




 知识图谱是一种语义网络,用于连接实体和关系,改善搜索引擎的语义理解能力。它由实体、关系和属性构成,通常用RDF或图数据库存储。构建知识图谱涉及数据抽取、实体识别、关系抽取等NLP技术,应用于搜索、推荐等领域,提供精准的关系分析。知识图谱的推理技术是人工智能发展的重要方向。
知识图谱是一种语义网络,用于连接实体和关系,改善搜索引擎的语义理解能力。它由实体、关系和属性构成,通常用RDF或图数据库存储。构建知识图谱涉及数据抽取、实体识别、关系抽取等NLP技术,应用于搜索、推荐等领域,提供精准的关系分析。知识图谱的推理技术是人工智能发展的重要方向。
一,知识图谱是什么?
知识图谱本质上是语义网络,由节点(point)、边(edge)和属性(property)组成,在知识图图谱里,每个节点表示现实世界中的‘实体’,每条边表示实体与实体之间的‘关系’。也就是说,知识图谱是把所有不同种类的信息连接在一起而得到的一个关系网络。知识图谱提供了从‘关系’角度去分析问题的能力。
知识图谱的概念最早在2012年提出的,当时主要是为了将传统的keyword-base搜索模型向基于语义的搜索升级,以优化现有的搜索引擎。不同于基于关键词搜索的传统搜索引擎,知识图谱可以更好的查询复杂的关联信息,从语义层面理解用户的意图,改进搜索质量。比如说谷歌,我们搜索A的时候,谷歌在最初的分词会分出,与A相关的A1、A2和A3,A3就是A的关键词,在引入了知识图谱之后,搜索引擎就会明白A和A1、A2的试题关系,,并且能把A2的一个详细的一个表给反映出来,也就是用户画像。
在知识图谱里,通常用‘实体Entity’表示图中的节点,用’关系relation‘表示图中的关系,其本质是为了表示知识,从实际应用的角度出发可以简单把知识图谱理解成多关系图(Multi-relational Graph)。
二,知识图谱的表示
图是由节点(vertex)和边(edge)来构成的,但这些图通常只包含一种类型的节点和边,相反,多关系图一般包含多种类型的节点和多类型的边,如下图
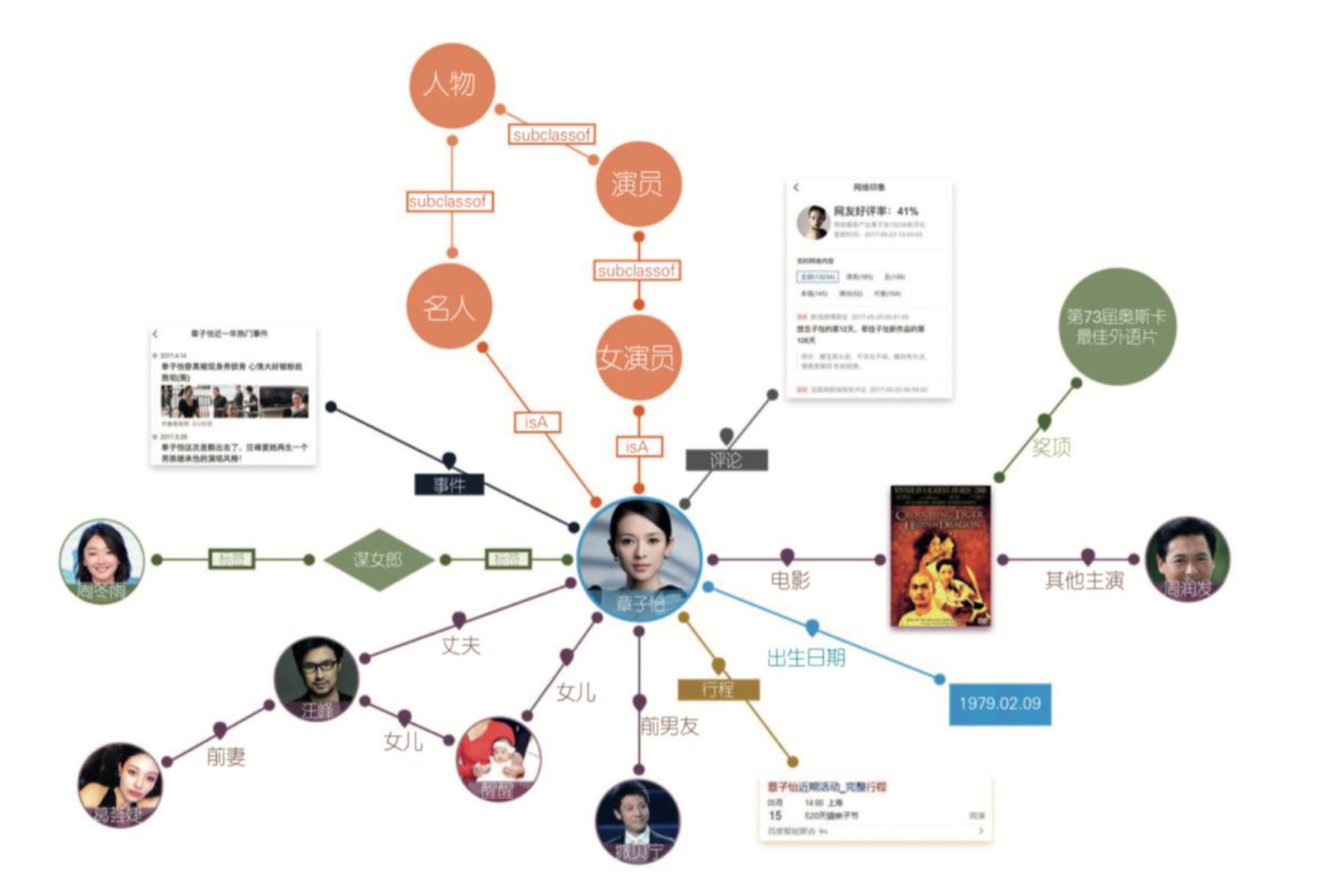
当知识图谱有属性时,可以用属性图来表示。如,性别、年龄、出生日期作为实体人的属性,结婚时间作为关系的属性等。属性图的表达很贴近现实生活的场景,也可以很好的描述业务中所包含的逻辑。
除了属性图,知识图谱还可以用RDF形式(很多三元组)表示。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4869
4869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









