 Python快速去除PDF水印:简单十行代码
Python快速去除PDF水印:简单十行代码





 本文介绍了如何使用Python的PyMuPDF库去除PDF文件中的水印。首先,通过查看PDF中水印的RGB值,然后将图片转换为PDF,将水印颜色替换为白色,最后将处理后的图片转回PDF。提供了详细步骤和代码示例。
本文介绍了如何使用Python的PyMuPDF库去除PDF文件中的水印。首先,通过查看PDF中水印的RGB值,然后将图片转换为PDF,将水印颜色替换为白色,最后将处理后的图片转回PDF。提供了详细步骤和代码示例。
用python制作去除 pdf 文件水印脚本
前因后果
弟弟最近要考试,临时抱佛脚在网上找了一堆学习资料复习,这不刚就来找我了,说PDF上有水印,影响阅读效果,到时候考不好就怪资料不行,气的我差点当场想把他揍一顿!

算了,弟弟长大了,看在打不过他的份上,就不打他了~

稍加思索,我想起了Python不是可以去水印?说搞就搞!
去除水印原理
去除方法:
- 用 PyMuPDF 打开 pdf 文件,将 pdf 的每一页都转换为图片 pixmap
- pixmap 有它自己的RGB,只需要将 pdf 水印中的 RGB 改为(255, 255, 255),并保存图片 ;
- 按照生成的图片,插入到pdf文档中;
因为pfd文档无法直接去除水印,需要先将pfd文档转换成图片,在逐一对图片进行水印去除操作,最后在把图片插入到pdf文档中。
代码剖析
1、先查看PDF文档中的水印rgb值是多少
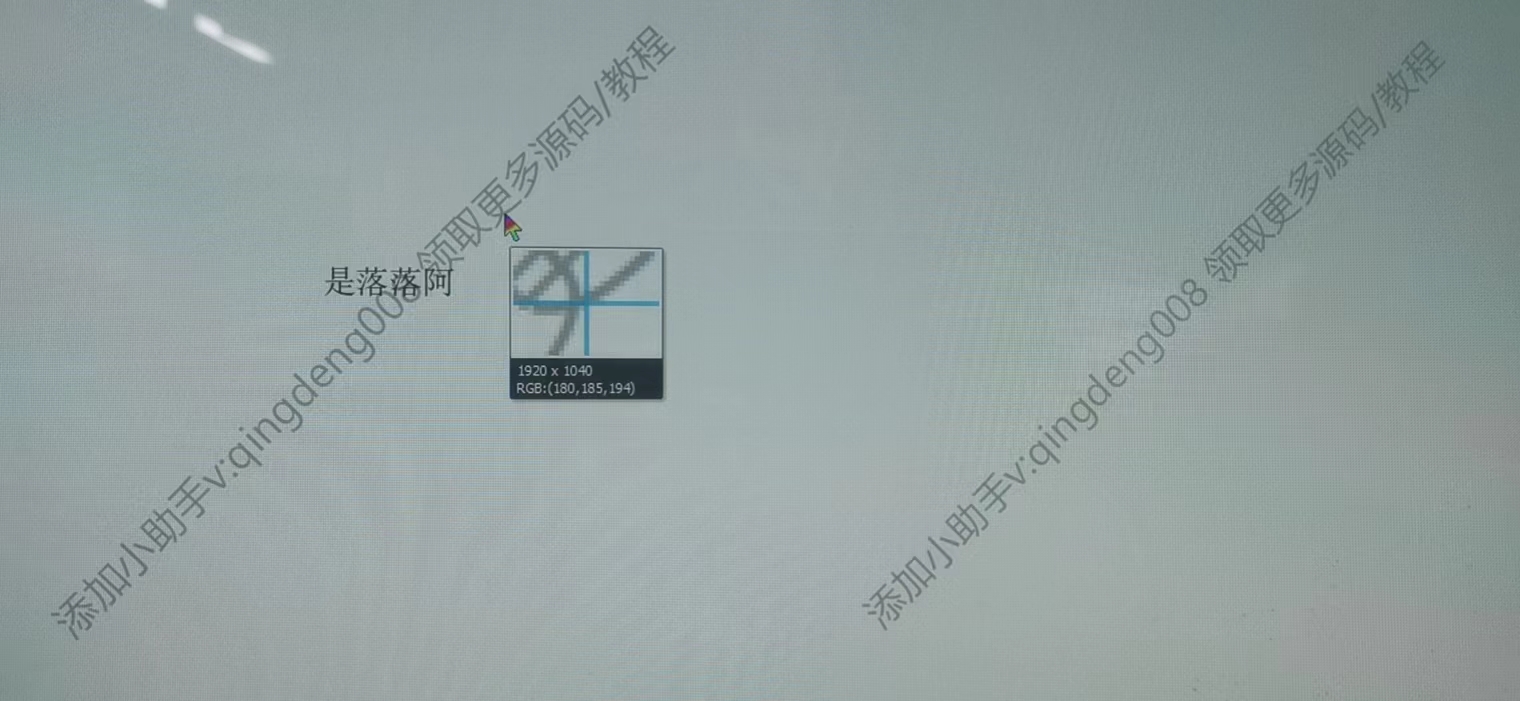
可以看到,RGB(179,179,179),因为这里要的是RGB色值总和,所以我们就认为,超过510,就认为是水印。
敲黑板
光学三原色是红绿蓝(RGB),也就是说它们是不可分解的三种基本颜色,其他颜色都可以通过这三种颜色混合而成,三种颜色等比例混合就是白色,没有光就是黑色。
在计算机中,可以用三个字节表示 RGB 颜色,1个字节能表示的最大数值是 255, 所以,(255, 0, 0)代表红色,(0, 255, 0)代表绿色,(0, 0, 255)代表蓝色。相应地,(255, 255, 255)代表白色,(0, 0, 0)代表黑色。从(0, 0, 0) ~ (255, 255, 255) 之间的任意组合都可以代表一个不同的颜色。
图片每个位置颜色由四元组表示,前三位分别是 RGB,第四位是 Alpha 通道
2、pdf转换成图片,并去除水印
代码示例:
from PIL import Image
from itertools import product
import fitz
# 去除pdf的水印
def remove_pdfwatermark():
#打开源pfd文件
pdf_file = fitz.open("源码找落落阿.pdf")
#page_no 设置为0
page_no = 0
#page在pdf文件中遍历
for page in pdf_file:
#获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB)
#page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片
pix = page.get_pixmap()
#遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色
for pos in product(range(pix.width), range(pix.height)):
if sum(pix.pixel(pos[0], pos[1]))  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 854
854






 到【灌水乐园】发言
到【灌水乐园】发言







