



 本文介绍了如何在VisualStudio中,利用正则表达式`<[^>]+>`来定位并替换XML文件中特定标签内的内容,以保留中文字符,如登录、取消和实时成像。
本文介绍了如何在VisualStudio中,利用正则表达式`<[^>]+>`来定位并替换XML文件中特定标签内的内容,以保留中文字符,如登录、取消和实时成像。
有 xml的字典如下:
<sys:String x:Key="ButtonLogin">登录</sys:String>
<sys:String x:Key="ButtonCancel">取消</sys:String>
<sys:String x:Key="ButtonLive">实时成像</sys:String>
想替换<>中的内容,只留下中文,如下:
登录
取消
实时成像
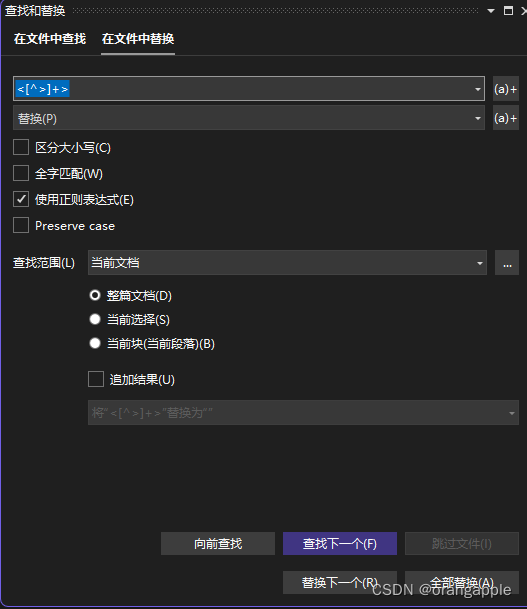
用正则表达式 <[^>]+>
在visual studio 里,用查找和替换中的替换,如下图所示:


















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











