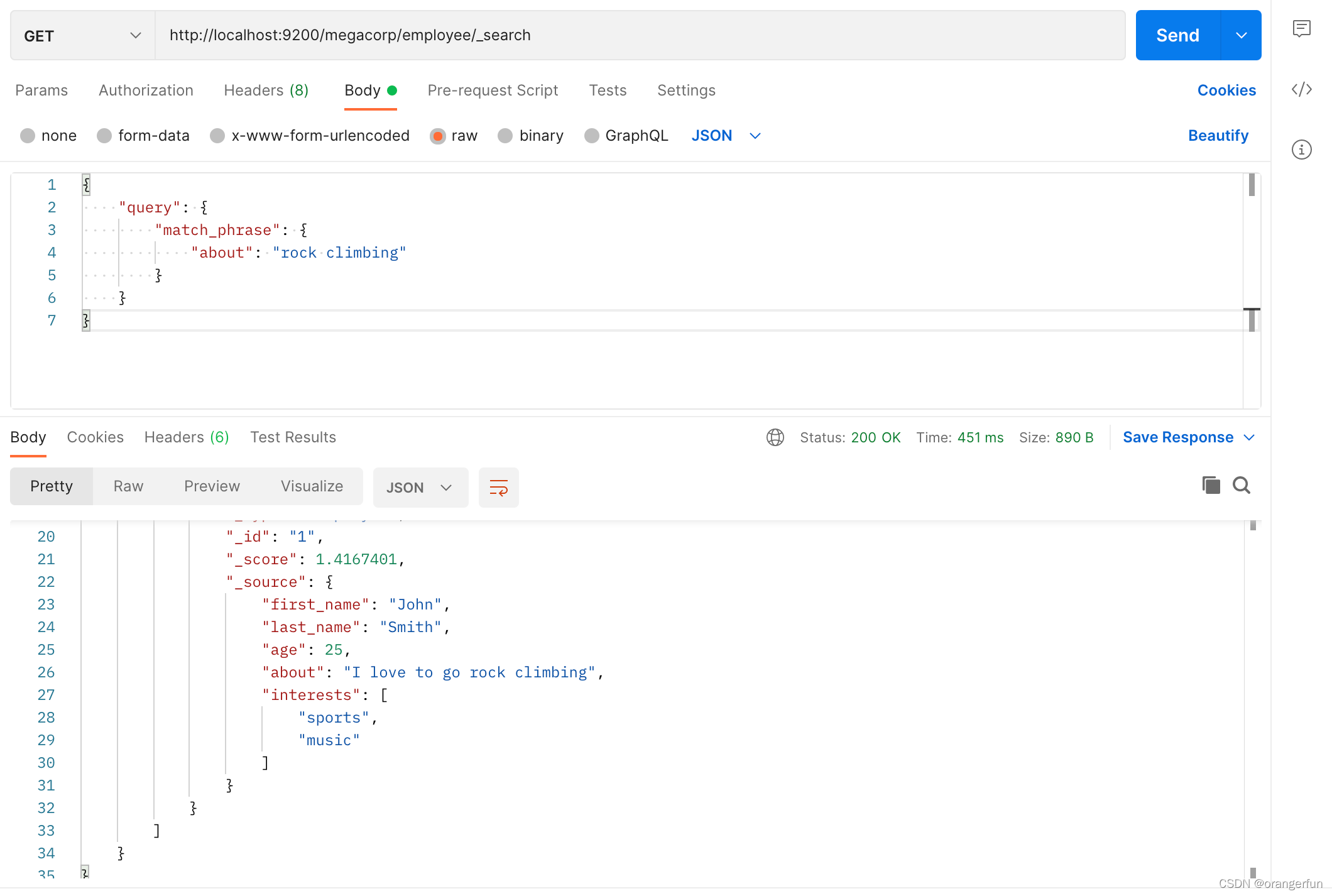
4. 常用语法
4.1 match query
用于搜索单个字段,首先会针对查询语句进行解析(经过 analyzer),主要是对查询语句进行分词,分词后查询语句的任何一个词项被匹配,文档就会被搜到,默认情况下相当于对分词后词项进行 or 匹配操作
GET article/_search
{
"query": {
"match": {
"title": {
"query": "Elasticsearch 查询优化"
}
}
}
}
等同于
GET article/_search
{
"query": {
"match": {
"title": "Elasticsearch 查询优化"
}
}
}
也等同于
GET article/_search
{
"query": {
"match": {
"title": {
"query": "Elasticsearch 查询优化",
"operator": "or"
}
}
}
}
如果要匹配所有关键词使用and
GET article/_search
{
"query": {
"match": {
"title": {
"query": "Elasticsearch 查询优化",
"operator": "and"
}
}
}
}
4.2 match_phrase query
match_phrase query 首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
- 分词后所有词项都要出现在该字段中(相当于 and 操作)
- 字段中的词项顺序要一致
GET test_idx/test_tp/_search
{
"query": {
"match_phrase": {
"desc": "what life"
}
}
}
4.3 term query
term 查询用来查找指定字段中包含给定单词的文档,term 查询语句不被解析,只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精准匹配的需求
GET books/_search
{
"query": {
"term": {
"title": "思想"
}
}
}
4.4 terms query
terms 查询是 term 查询的升级,可以用来查询文档中包含多个词的文档。比如,想查询 title 字段中包含关键词 “java” 或 “python” 的文档,构造查询语句如下:
{
"query": {
"terms": {
"title": ["java", "python"]
}
}
}
4.5 filter query
filter 类似于 SQL 里面的where 语句,和上面的基础查询比起来,也能实现搜索的功能,同时 filter 可以将查询缓存到内存当中,这样可以大大加大下一次的查询速度
下面实现 select document FROM products WHERE price = 20
GET /store/products/_search // store 索引名 products 商品名
{
"query":{
"bool":{
"query":{
"match_all":{} // 匹配所有
}
"filter":{
"term":{
"price":20
}
}
}
}
}
4.6 range query
range query 即范围查询,用于匹配在某一范围内的数值型、日期类型或者字符串型字段的文档,比如搜索哪些书籍的价格在 50 到 100之间、哪些书籍的出版时间在 2015 年到 2019 年之间。使用 range 查询只能查询一个字段,不能作用在多个字段上。
range 查询支持的参数有以下几种:
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
// 查询价格大于 50,小于等于 70 的书籍
GET bookes/_search
{
"query": {
"range": {
"price": {
"gt": 50,
"lte": 70
}
}
}
}
4.7 组合查询[bool query]
bool query(组合查询)是把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现 0 次到多次。
bool query 主要通过下列 4 个选项来构建用户想要的布尔查询,每个选项的含义如下:
- must 文档必须匹配 must 选项下的查询条件,相当于逻辑运算的 AND,且参与文档相关度的评分
- should 文档可以匹配 should 选项下的查询条件也可以不匹配,相当于逻辑运算的 OR,且参与文档相关度的评分
- must_not 与 must 相反,文档 必须不 匹配这些条件才能被包含进来
- filter 和 mysql 中 where 语句功能一样,对查询结果进行限制
GET books/_search
{
"query": {
"bool": {
"filter": {
"term": {
"status": 1
}
},
"must_not": {
"range": {
"price": {
"gte": 70
}
}
},
"must": {
"match": {
"title": "java"
}
},
"should": [
{
"match": {
"description": "虚拟机"
}
}
],
"minimum_should_match": 1
}
}
}
4.8 wildcard 通配符查询
wildcard 查询:允许使用通配符 * 和 ? 来进行查询
*匹配任意一个或多个字符?匹配任意一个字符
GET /library/books/_search
{
“query”:{
"wildcard":{
"preview":"rab*"
}
}
}
4.9 boosting query
boosting 查询用于需要对两个查询的评分进行调整的场景,boosting 查询会把两个查询封装在一起并降低其中一个查询的评分。
boosting 查询包括 positive、negative 和 negative_boost 三个部分,positive 中的查询评分保持不变,negative 中的查询会降低文档评分,negative_boost 指明 negative 中降低的权值。
// 对 2015 年之前出版的书降低评分
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "python"
}
},
"negative": {
"range": {
"publish_time": {
"lte": "2015-01-01"
}
}
},
"negative_boost": 0.2
}
}
}
boosting 查询中指定了抑制因子为 0.2,publish_time 的值在 2015-01-01 之后的文档得分不变,publish_time 的值在 2015-01-01 之前的文档得分为原得分的 0.2 倍。
4.10 sort 排序
使用 price、date 和 _score 进行查询,并且匹配的结果首先按照价格排序,然后按照日期排序,最后按照相关性排序
GET books/_search
{
"query": {
"bool": {
"must": {
"match": { "content": "java" }
},
"filter": {
"term": { "user_id": 4868438 }
}
}
},
"sort": [{
"price": {
"order": "desc"
}
}, {
"date": {
"order": "desc"
}
}, {
"_score": {
"order": "desc"
}
}
]
}
排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,以此类推
5. python中使用es
5.1 使用requests请求操作es
如下图,es中已经存入以下数据,接下来进行增删查改操作

程序如下
import json
import requests
import os
import base64
import logging
LOG_FORMAT = "%(asctime)s %(levelname)s %(message)s"
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT)
def search_es_match(host="localhost", port="9200", index="megacorp", type="employee", id="", operate="search", search_body=dict()):
'''
host/port: ip和端口号
index: 索引名称
type: es中存储数据的类型,可以为空字符串
id: es存储的数据的id, 如果需要删除或者修改该条数据,必须指定id
operate: 进行何种操作: 插入/修改insert, 查询search, 删除delete
'''
op_map = {"search":"_search", "insert":"", "delete":""}
if operate in op_map:
op = op_map.get(operate)
else:
logging.warn("没有该操作类型: %s"%operate)
return -1
search_url = os.path.join(f"http://{host}:{port}", index, type, id, op )
# 有密码时候带上用户及密码
# auth = str(base64.b64encode(f'{self.username}:{self.password}'.encode('utf-8')), 'utf-8')
# 请求头中带有Authorization
headers = {
"Content-Type": "application/json",
# 'Authorization': f'Basic {auth}'
}
data = json.dumps(search_body)
requests.DEFAULT_RETRIES = 5 # 增加重试连接次数
s = requests.session()
s.keep_alive = False # 关闭多余连接
if operate == "delete":
r = requests.delete(search_url, headers=headers)
else:
r = requests.post(search_url, data=data, headers=headers)
return r.json()
if __name__ == "__main__":
data = {
"query":{
"bool":{
"filter":{
"term":{
"last_name":"smith"
}
},
"must":{
"range":{
"age":{
"gt":25
}
}
},
"should":{
"match":{
"about": "like to"
}
}
}
}
}
data2 = {
"first_name": "Li",
"last_name": "Bai",
"age":72,
"about": "chuang qian ming yue guang"
}
data3 = {
"first_name": "Li",
"last_name": "Bai",
"age":72,
"about": "chuang qian ming yue guang, yi shi di shang shuang"
}
# 插入新数据
ret1 = search_es_match(id="110", operate="insert", search_body=data2)
print(ret1)
# 修改数据
ret2 = search_es_match(id="110", operate="insert", search_body=data3)
print(ret2)
# 删除数据
ret3 = search_es_match(id="110", operate="delete")
print(ret3)
# 查询数据
ret4 = search_es_match(operate="search", search_body=data)
print(ret4)
插入数据
ret1 结果
{'_index': 'megacorp', '_type': 'employee', '_id': '110', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 15, '_primary_term': 5}

修改数据结果
ret2 结果
{'_index': 'megacorp', '_type': 'employee', '_id': '110', '_version': 2, 'result': 'updated', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 16, '_primary_term': 5}

修改内容时,其他不修改的内容也需写入body中,否则默认会赋空值
删除数据结果
ret3 结果
{'_index': 'megacorp', '_type': 'employee', '_id': '110', '_version': 3, 'result': 'deleted', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 17, '_primary_term': 5}

查询数据
{'took': 121,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 1, 'relation': 'eq'},
'max_score': 2.257855,
'hits': [{'_index': 'megacorp', '_type': 'employee', '_id': '2', '_score': 2.257855, '_source': {'first_name': 'Jane', 'last_name': 'Smith', 'age': 32, 'about': 'I like to collect rock albums', 'interests': ['music']}}]}}
5.2 使用 Elasticsearch 包
参考 python 操作 ElasticSearch 入门
python操作ES数据库
6. 踩坑记录
6.1 es中的term和match的区别
现在es中存储了如下数据

现在用filter方法来查询 last_name=Smith 的数据,如下图,却未查询到相关的数据
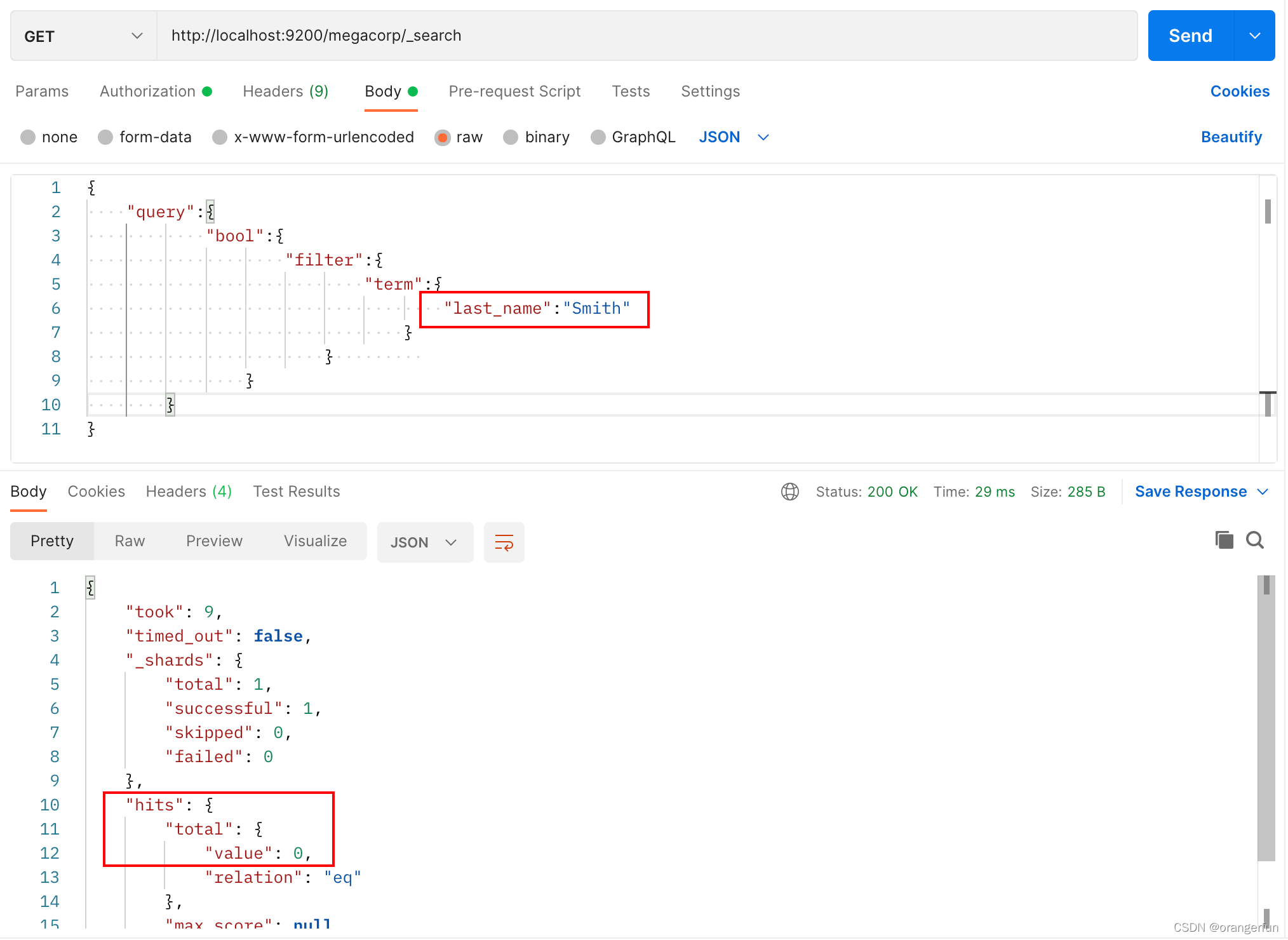
我们再把 term 换成 match 方法,可以发现能够查询到两个结果
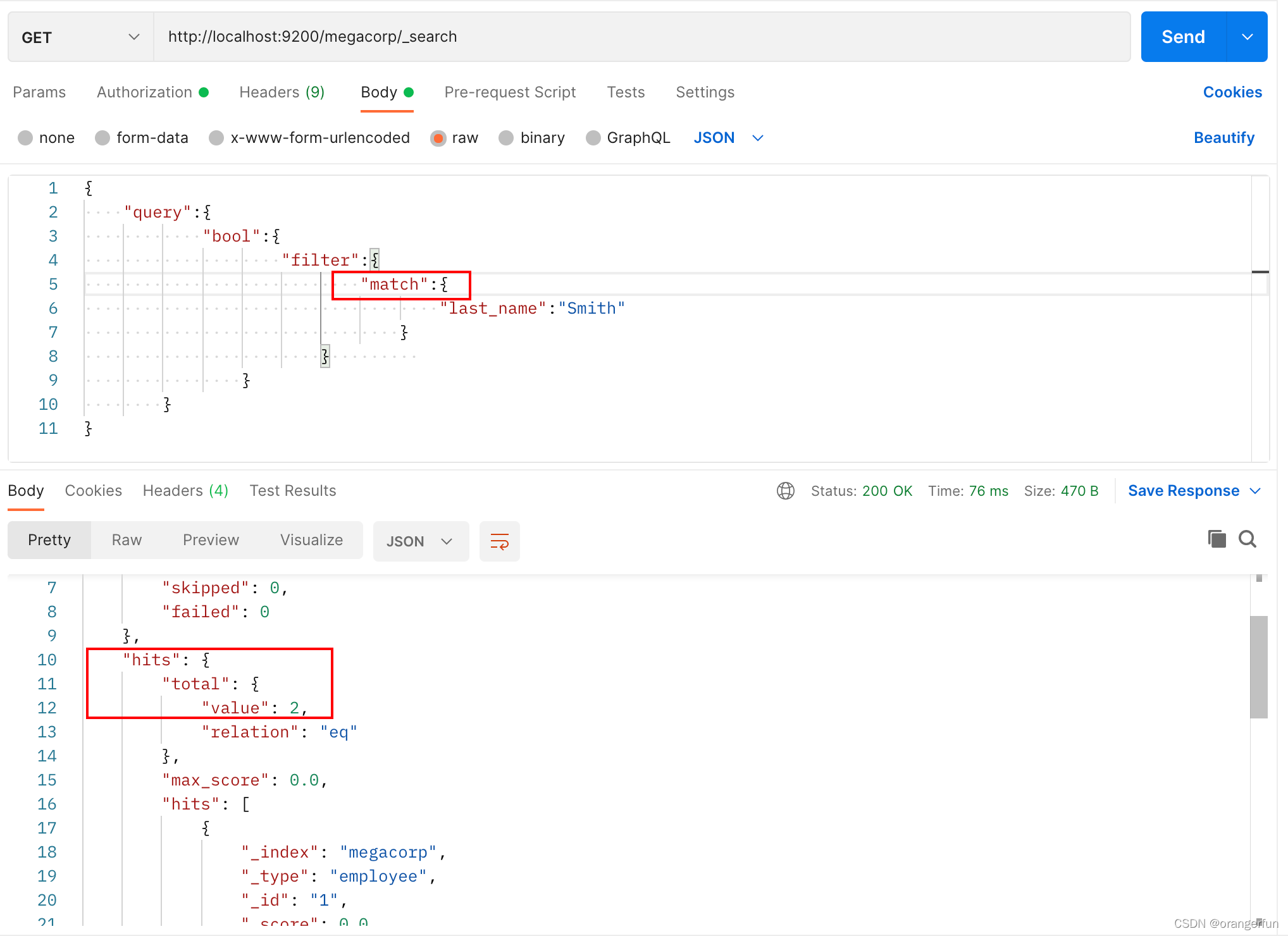
原因
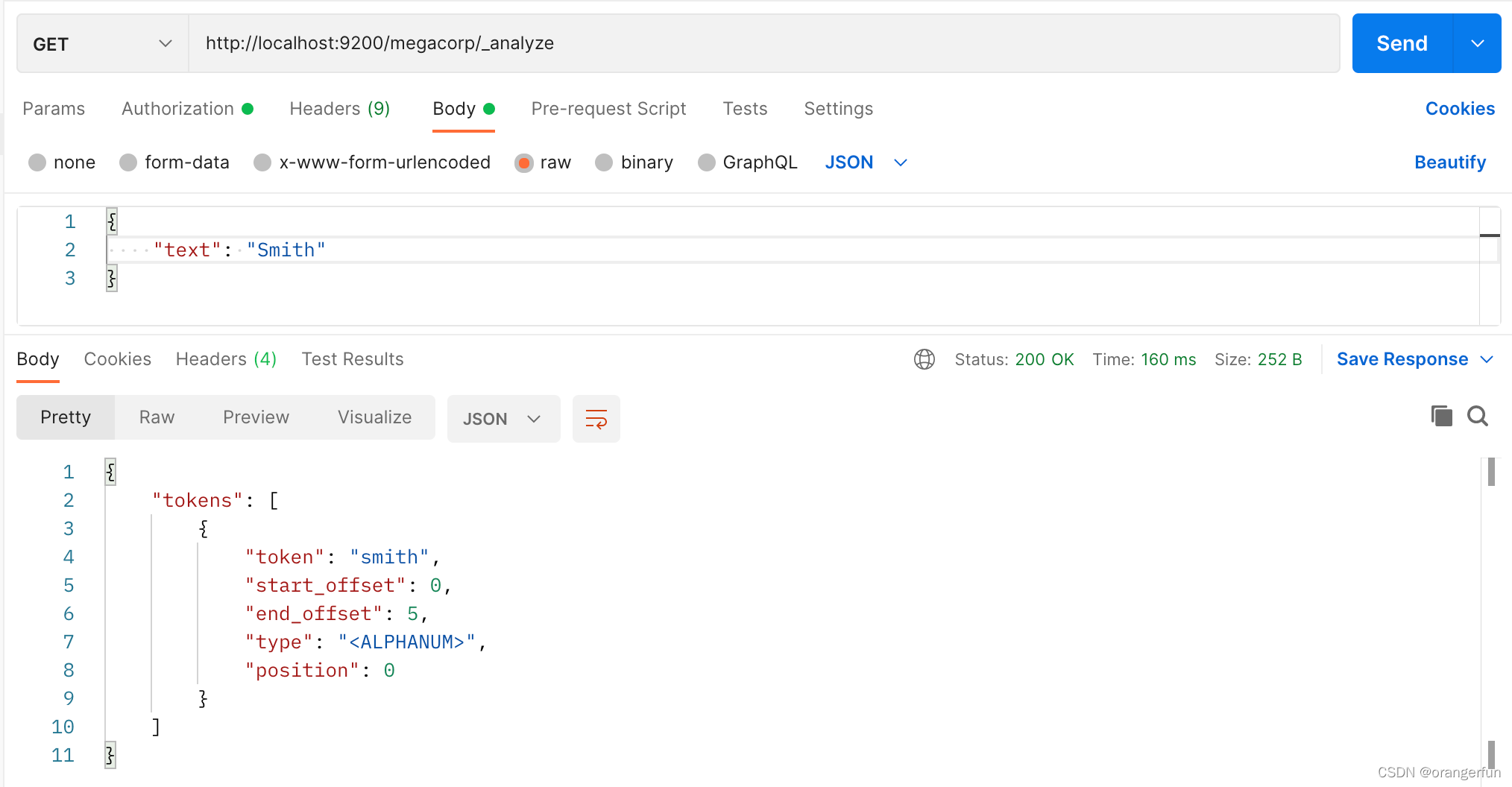
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词拆解,但是Smith这个词在进行存储的时候,进行了分词处理,这里使用的是默认的分词处理器进行了分词处理,使得存入的时候将Smith 存成了 smith, 如下图所示,我们用_ananlyze方法查看存入形式:
因此我们在用 term 方法查询时,应该查询smith,如下图所示,查询到2个结果
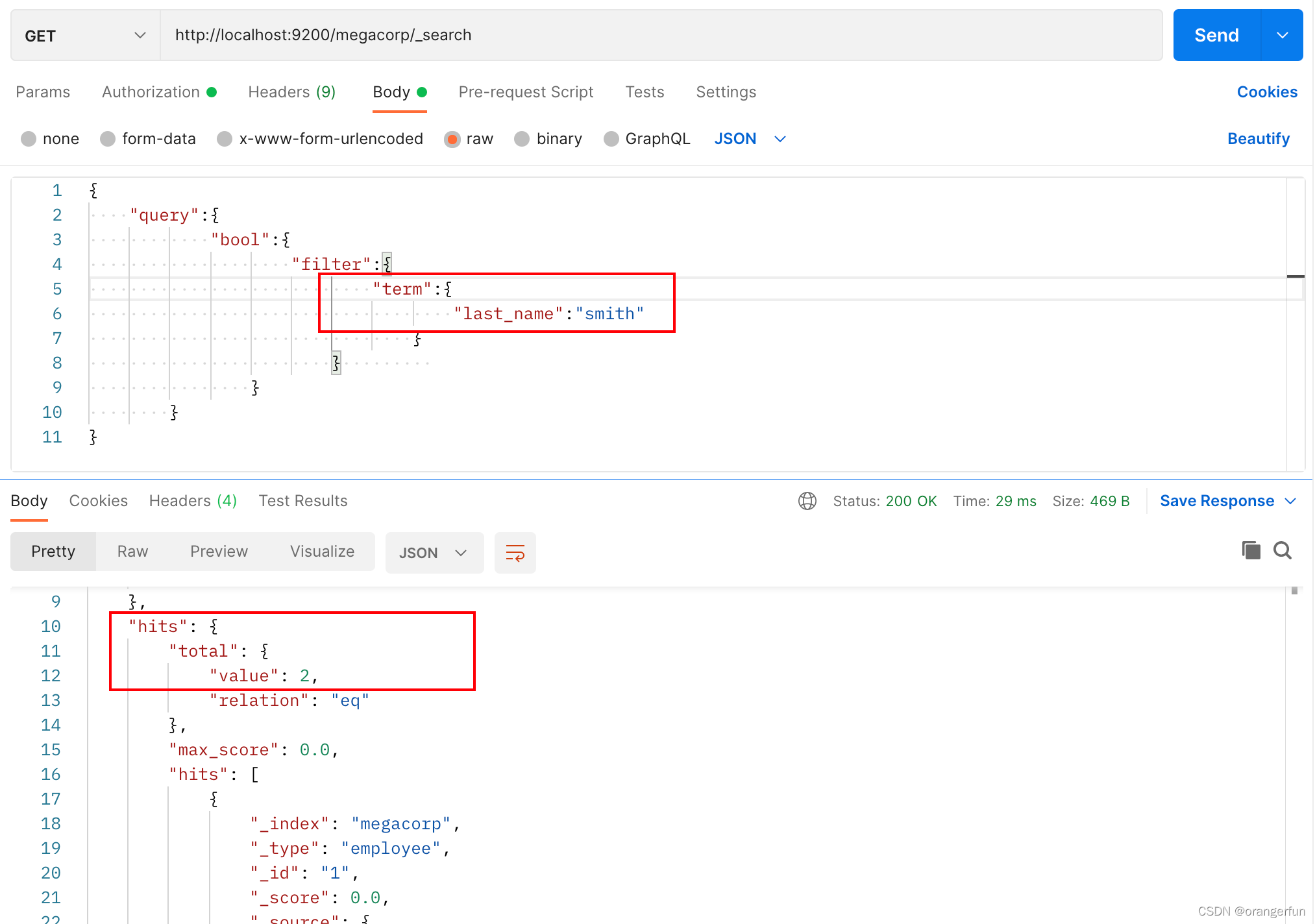
所以,在默认分词方式下,使用term来精确查询需要全部用小写字母来查询


















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









