




 本文介绍了选择Keras而非TensorFlow进行机器学习的原因,因其简单易上手。阐述了Keras的历史,还讲解了用Keras进行机器学习的三板斧,包括确定神经网络结构、衡量函数好坏、配置优化方法和找出最优参数。此外,介绍了Mini-batch知识及与SGD的对比,最后提及模型的评估与预测。
本文介绍了选择Keras而非TensorFlow进行机器学习的原因,因其简单易上手。阐述了Keras的历史,还讲解了用Keras进行机器学习的三板斧,包括确定神经网络结构、衡量函数好坏、配置优化方法和找出最优参数。此外,介绍了Mini-batch知识及与SGD的对比,最后提及模型的评估与预测。
前言
这节课应该是比较简单,基本都是演示为主,老师开始就讲了为什么本次选择Keras而不少TensorFlow的原因。,然后讲如何用Keras来进行机器学习的三板斧,最后讲了一些关于mini batch的知识,后面还有演示的示例。
原因:TensorFlow比较灵活,熟练掌握需要比较长的时间,Keras比较简单,容易上手。
Keras历史
作者目前在谷歌工作,小道消息称它将成为谷歌dl的官方API。
Keras在希腊语中意思是牛角,名字来源和一段神话有关,不八卦就不写了。
文档:官方文档
使用Keras就像玩乐高。
本次hello world是做手写数字识别
数据集MNIST:
Keras的三板斧

第一步:
决定function set长什么样,就是定神经网络有多少层,多少神经元等,例如下面有两个隐藏层,每层500个神经元:
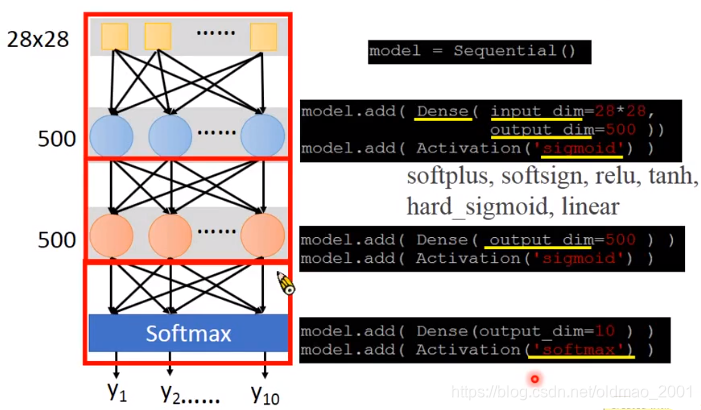
注意第二个隐藏层没有输入,因为它的输入就是上一个隐藏层的输出,激活函数有多个选择
第二步:
决定function的好坏
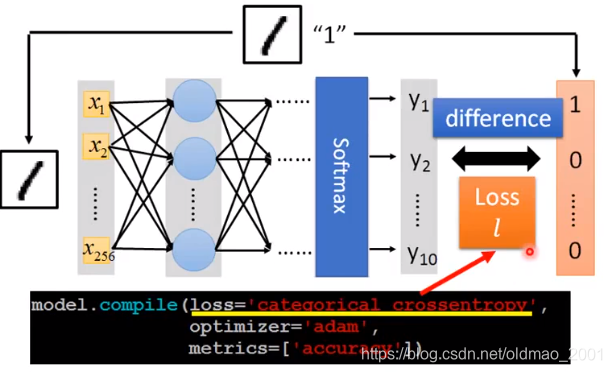
使用一个loss function来衡量,上图用的交叉熵,其他损失函数可以参见:Keras文档。
第三步:
分两小步:
3.1 配置
设置梯度下降的优化方法

3.2找出最优参数结果

x_train的模样:
第一维:training sample数量,第二维:每个图片的像素数量

y_train的模样:
第一维:training sample数量,第二维:输出类别(这里是10,0-9个数字)
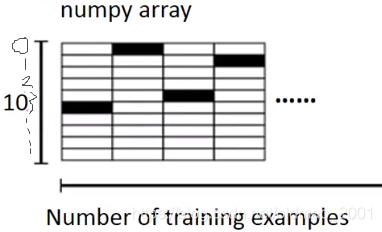
可以从上图中看到,第一个输入是数字5,所以上面的y_train的第一列从上往下数第六个格子是黑的。
Mini-batch
这里老师讲的比较粗,想详细了解还是去看看ng的深度学习,在第二周优化算法里面(Optimization algorithms),2.1和2.2节
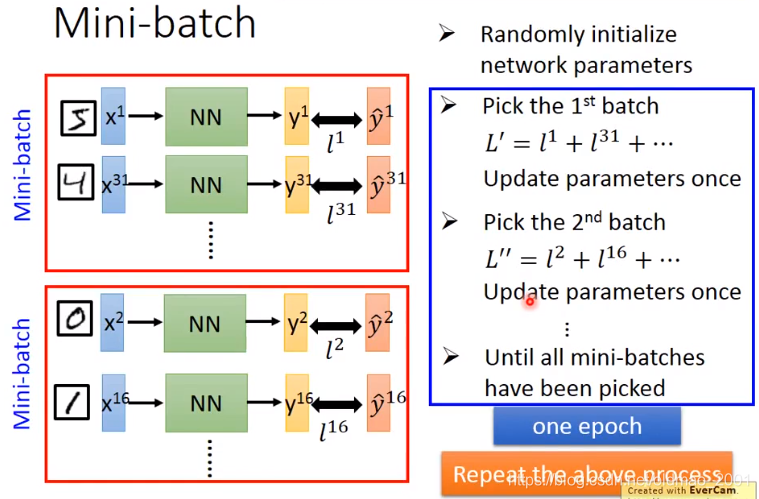
注意:在划分batch的时候要随机打乱training data,不过在Keras这里我们只要指定batch size,里面都由Keras帮我们随机放数据进去。
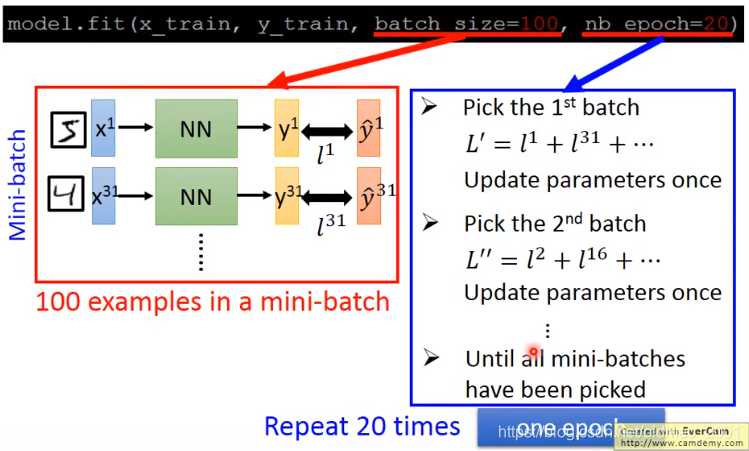
注意:这里不知道是不是疏忽,老师这里的batch size用的100,ng的课里面说这个数字最好是2的n次方,例如:64,128,256,512,这几个比较常见的大小~!会提升性能。
补充:上图中一个epoch参数更新了很多次(具体应该是:training data 数量/Batch size,下面有详解);当Batch size=1,就是Stochastic 梯度下降法。
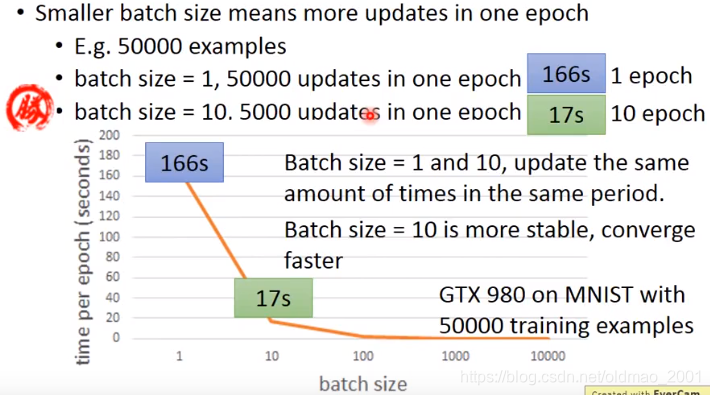
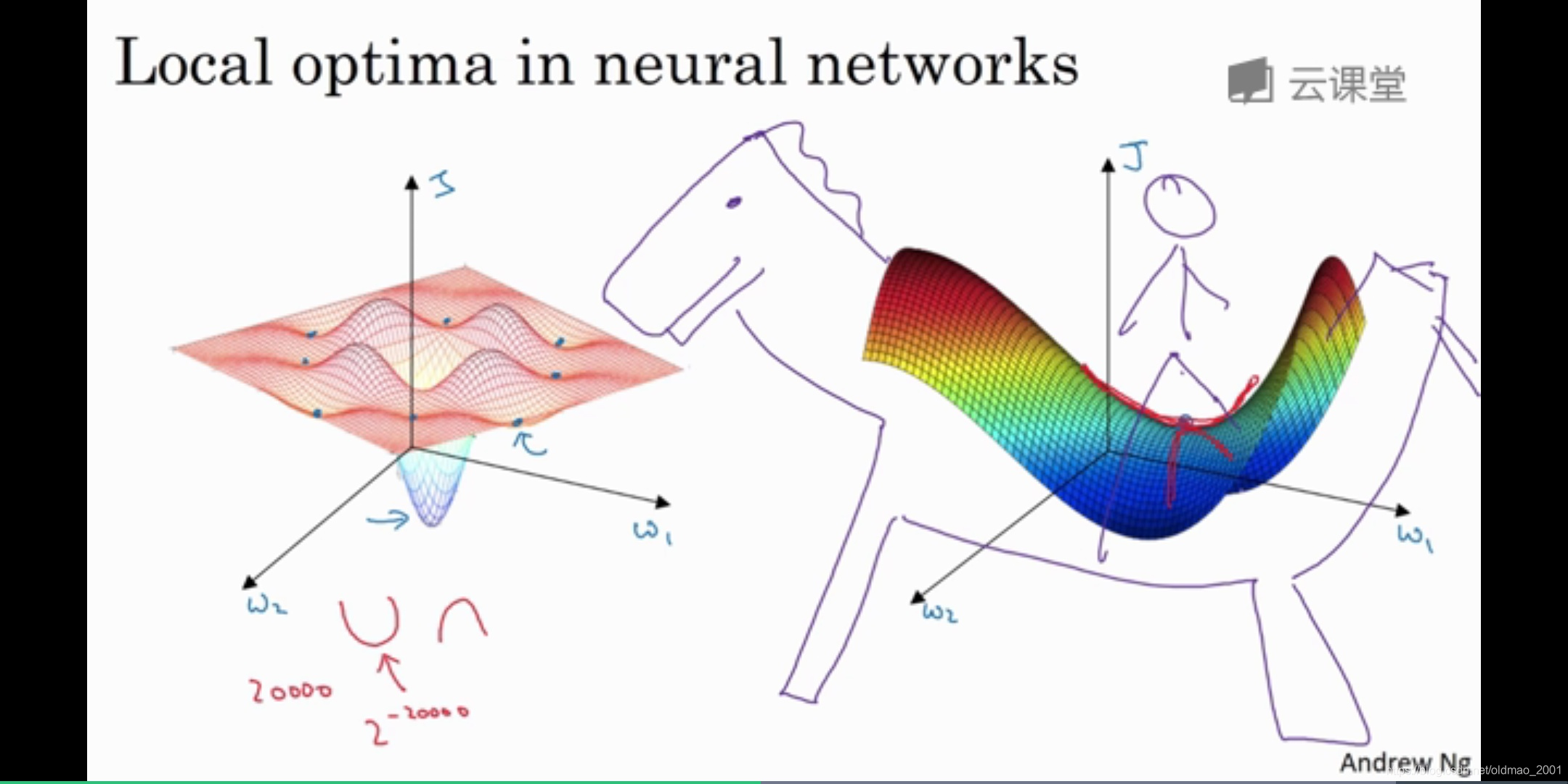
从上图可以看出,判断快慢不能单看某一个batch的更新速度,要看一个epoch的更新速度,batch size大一些,会稳定一些,可以进行并行运算加速,但是太大,gpu吃不消,batch size太大,容易卡在saddle point,这个可以看灵魂画手ng的讲解(2.10局部最优的问题)。
快在哪里?(SGD vs Mini-batch)
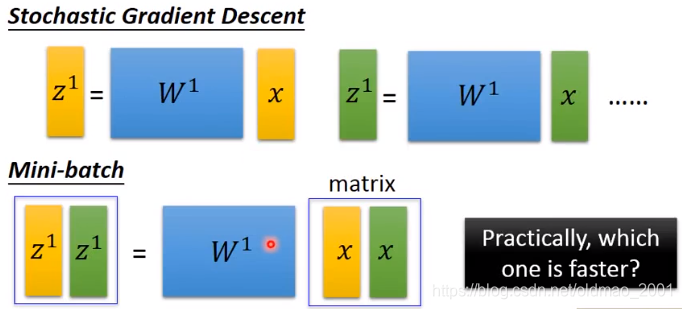
对于GPU来说,上面单个运算和下面运算一样快。
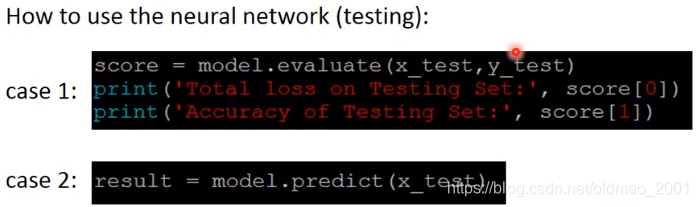
模型的评估与预测
番外:老师的降维打击梗:二向膜。自行百度-。-


















 4145
4145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











