




前言:
在2025年的技术浪潮中,AI助手已从“工具”演变为“伙伴”,成为个人生产力与生活管理的核心枢纽。在日常生活中,每个人都有着自己记录的事情,如工作,生活等等,那么我们也可以搭建一个属于自己的AI,即可以保护自己的隐私,也可以方便我们记录未来及回顾过去......
如何搭建自己的AI助手:
废话不多说,接下来就讲解安装过程,我这边主要用到了一下软件及模型:
ollama+qwen+docker+openwebui+bge-m3
ollama:本地大语言模型(LLM)运行框架,主要功能是简化大模型在个人设备上的部署和管理。简单理解就是为了安装及使用大语言模型。
qwen2.5-3b:阿里云 Qwen 团队推出的轻量级多模态语言模型。这个就相当于人的大脑,存储了大量知识及回答问题的逻辑。
docker:一个开源的容器化平台,用于快速构建、打包、部署和运行应用程序。这里主要作用就是安装open webui。
openwebui:一个开源、可扩展的 AI 交互平台。
bge-m3:通用语义向量模型。用于解析问题及解析知识库。也就是为大语言模型提供高质量外部知识检索,也就是常说的检索增强(RAG)。
安装环境:win10系统2022H2及以上内核版本。
第一步:安装ollama
1、双击运行“OllamaSetup.exe”安装文件,全程默认安装即可。
安装文件可在官网直接下载
2、配置ollama环境变量
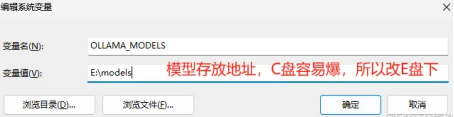
OLLAMA_HOST
0.0.0.011434
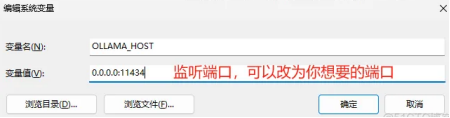
OLLAMA_ORIGINS
*
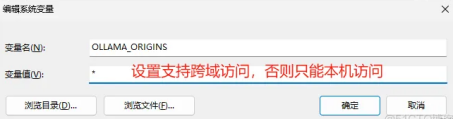
OLLAMA_MODELS
D:\models
其他环境变量配置解释:
(1)OLLAMA_ MODELS :模型文件存放目录,如果是 Windows系统建议修改(如: D:\OllamaModels),避免 C盘空间吃紧
(2)OLLAMA_ HOST : Ollama服务监听的网络地址,默认为127.0.0.1 ,如果允许其他电脑访问Ollama (如:局域网中的其他电脑) , 建议设置成0.0.0.0,从而允许其他网络访问
(3)OLLAMA_ PORT : Ollama服务监听的默认端口, 默认为11434 ,如果端口有冲突,可以修改设置成其他端口(如: 8080等)
(4)OLLAMA_ ORIGINS : HTTP客户端请求来源半角逗号分隔列表 ,若本地使用无严格要求 可以设置成星号,代表不受限制
(5)OLLAMA_ KEEP_ ALIVE :大模型加载到内存中后的存活时间,默认为5m即5分钟(如:纯数字如300代表300秒, 0代表处理请求响应后立即卸载模型,任何负数则表示一直存活) ; 我们可设置成24h,即模型在内存中保持24小时,提高访问速度
(6)OLLAMA_ NUM_ PARALLEL :请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
(7)OLLAMA MAX_ QUEUE :请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
(8)OLLAMA _DEBUG :输出Debug日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
(9)OLLAMA. MAX_ LOADED_ MODELS :最多同时加载到内存中模型的数量,默认为1,即只能有1个模型在内存中
(10)OLLAMA_SCHED_SPREAD: 始终跨所有 GPU 调度模型。(显卡资源使用不均横:设置环境变量OLLAMA_SCHED_SPREAD为1即可。)
(11)加速计算:FlashAttention是一种优化的注意力机制,用于加速深度学习模型中常见的自注意力计算,尤其是在Transformer架构中。它通过改进内存访问模式和计算策略,显著提高了计算效率和内存使用率。
可以通过设置环境变量OLLAMA_FLASH_ATTENTION为1,开启该选项。
第二步:导入 GGUF 模型文件到本地磁盘(以qwen2.5-3b-instruct-q8_0.gguf为例,文件在官网下载)
1、新增NAME.Modelfile文本文件,加入以下配置
FROM C:\qwen2.5-3b-instruct-q8_0.gguf #必填项目,说明使用模型来源
SYSTEM """你是谁谁谁,该做什么。""" #给模型定义角色
TEMPLATE """{{- if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{- if .System }}
{{ .System }}
{{- end }}""" #对话模版,建议拷贝官网模版
PARAMETER temperature 0.7 (范围0-1,越大输出回答越随机)
2、在命令窗口执行创建模型命令
ollama create qwen2.5-3b -f D:\models\NAME.Modelfile
3、在cmd命令窗口中输入ollama run qwen2.5-3b 运行模型
第三步:安装Docker(具体过程就不写了)
1、安装适用于 Linux 的 Windows 子系统(WSL)
略
2、安装Docker Desktop
略
第四步:安装openwebui,导出及导入本地镜像
由于网上都是在线安装,离线安装的话需要在已安装好的容器中导出镜像,再离线导入。
导出本地镜像:“docker save ghcr.io/open-webui/open-webui:main > D:\open-webui.tar”其中“ghcr.io/open-webui/open-webui”为repository,“main”为tag。可通过“docker images”命令查看镜像repository和tag。
导入本地镜像:“docker load < D:\open-webui.tar”
第五步:安装bge-m3
略
第六步:浏览器进入open webui,注册用户
第七步:关闭openai api,配置ollama api连接,链接如下:
http://host.docker.internal:11434
第八步:设置文档配置
设置—管理员设置—文档—修改向量模型为bge-m3:latest
第九步:新增知识库
第十步:新建模型

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









