




1.1 技术背景
通过Esay Dataset构建用于LLM SFT的问答语料数据,并用于lamma-factory微调
1.2 技术流程
1.2.1 Easy Dataset 镜像启动
1) 免去中间一些繁杂步骤,直接通过docker pull 下载最新的imgae:
docker pull passerbyjia/easy-dataset:latest
2)启动镜像并访问
Note: 注意更换 {data_save_path}为本地预储存路径;另外网路要用全局:–network=host
docker run -d -p 1717:1717 -v {data_save_path}:/app/local-db --network=host --name easy-dataset passerbyjia/easy-dataset:latest
访问l链接:http://localhost:1717/
1.2.2 构建数据集合
1) 创建并上传多个样本数据
准备对应领域的txt、doc数据样本进行构建;这里我用了一篇哲学书籍为实例,具体按如下图所示:
-
通过ollama构建LLM
由于Easy-Dataset只支持api或者ollama方式,为了省¥,直接本地构建即可,建议构建两个模型,一个容易出错: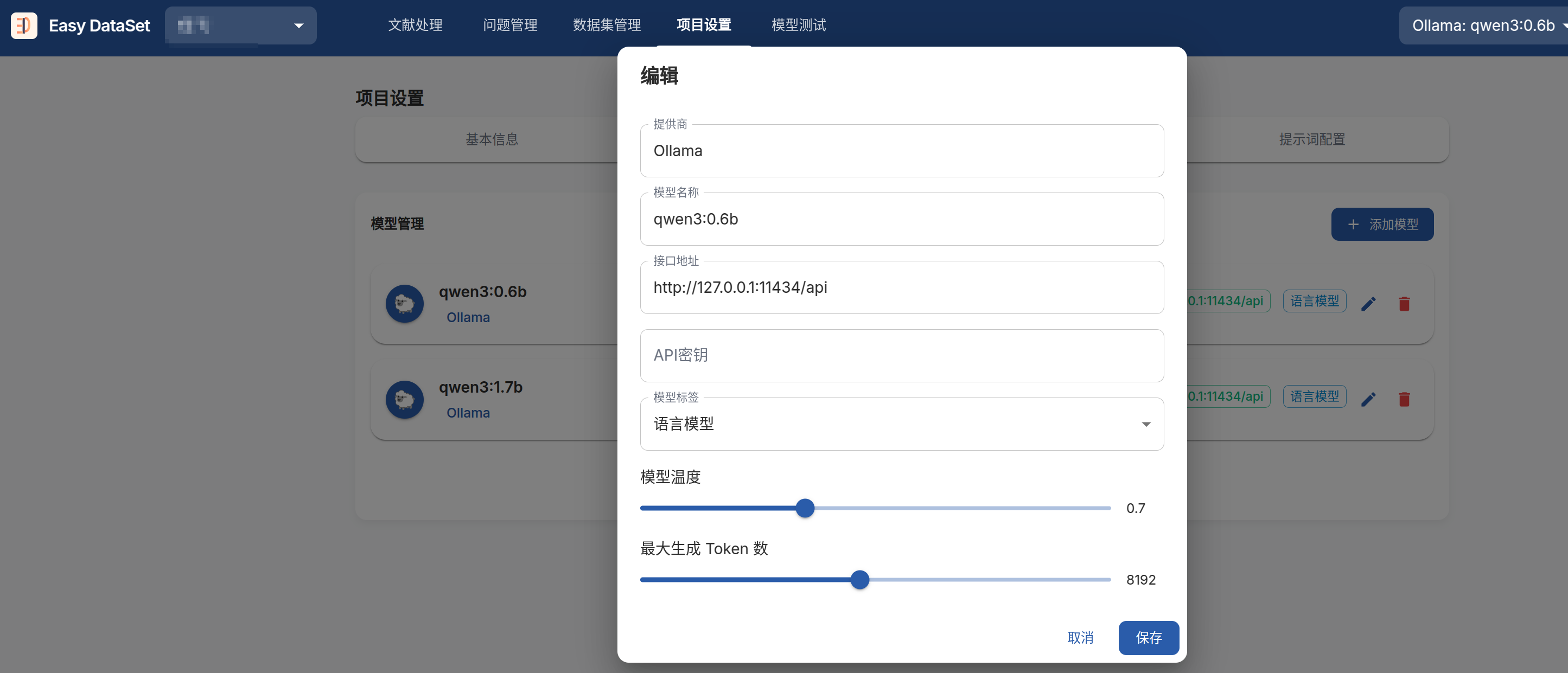
-
生成文本快chunk
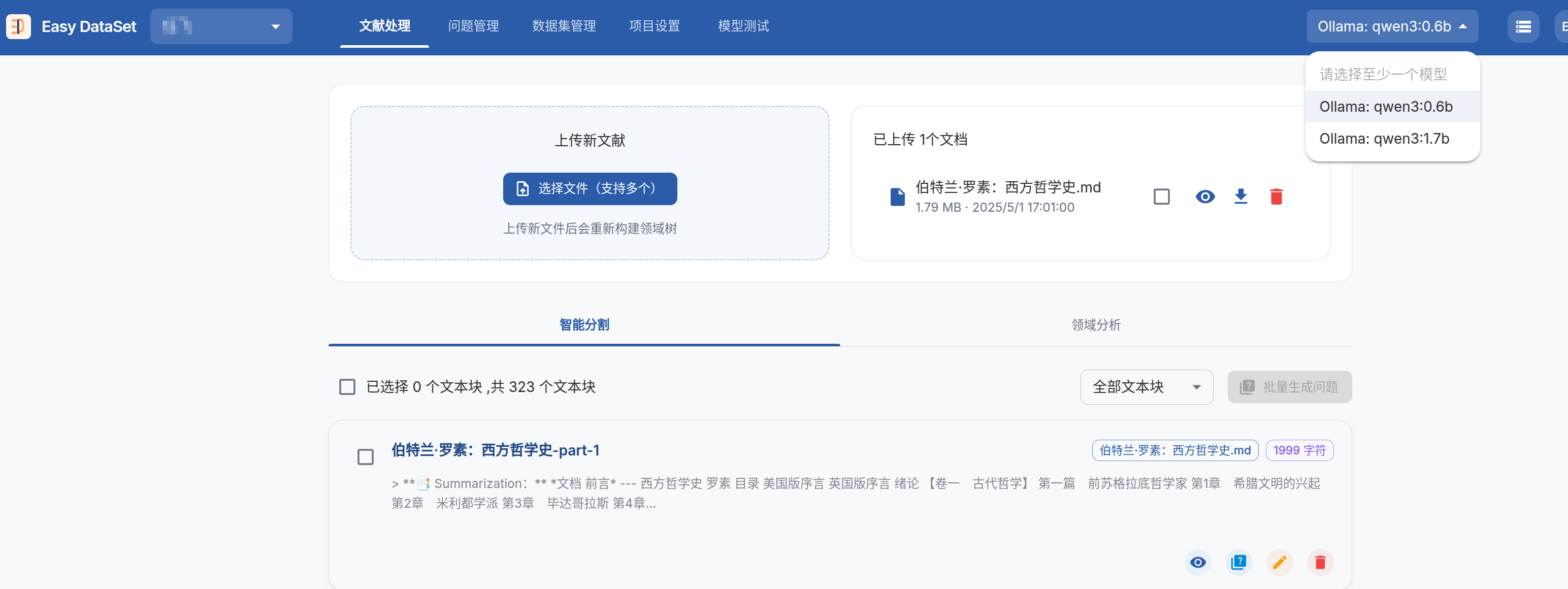
-
生成chunk对应问题
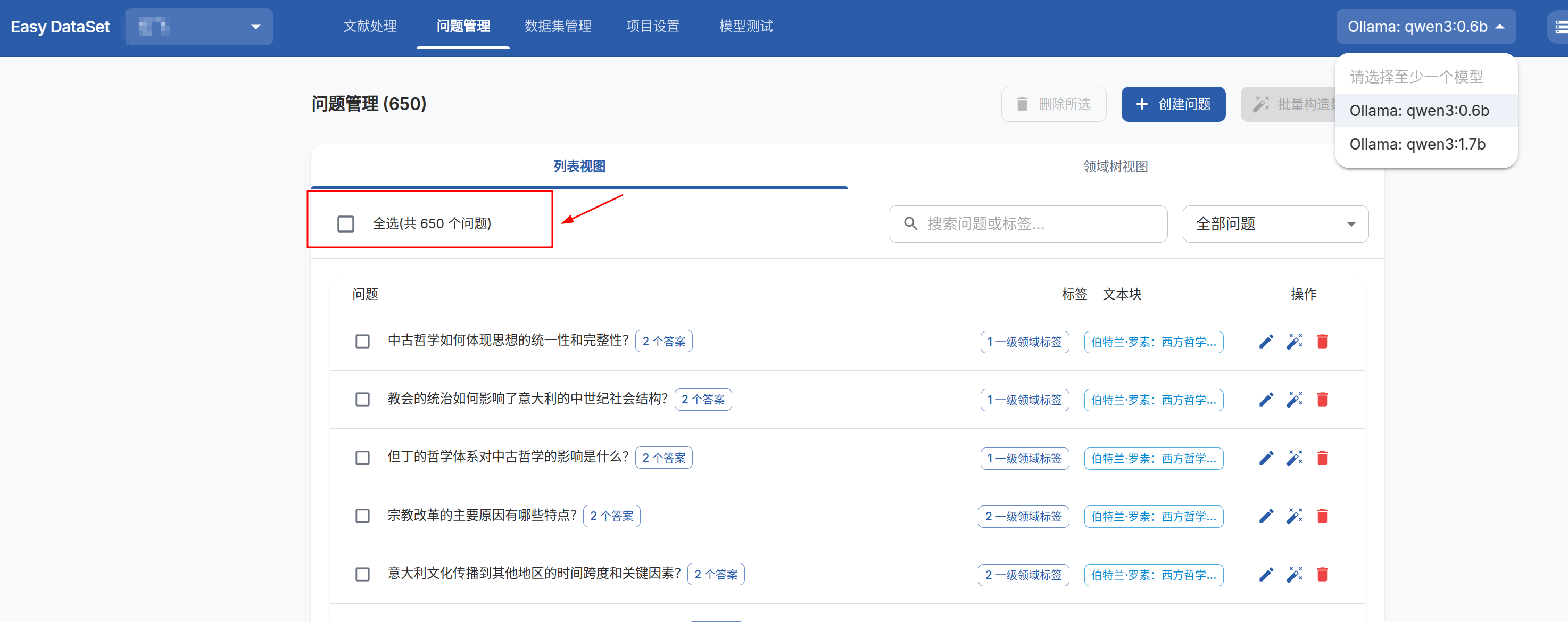
-
构建数据
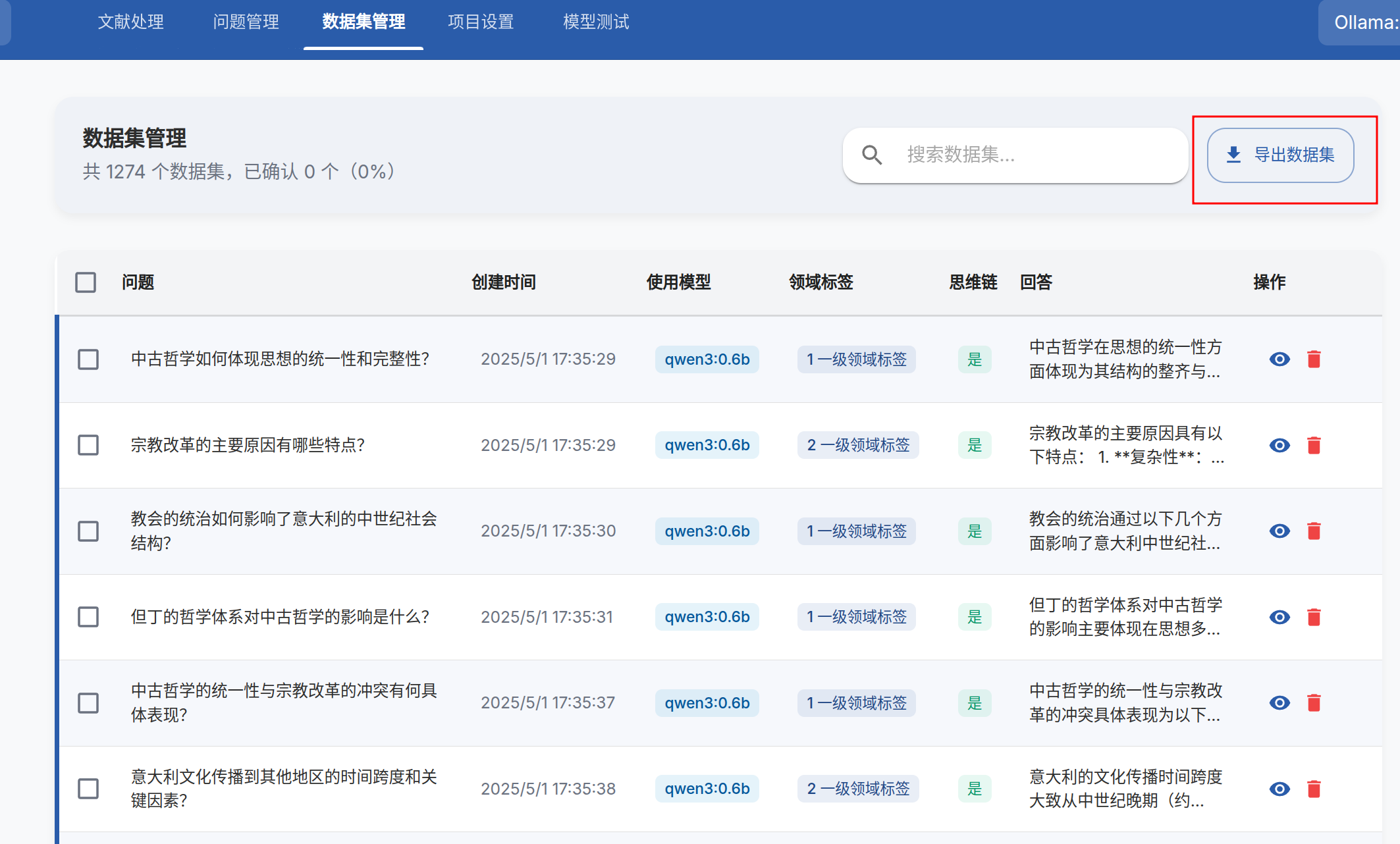
-
导出数据集为llama-factory格式
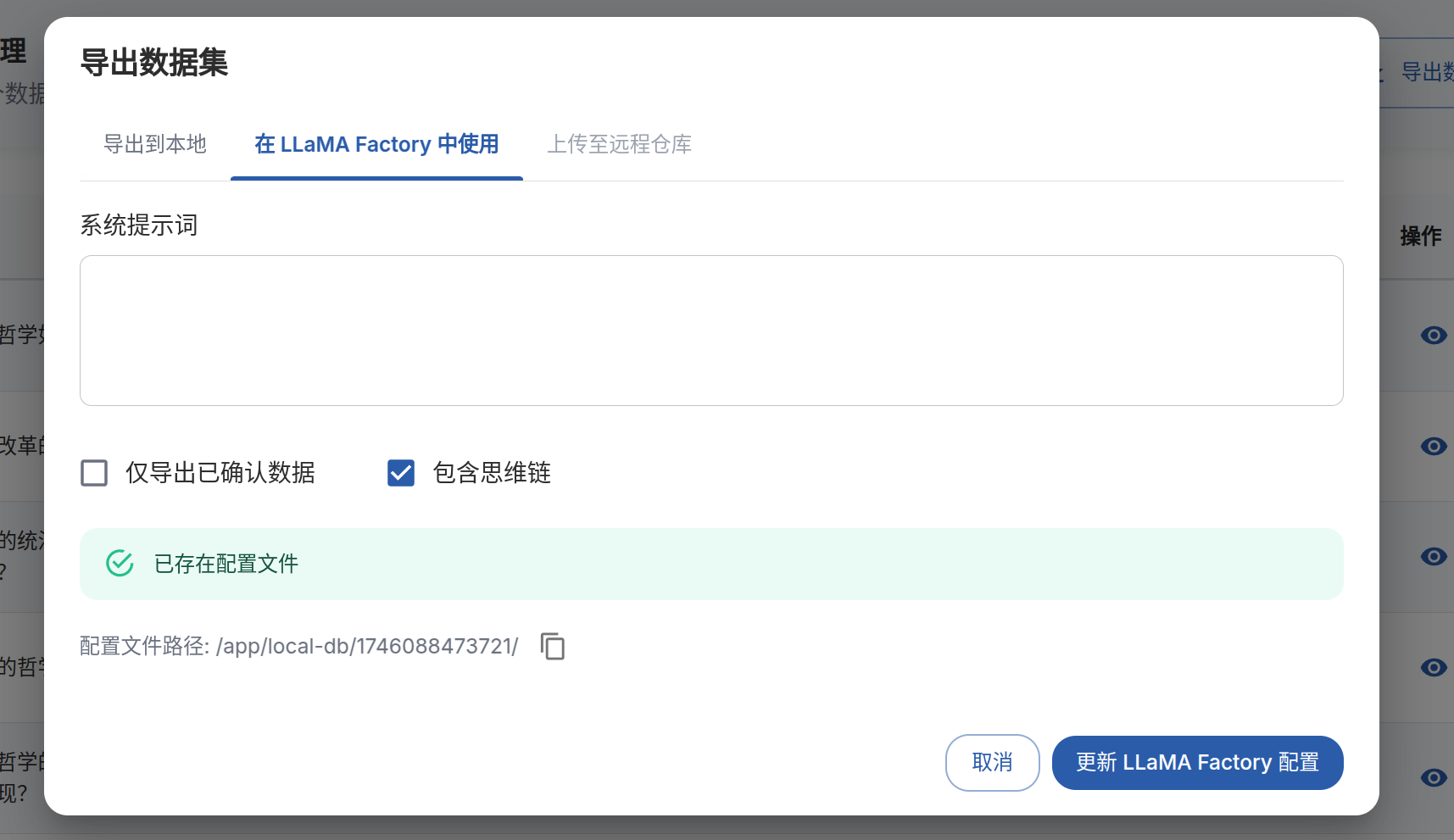
1.2.3 导入到llama-factoru项目中
前面我们指定了data_save_path,注意是本地路经而不是镜像里的路径; 将data_info.json(架构)和alpaca.json(问答对)放入到llama-factory/data文件夹下的文件
这里给一个data_info.json示例:
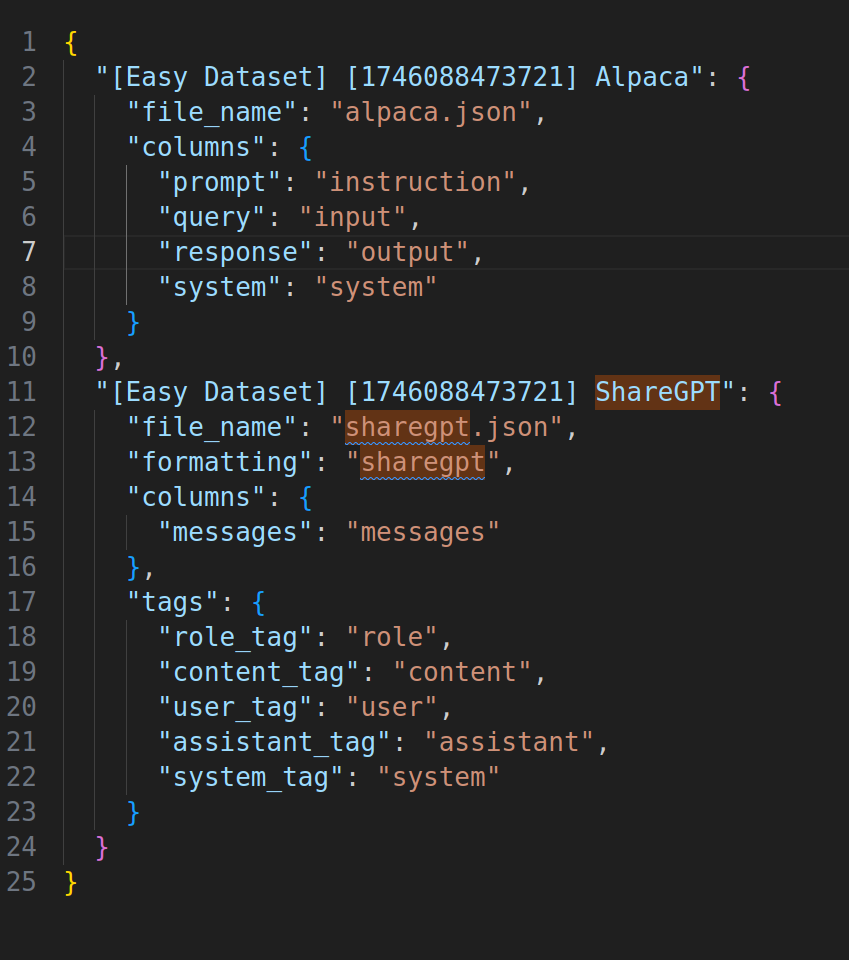
到这里,我们已经完成了数据集的制作和导入
1,3 下一步工作
虽然上面的数据以及可以构建起LLM 微调工作,但是LLM选择和幻觉问题仍然是比较头痛的事情,因此下一步工作我们会详细挑选一个领域(跑分),针对于小模型微调,使其能够达到其更大参数量模型的效果。
附录
本人github项目地址:https://github.com/oncecoo
欢迎关注!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









