



 本文回顾了搜索引擎的发展历程,从1990年的Archie到Google和百度等现代搜索引擎的出现。详细介绍了搜索引擎的工作原理及其分类,并重点解析了Google的PageRank算法,包括其计算思想和优化方法。
本文回顾了搜索引擎的发展历程,从1990年的Archie到Google和百度等现代搜索引擎的出现。详细介绍了搜索引擎的工作原理及其分类,并重点解析了Google的PageRank算法,包括其计算思想和优化方法。
《2018年3月13日》【连续153天】
标题:网络搜索问题;
内容:
A.搜索引擎:
a.历史:
1.雏形:
·1990,Archie(档案检索系统);
·1993,蜘蛛程序(Spider):一开始是为了统计服务器数量,后来可以捕获URL;
2.第一代搜索引擎:
·1994,Yahoo!的目录搜索引擎:建立自己的网络指南信息库,将网页分类,按主题进行分类索引,形成一个树形分类结构体系,
人工分类,因网页数量爆炸增加,工作量巨大,且无法根据网页内容进行搜索(2002年放弃);
3.第二代搜索引擎:
使用蜘蛛程序在网络上自动捕获网页;
·1998,Google创立,99年提供搜索服务,推出PageRank,动态摘要,网页快照等功能革新;
·2000年,百度成立;
·2004年,Yahoo!重新推出新的搜索引擎;
b.分类:
1.分类目录;
2.全文搜索:
·拥有自己的检索程序,俗称“蜘蛛程序”,建立自己的网页数据库:
如:Google,百度;
·租用其它搜索引擎的数据库,并按自定的格式排列搜索结果,如Lycos;
·自动网页搜集:
如Google一般是28天;
或网页所有者主动向搜索引擎提供网址;
3.元搜索:关于搜索引擎的搜索引擎;
4.垂直;
5.集合式;
6.门户;
7.免费链接列表;
B.工作原理:
1.全文:
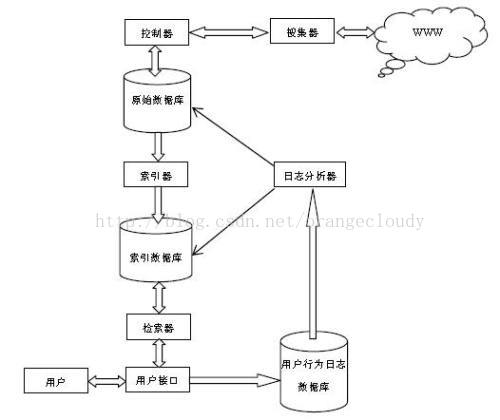
构成:搜索器,索引器,检索器,用户接口;
C.PageRank算法:
思想:
1.根据接入链接的数量和重要性;
2.根据外部链接和内部链接的数量和质量来觉得决定网页的重要性;
网页链接关系:
正向链接和反向链接;
计算思想:
1)在初始阶段:网页通过链接关系构建起Web图,每个页面设置相同的PageRank值,通过若干轮的计算,会得到每个页面所获得的最终PageRank值。随着每一轮的计算进行,网页当前的PageRank值会不断得到更新。
2)在一轮中更新页面PageRank得分的计算方法:在一轮更新页面PageRank得分的计算中,每个页面将其当前的PageRank值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值。而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的PageRank得分。当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
优化:1.来自链接工厂的网站不提供网页的PageRank,2.内容不相关的网页不提供PageRank,3降低PageRank的更新频率’


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









