



 本文介绍如何使用PyQuery库优化京东商品信息的爬取过程,并将爬取到的数据存储到本地文件中。通过具体代码示例展示了如何解析商品价格、名称及链接。
本文介绍如何使用PyQuery库优化京东商品信息的爬取过程,并将爬取到的数据存储到本地文件中。通过具体代码示例展示了如何解析商品价格、名称及链接。
《2018年8月19日》【连续290天】
标题:结合pyquery和文件储存优化昨天的例子;
内容:
1.pyquery与其它的解析库使用逻辑基本相同:
对之前的京东商品爬取做的优化:
from pyquery import PyQuery as pq
def print_goods(r):
doc =pq(r.text)
d =doc('#J_goodsList ul li')
for i in d.items():
d1 =i('.p-price strong i')
d2 =i('.p-name a')
file =open('name.txt','a',encoding='utf-8')
file.write('\n'.join([d2.text(),"http:"+str(d2.attr.href),"¥"+d1.text()]))
file.write('\n'+'='*50+ '\n')
结合之前的代码,将print_goods函数修改掉,
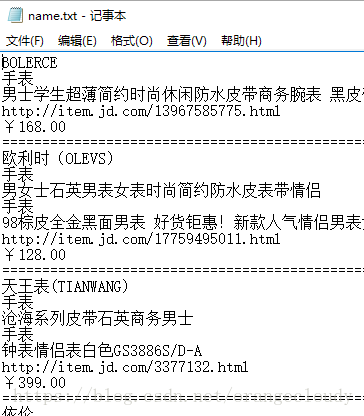
效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









