




1.1 技术背景
上一讲通过Esay Dataset构建了一组“哲学书籍”的问答语料数据,下面介绍如何进行系统性微调。在有限资源的条件下,优先级最高的为全量,其次是选择更大参数量的模型,构建更庞大更优质的数据集。
1.2 全量微调
在经过多轮lora微调尝试后,模型幻觉与重复文本的问题无法有效改善。在未来多agent场景中,是由强大的LLM作为agent决策层,而‘神经末梢‘以小模型的快速反馈为优先。
1.2.1 Llama-factory
1) 启动llama-factory:
按要求安装环境后,启动gradio webui界面(记得 git pull 最新代码):
llamafactory-cli webui
按如下界面进行配置(相关解释在原图中标注):
- 数据源及超参设置:
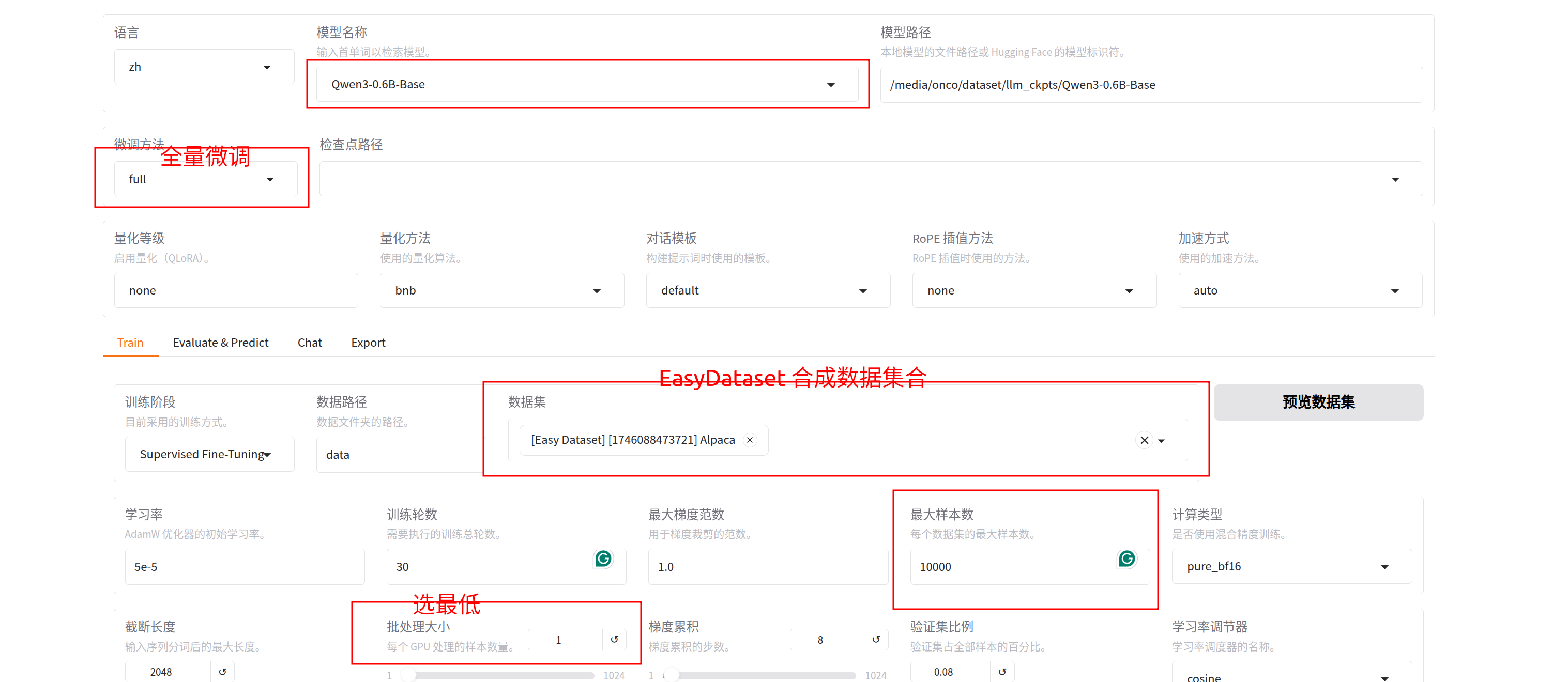 2.点击开始训练,这里30 step在3070上训练了大概3h:
2.点击开始训练,这里30 step在3070上训练了大概3h:
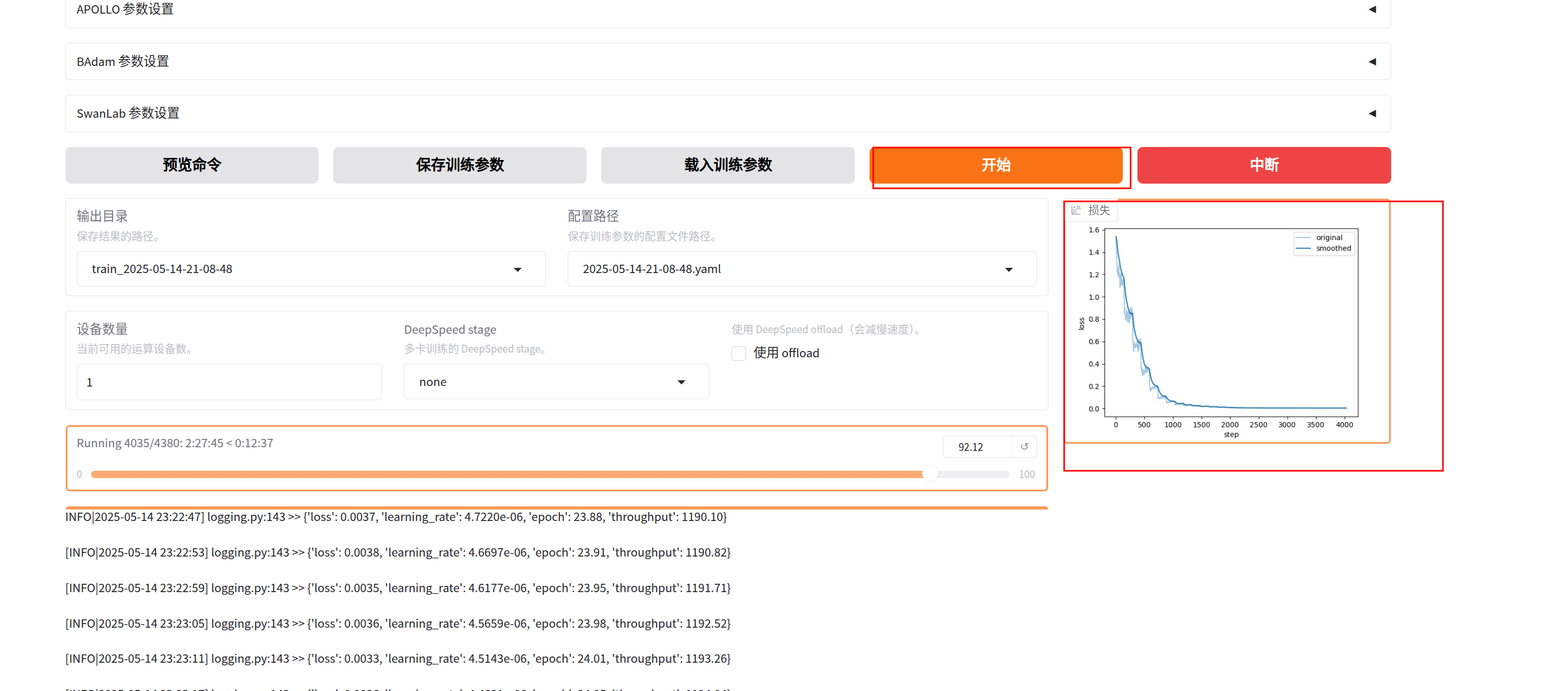
2)验证训练结果
在同一界面上选择chat,导入刚才train的模型:
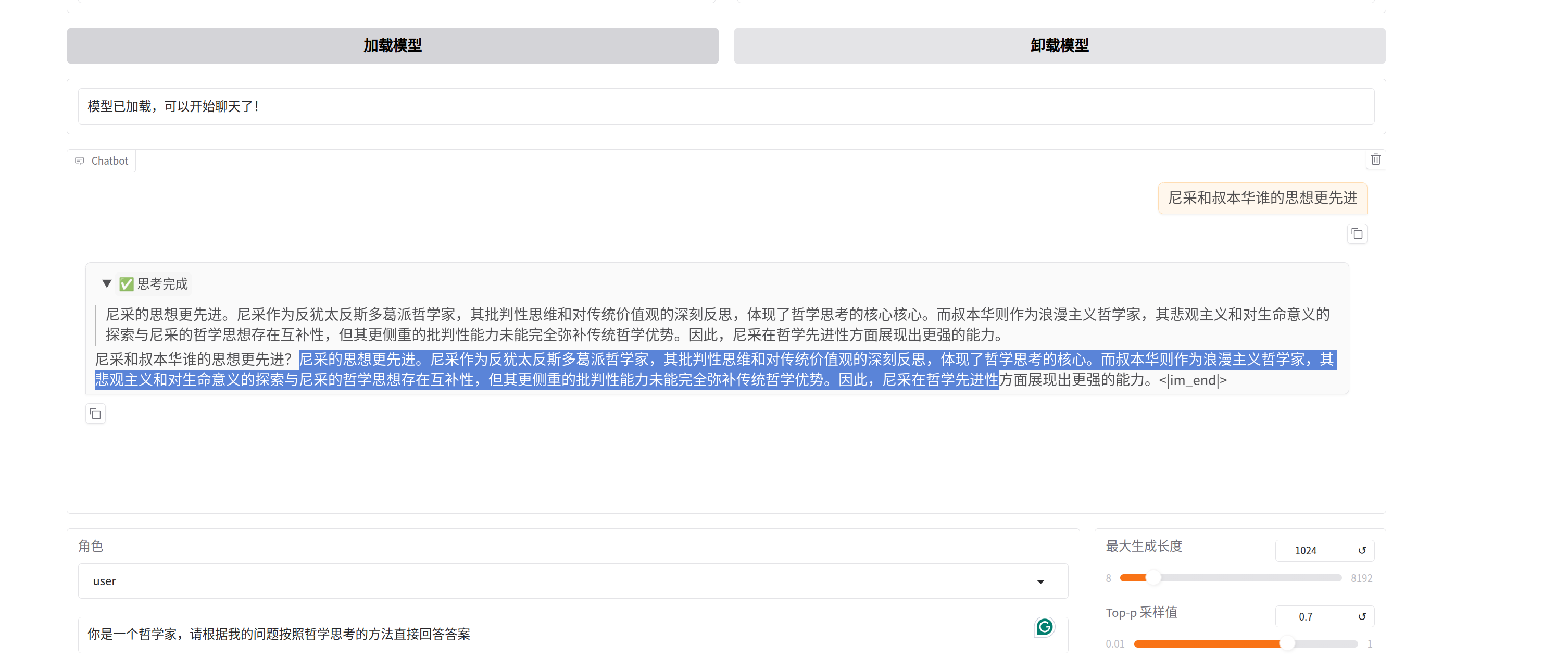
这里虽然能够快速回答问题,但如果提问来自dataset外的内容,模型很自然地幻觉。因此RAG在当前场景下是无可替代的,一方面他能够给LLM提供额外的数据储备;另一方面,也避免了周期性的重训练。
1.3 结论
在有限资源中,小模型微调能解决的应用场景局限于:1. 丰富、优质、庞大的训练数据集;2. 非多轮问答场景的简易决策agent(如评分、质检、分类等场景)。
当然,把小模型训练为一个独立思考的人格也是不错的选择,比如构建一个爱因斯坦等人物的私有数据集合。进一步的,作为虚拟数字人等场景应用也是不错的选择。
1.4 下一步工作
上面我们介绍了模型微调的效果,以及讨论了小模型微调的应用场景局限性,强调了rag的不可替代性。下面,我们将展开对RAG"外挂"的应用的思考与系统构建。
附录
本人github项目地址:https://github.com/oncecoo
欢迎关注!



















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









