



乐观学习,乐观生活,才能不断前进啊!!!
我的主页:optimistic_chen
我的专栏:c语言
点击主页:optimistic_chen和专栏:c语言,
创作不易,大佬们点赞鼓励下吧~

前言
通过这些之前的博客:
相信我们对链表已经有了一个模糊了认识,这篇博客将详细为你解释数据结构——链表的“身世”
1.链表概念
链表是一种物理储存结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
类似于火车车厢,可随时增加或者减少,并且不会影响其他车厢,每一个车厢都独立存在,那要顺利通过每一节车厢,就需要我们拥有下一节车厢的钥匙。
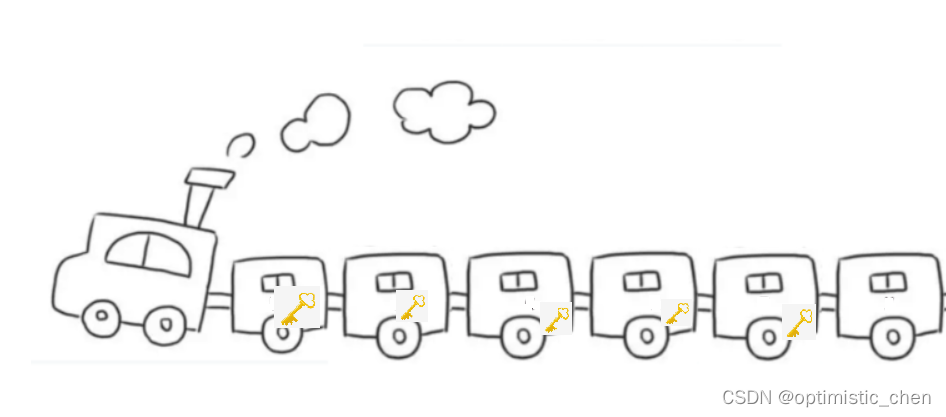
那么每节车厢里只存放了🔑吗?当然不是,那样的话,链表的意义在何处体现呢?
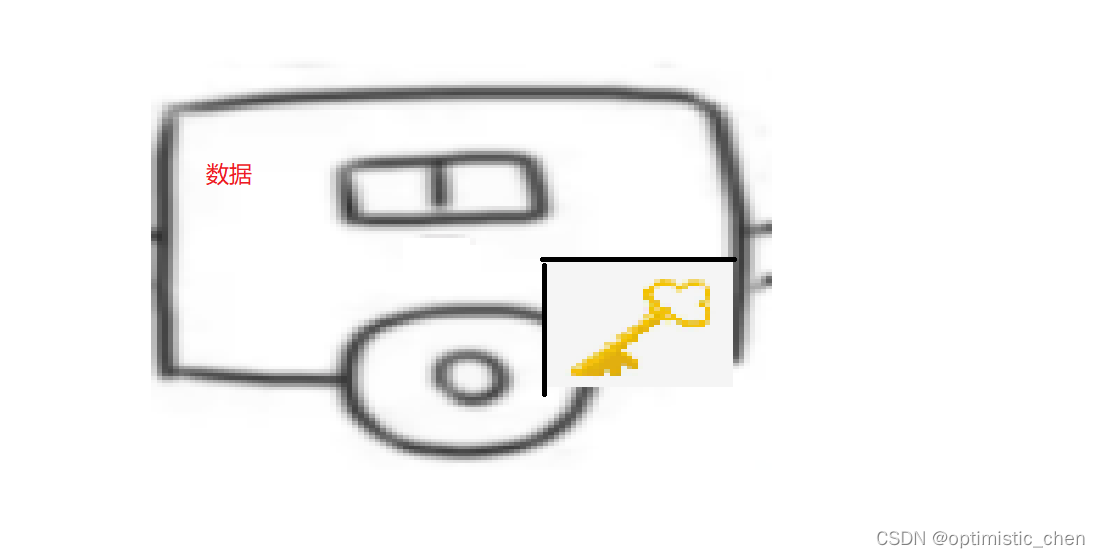
这样的“车厢”看起来可能有点草率,那么我们继续将链表变得更加直观,更加贴近我们程序员。
2.链表结构

与之前顺序表不同的是,链表里的每节“车厢”都是独立申请下来的空间 ,我们称为**”节点“**
显而易见,每一个节点的主要组成有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)
图中指针变量 plist 保存的是第⼀个节点的地址,我们称plist此时“指向”第⼀个节点,如果我们希望 plist“指向”第⼆个节点时,只需要修改plist保存的内容为0x0012FFA0。
指针变量的作用?
链表中每个节点都是独⽴申请的(即需要插⼊数据时才去申请⼀块节点的空间),我们需要通过指针
变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。(注意:最后一个节点的”钥匙“为NULL)
3.链表的打印
结合前面结构体的知识,在给定的链表结构中,如何实现节点从头到尾的打印?
代码示例:
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node *next;
} Node;
void printList(Node *head) {
Node *current = head;//从头节点开始
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
//每次打印完一个节点,指针都指向下一个节点的地址
}
printf("\n");
}
int main() {
Node *head = NULL;//头节点为空
Node *second = NULL;
Node *third = NULL;
head = (Node*)malloc(sizeof(Node));//申请空间
second = (Node*)malloc(sizeof(Node));
third = (Node*)malloc(sizeof(Node));
head->data = 1;//保存数据
head->next = second;//保存下一个节点的地址
second->data = 2;
second->next = third;
third->data = 3;
third->next = NULL;
printList(head);//打印链表
return 0;
}
注意:
1、链式机构在逻辑上是连续的,在物理结构上不⼀定连续
2、节点⼀般是从堆上申请的
3、从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
4.链表的分类
链表的结构有很多种,代表不同的算法。
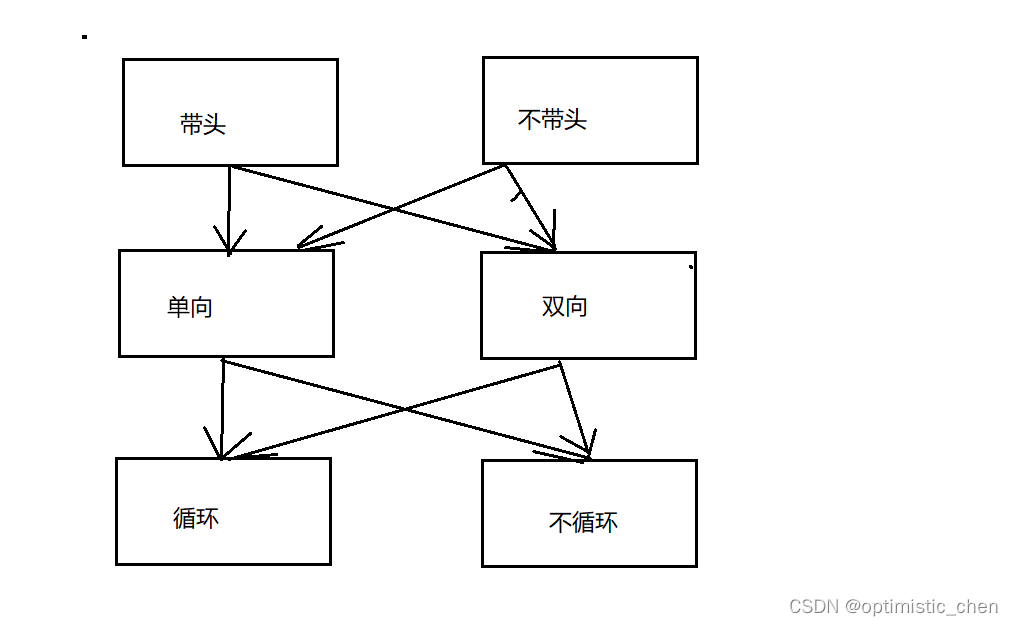
4.1单向或双向
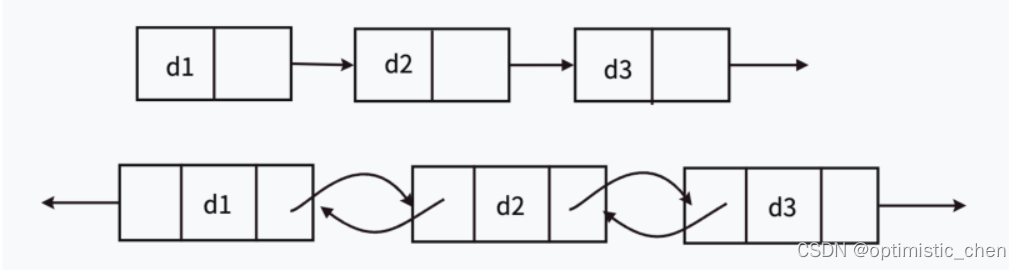
4.2带头或者不带头
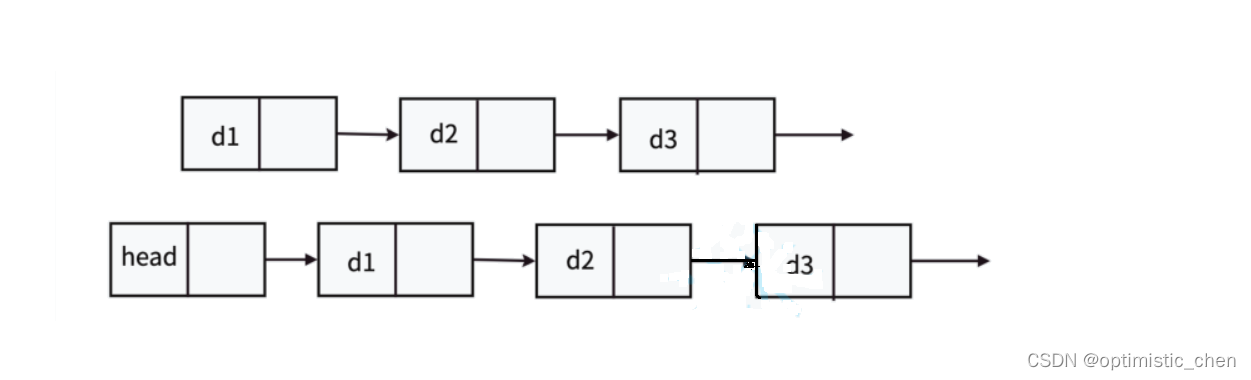
4.3循环或者不循环
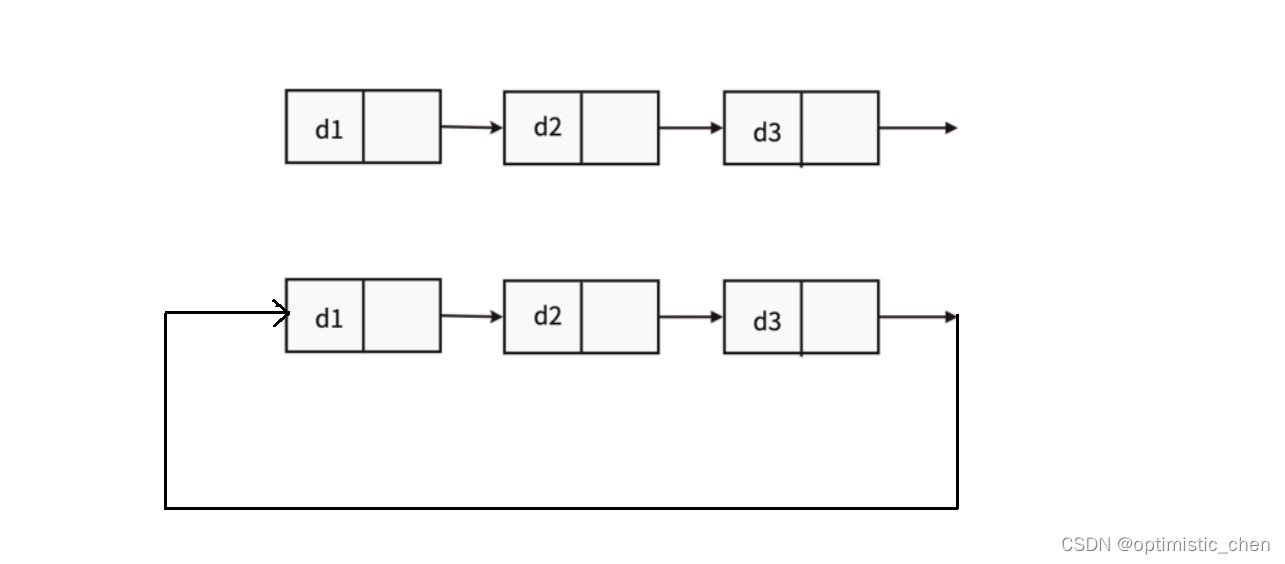
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:单链表 和双向带头循环链表
其他的链表我们后续到数据结构部分就会接触到,这里先不提。
5.双向链表的结构
带头双向循环链表
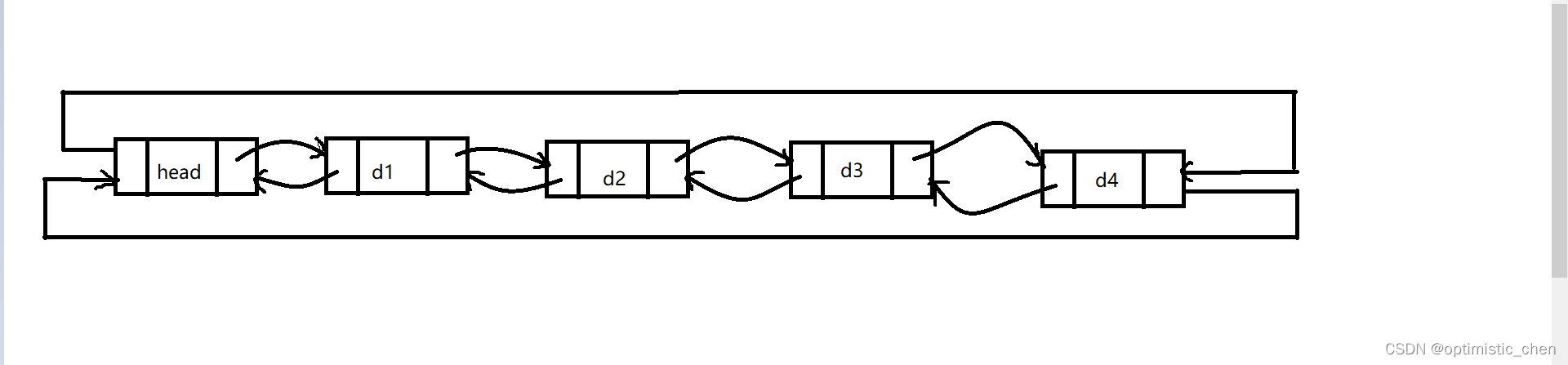
注意:这里的“带头“和前面单链表所说的”头节点“是两个概念,带头链表里的头节点实际是”哨兵位“,哨兵节点不储存任何有效元素。
”哨兵位“的意义:遍历循环链表避免出现死循环。
6.两者区别
| 不同点 | 顺序表 | 链表()单链表 |
|---|---|---|
| 存储空间上 | 物理上连续 | 逻辑上连续 |
| 随机访问 | 支持 | 不支持 |
| 插入或删除元素 | 可能要搬移元素,效率低 | 只需要修改指针指向 |
| 插入 | 空间不够需要扩容 | 没有容量概念 |
| 应用场景 | 元素高效储存,访问频繁 | 任意位置修改 |
完结
好了,这期的分享到这里就结束了~
如果这篇博客对你有帮助的话,可以点一个免费的赞并收藏起来哟~
可以点点关注,避免找不到我~
我们下期不见不散~~
这个链表题目还会继续,敬请期待~


















 384
384







 到【灌水乐园】发言
到【灌水乐园】发言









