



 本文介绍使用PySpider爬虫框架抓取不包含img节点的HTML文档的方法。针对某些需要通过JavaScript渲染才能显示图片的情况,文章提供了一种解决方案,即在抓取链接时将fetch_type参数设置为'js'。
本文介绍使用PySpider爬虫框架抓取不包含img节点的HTML文档的方法。针对某些需要通过JavaScript渲染才能显示图片的情况,文章提供了一种解决方案,即在抓取链接时将fetch_type参数设置为'js'。
《2018年8月19日》【连续321天】
标题:pyspider使用;
内容:
pyspider:
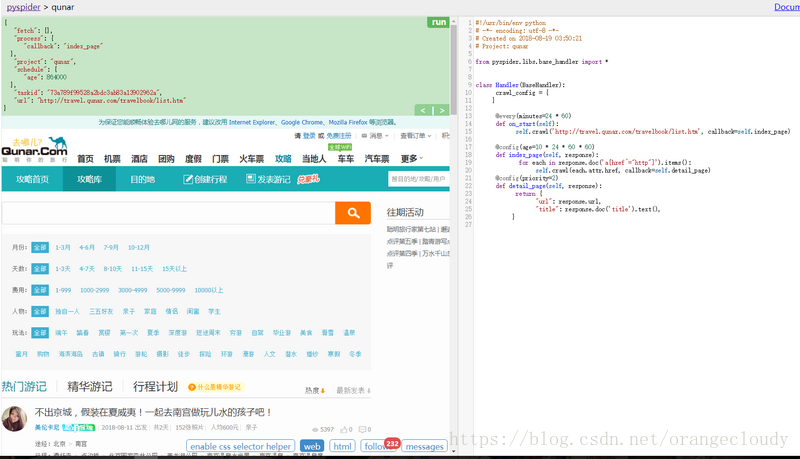
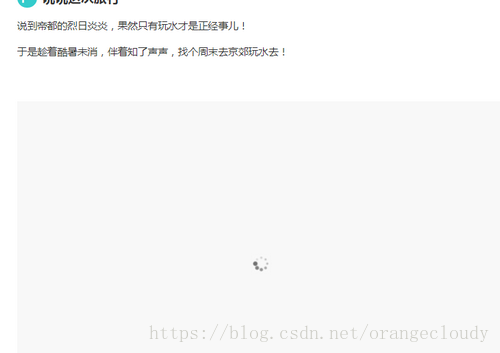
由于html文档不包含img节点,所以当直接web预览时:
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page)
next =response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)
此时修改参数即可:
self.crawl(each.attr.href, callback=self.detail_page,fetch_type='js')


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









