



 本文介绍了一种爬取Bilibili网站新番播放时间表的方法,通过解析网页源代码并使用Python的requests和json库来获取数据。代码实现了抓取指定URL的数据,并按日期、时间、集数及番剧名称的格式输出。
本文介绍了一种爬取Bilibili网站新番播放时间表的方法,通过解析网页源代码并使用Python的requests和json库来获取数据。代码实现了抓取指定URL的数据,并按日期、时间、集数及番剧名称的格式输出。
标题:bilibili新番时间表爬取;
内容:
今天练习爬取bilibili新番时间表:
网址:https://www.bilibili.com/anime/timeline/
进入源代码:

时间表是用js生成的,于是检查元素:
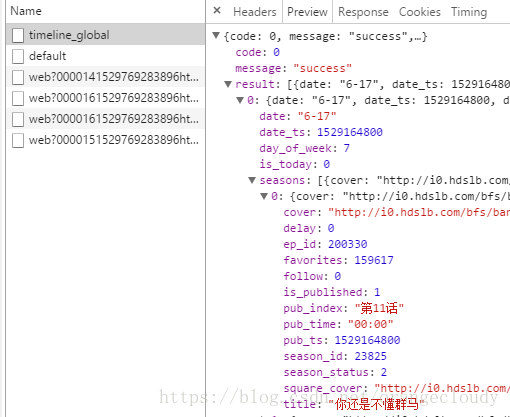
基本上需要的东西到找到了,
端口:https://bangumi.bilibili.com/web_api/timeline_global
于是代码如下:
import requests
import json
url='https://bangumi.bilibili.com/web_api/timeline_global'
wbdata =requests.get(url).text
data =json.loads(wbdata)
anime =data['result']
tplt ="{:4}\t{:6}{:8}\t{:20}"
print(tplt.format("日期","时间","集数","番名"))
tplt ="{:4}\t{:6}\t{:8}\t{:20}"
for i in anime:
date =i.get('date')
seasons =i['seasons']
for n in seasons:
index =n.get('pub_index')
time =n.get('pub_time')
title =n.get('title')
print(tplt.format(date,time,str(index),title))
#index用str是因为它有可能是None


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









