




 本文介绍了两种主要的问答系统:基于信息检索的问答系统和基于知识的问答系统。基于信息检索的系统通过检索相关文档并从中抽取答案,而基于知识的系统则将问题转化为逻辑表示并查询数据库。此外,还详细探讨了神经网络在答案抽取中的应用,包括基于BiLSTM和BERT的阅读理解算法。
本文介绍了两种主要的问答系统:基于信息检索的问答系统和基于知识的问答系统。基于信息检索的系统通过检索相关文档并从中抽取答案,而基于知识的系统则将问题转化为逻辑表示并查询数据库。此外,还详细探讨了神经网络在答案抽取中的应用,包括基于BiLSTM和BERT的阅读理解算法。
1. 概述
两种方法:
基于信息检索的问答系统 IR-based question answering 和 基于知识的问答系统 knowledge-based question answering
IR-based question answering:
给一个用户的问题,首先通过信息检索方法找到相关的文档或短文,然后使用阅读理解算法阅读这些被检索到的文档直接由span of text产生一个答案。
knowledge-based question answering
该系统并非是构建问题的语义表示(向量),而是将What states borderTexas?映射到逻辑表示:x.state(x)^borders(x,texas),或者将When was Ada Lovelace born?映射到gapped relation: birth-year (Ada Lovelace, ?x), 然后这些表示将被用于请求数据库
2. IR-based Factoid Question Answering
下图展示了IR-based Factoid Question Answering系统的三个阶段:
- 问题处理阶段( question processing)
- 文章检索及排序(passage retrieval and ranking)
- 答案抽取(answer extraction)
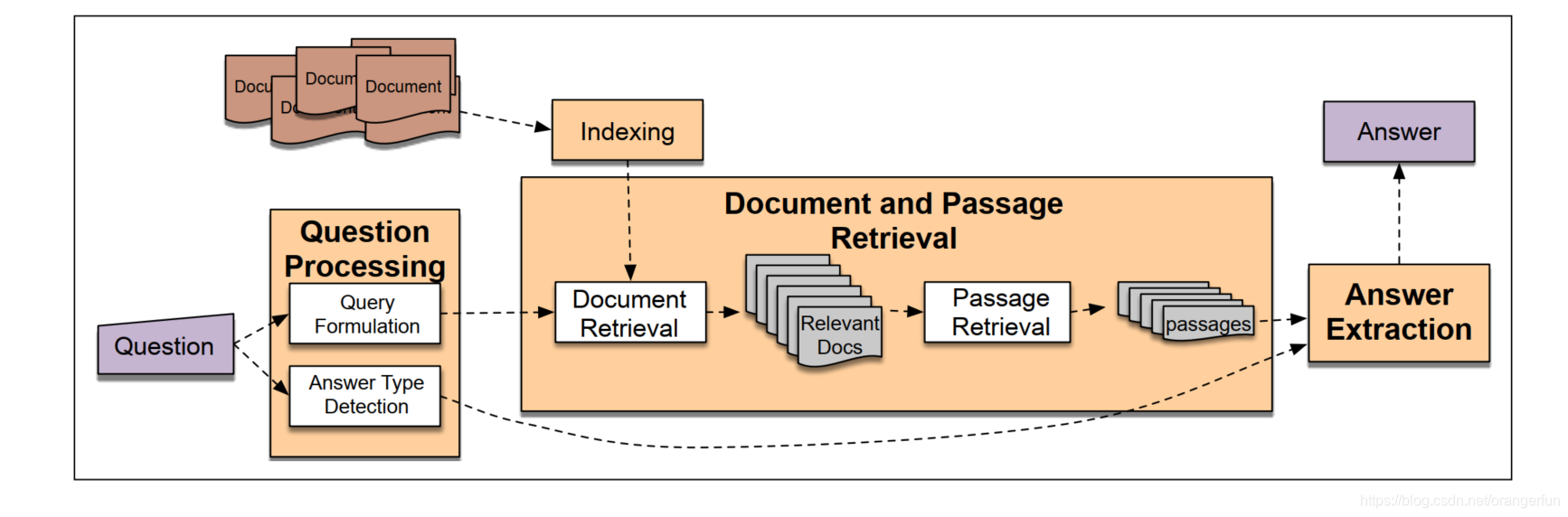
2.1 Question Processing
该阶段的主要目的是提取一些关键字(query),用于送入信息检索系统去匹配文档。当然有些系统也会抽取其他信息,如:
- 答案类型(answer type):person, location, time, etc.
- 问题类型(question type):the question is a definition question, a math question, a list question?
- 中心点(focus):问题中的很有可能被答案替换的词
例如:question: Which US state capital has the largest population?
query: “US state capital has the largest population”
answer type: city
focus: state capital
2.1.1 query formulation
Query formulation is the task of creating a query—a list of tokens— to send to an information retrieval system to retrieve documents that might contain answer strings.
例如:
when was the laser invented? >>> the laser was invented
where is the Valley of the Kings?>>>the Valley of the Kings is located in
2.1.2 Answer Types
问题像Who founded Virgin Airlines?期望得到答案是PERSON
而“What Canadian city has the largest population?”期望得到CITY
3. Neural Answer Extraction
神经网络答案提取器经常设计成上下文的阅读理解任务
3.1 A bi-LSTM-based Reading Comprehension Algorithm
阅读理解问题是给定一个有 l l l 个单词 q 1 , q 2 , . . . , q l q_1, q_2, ... , q_l q1,q2,...,ql 组成的问题 q q q 和由 m m m 个单词 p 1 , p 2 , . . . , p m p_1, p_2, ..., p_m p1,p2,...,pm 组成的文章 p p p ,目的是计算每一个单词 p i p_i pi 是答案的起点和终点的概率
下图展示了阅读理解系统结构
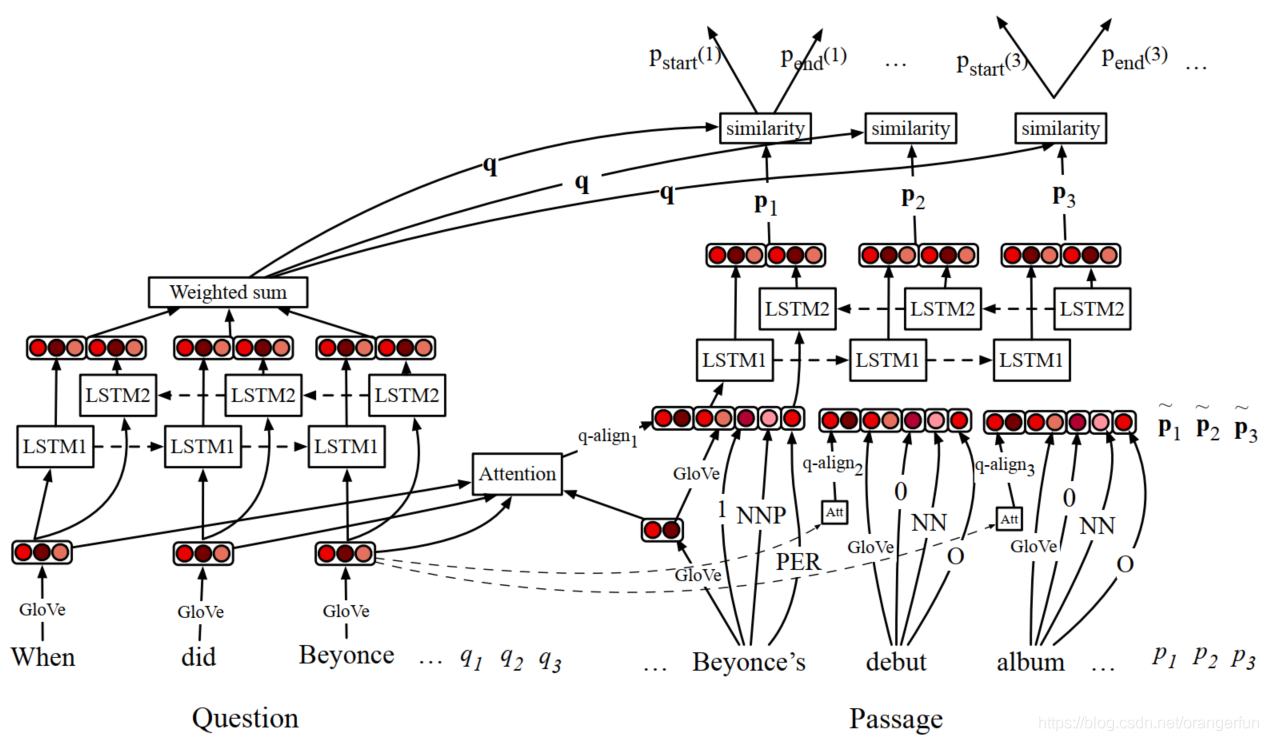
和大部分系统一样,该系统将问题表示成向量,将文章中的每个单词表示成向量,计算问题向量和每个文章单词向量的相似度,然后使用相似度得分决定答案的起点和终点。
算法细节
问题被表示成单独的向量 q q q,该向量是问题中每个单词向量 q i q_i qi 的加权和
q = ∑ j b j q j \mathbf{q}=\sum_{j} b_{j} \mathbf{q}_{j} q=j∑bjqj
其中, 权重 b j b_j bj是每个问题单词的相关性的度量,它是由一个学习得到的向量 w w w计算得到的:
b j = exp ( w ⋅ q j ) ∑ j ′ exp ( w ⋅ q j ′ ) b_{j}=\frac{\exp \left(\mathbf{w} \cdot \mathbf{q}_{j}\right)}{\sum_{j^{\prime}} \exp \left(\mathbf{w} \cdot \mathbf{q}_{j}^{\prime}\right)} b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









