




 本文探讨了专家系统与基于概率统计的机器学习系统两大主要学习分支,详细讲解了专家系统的工作流程、特性及局限性,并对比了监督学习与非监督学习算法,包括线性回归、逻辑回归、神经网络等,最后介绍了生成模型与判别模型的区别。
本文探讨了专家系统与基于概率统计的机器学习系统两大主要学习分支,详细讲解了专家系统的工作流程、特性及局限性,并对比了监督学习与非监督学习算法,包括线性回归、逻辑回归、神经网络等,最后介绍了生成模型与判别模型的区别。
文章目录
Two Main Branches of Learning
(符号主义)专家系统(expert system)
IF CONDITION1:
THEN Do Something1
ELIF Condition2:
THEN Do Something2
ELIF Condition3:
...
(连接主义)基于概率的系统(Probabilistic)
给定数据
D
=
{
X
,
y
}
D=\{X,y\}
D={X,y}
学习
X
X
X到
y
y
y的映射关系
f
:
X
→
y
f:X→y
f:X→y
如何选:

专家系统
专家系统=推理引擎+知识(类似于程序=数据结构+算法)
·利用知识和推理来解决决策问题(Decision Making Problem)
·全球第一个专家系统叫做DENDRAL,由斯坦福大学学者开发于70年代
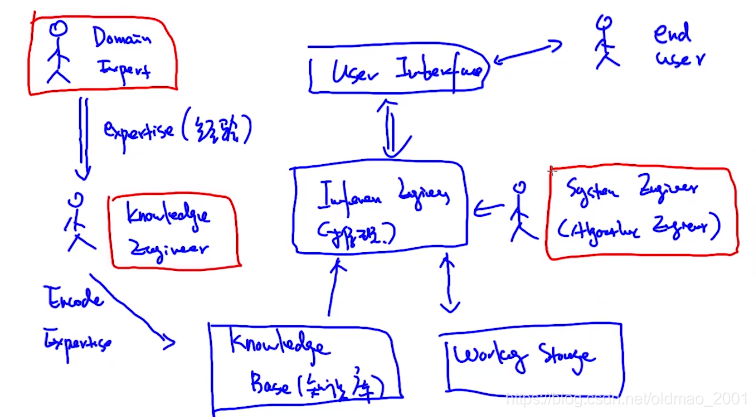
Expert System’s Working Flow
终端用户也要有红框,共涉及到4类用户。
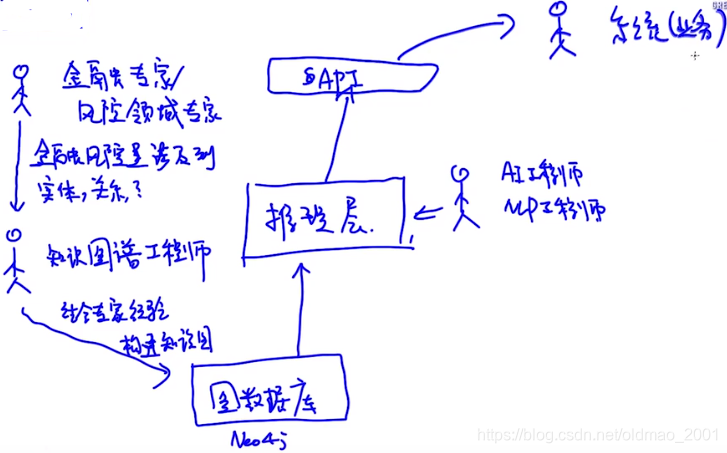
看例子:
搭建金融知识图谱。
Properties of Expert Systems
·处理不确定性
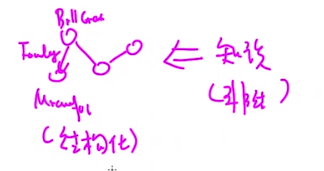
·知识的表示:非结构化数据——》结构化数据:
·可解释性(基于规则)
·可以做知识推理
逻辑推理
搭建好知识库之后,需要在这个基础上做一些推理。
Given: A Rule base contains following Rule set
Rule 1: If A and C Then F
Rule 2: If A and E Then G
Rule 3: If B Then E
Rule 4: If G Then D
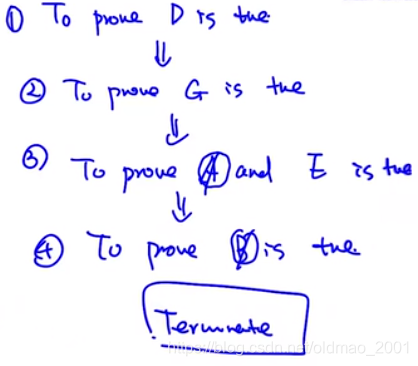
Problem: Prove
If A and B true Then D is true
有两种方法,一种是前向推理,一种是后向推理。
先来看前向,已知: A and B true
两次迭代得到结果

后向推理,要从D is true倒推A and B true
Drawbacks of Expert Systems
先说优点:
1、没有数据或者数据量很小也可以用。
2、可解释性很强。
缺点:
·需要设计大量的规则(Design Lots of Rules)
·需要领域专家来主导(Heavily Reply on Domain Expert)
·可移植性差(Limited Transferability to other Domain)或者说泛化能力差
·学习能力差(Inability to Learn)
·人能考虑的范围是有限的(Human Capacity is Limited)
Case Study:Risk Control金融风控实例
问题:根据用户的信息,决定要不要放贷

这种算分的专家系统灵活一点,不会因为违反某条规则就被拒绝。
专家系统面临的问题
·逻辑推理(Logical Inference),这个上面有讲过,这里不讲。
·解决规则冲突(Conflict Resolution),这个可以用个推理的方式来证明规则是否冲突,有冲突就删除
·选择最小规则的子集(Minimum Size of Rules),如何去除多余的规则,选择最小的规则子集。(贪心算法)
机器学习
下面来看另外一个大分支基于概率统计学习的系统(Probabilistic),主要是学习出数据与标签之间的映射关系,这里就是要讲讲机器学习了。
概念与分类
定义:自动从已有的数据里找出一规律然后把学到的这些规律应用到对未来数据(future data)的预测中,或者在不确定环境下自动地做一些决策。
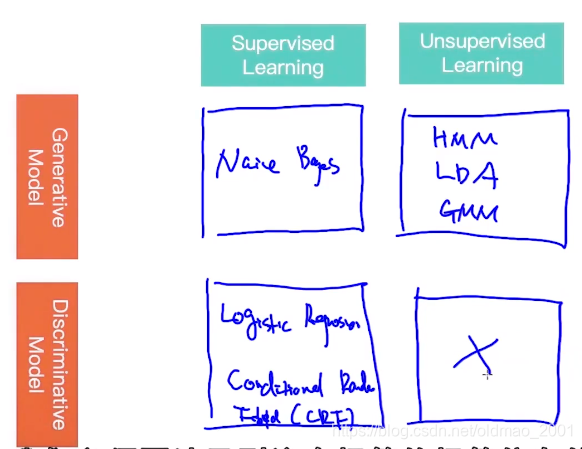
Supervised Learning Algorithms
·线性回归(Linear Regression)
·逻辑回归(Logistic Regression)
·朴素贝叶斯(Naive Bayes)
·神经网络(Neural Network)
·SVM(Support Vector Machine)
·随机森林(Random Forest)
·Adaboost
·CNN(Convolutional Neural Network)
Unsupervised Learning Algorithms
·K-means
·PCA(Principal Component Analysis)
·ICA(Independent Component Analysis)
·MF(Matrix Factorization)
·LSA(Latent Semantic Analysis)
·LDA(Latent Dirichlet Allocation)
Generative Model vs Discriminative Model
生成模型
判别模型
从数学的角度来看,生成模型目标通常是最大化:
P
(
X
)
或
P
(
X
∣
Y
)
P(X)或P(X|Y)
P(X)或P(X∣Y)
判别模型目标通常是最大化条件概率:
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)
建模流程

其中特征工程非常重要,如果理想的准确度是100%,那么特征工程决定了系统的准确度的上限,例如95%,那么选择模型,调节参数,也是只能逼近上限。
近几年,这个流程不断优化,变成端到端的流程。由于传统流程中特征工程非常重要,然后又很费时间。把特征工程去掉就是端到端的流程。由模型自动完成特征工程提取。
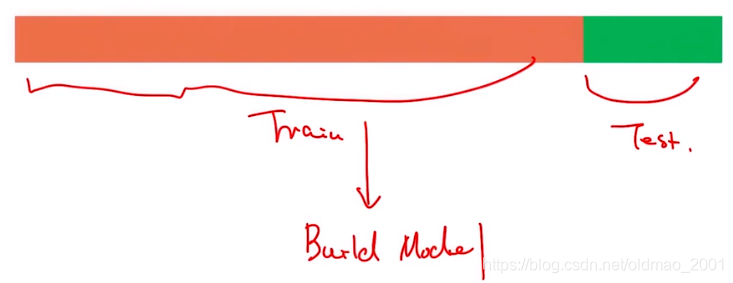
Train and Test Data


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











