




 本文深入探讨了结构化SVM的理论与应用,包括线性可分与非线性可分情况下的算法原理,梯度下降法的实现,以及如何通过误差函数和松弛变量优化模型。同时,对比了多种成本函数的优劣,介绍了切割平面算法在结构化SVM中的应用,以及多分类和二分类SVM的具体实现。
本文深入探讨了结构化SVM的理论与应用,包括线性可分与非线性可分情况下的算法原理,梯度下降法的实现,以及如何通过误差函数和松弛变量优化模型。同时,对比了多种成本函数的优劣,介绍了切割平面算法在结构化SVM中的应用,以及多分类和二分类SVM的具体实现。
文章目录
公式输入请参考: 在线Latex公式
课程PPT
Structured SVM和之前的一个SVM的课还不一样,之前的SVM是Structured SVM的一个特例。
前情回顾(略)
Separable case
也就是SVM里面提到过的,数据是线性可分的,也就是说存在一个权重向量
w
^
\widehat w
w
使得:
w
^
⋅
ϕ
(
x
1
,
y
^
1
)
≥
w
^
⋅
ϕ
(
x
1
,
y
)
+
δ
w
^
⋅
ϕ
(
x
2
,
y
^
2
)
≥
w
^
⋅
ϕ
(
x
2
,
y
)
+
δ
\widehat w\cdot \phi(x^1,\widehat y^1)\geq \widehat w\cdot \phi(x^1, y)+\delta\\ \widehat w\cdot \phi(x^2,\widehat y^2)\geq \widehat w\cdot \phi(x^2, y)+\delta
w
⋅ϕ(x1,y
1)≥w
⋅ϕ(x1,y)+δw
⋅ϕ(x2,y
2)≥w
⋅ϕ(x2,y)+δ

Structured Perceptron
其实是上节提到过的,还没有证明的算法。这里贴过来(和上节不一样的是x,y的上标由r变成了n):
算法描述:
输入:训练集:
{
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
.
.
.
,
(
x
N
,
y
^
N
)
,
.
.
.
}
\{(x^1,\widehat y^1),(x^2,\widehat y^2),...,(x^N,\widehat y^N),...\}
{(x1,y
1),(x2,y
2),...,(xN,y
N),...}
输出:权重向量
w
w
w
伪代码(
w
w
w存在是前提条件)
Initialize
w
=
0
w =0
w=0
d
o
do
do
For each pair of training example
(
x
n
,
y
^
n
(x^n,\widehat{y}^n
(xn,y
n取一笔训练数据
Find the label
y
~
n
\tilde{y}^n
y~n maximizing
w
⋅
ϕ
(
x
n
,
y
)
w\cdot\phi(x^n,y)
w⋅ϕ(xn,y)
y
~
n
=
a
r
g
m
a
x
y
∈
Y
w
⋅
ϕ
(
x
n
,
y
)
这
个
是
q
u
e
s
t
i
o
n
2
\tilde{y}^n=arg\underset{y\in Y}{max}\space w\cdot\phi(x^n,y)\quad这个是question \space2
y~n=argy∈Ymax w⋅ϕ(xn,y)这个是question 2,这个之前假设这个问题已经解决了
if
y
~
n
≠
y
^
n
\tilde{y}^n\neq\widehat{y}^n
y~n=y
n, update
w
w
w
w
→
w
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
w\to w+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)
w→w+ϕ(xn,y
n)−ϕ(xn,y~n)
u
n
t
i
l
w
i
s
n
o
t
u
p
d
a
t
e
d
→
until \space w \space is\space not\space updated \to
until w is not updated→ We are done!
下面开始证明:
Warning of Math
前戏
在本节的假定中,数据是线性可分的,为了找到
w
^
\widehat w
w
,我们最多需要更新
(
R
δ
)
2
(\cfrac{R}{\delta})^2
(δR)2次
其中:
δ
\delta
δ是margin,R是
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y)与
ϕ
(
x
,
y
′
)
\phi(x,y')
ϕ(x,y′)的最大距离。
注意:算法的迭代次数和y的个数无关。
证明开始:
每次看到一个错误(
y
~
n
≠
y
^
n
\tilde{y}^n\neq\widehat{y}^n
y~n=y
n)
w
w
w就更新一次,所以更新的思路是:
w
0
=
0
→
w
1
→
w
2
→
⋯
→
w
k
→
w
k
+
1
→
⋯
w^0=0\to w^1\to w^2\to\cdots\to w^k\to w^{k+1}\to\cdots
w0=0→w1→w2→⋯→wk→wk+1→⋯
w
k
=
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
(1)
w^k=w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)\tag1
wk=wk−1+ϕ(xn,y
n)−ϕ(xn,y~n)(1)
以上就是
w
k
w^k
wk和
w
k
−
1
w^{k-1}
wk−1的关系。
当然不要忘记我们的前提条件:
数据是线性可分的,存在一个权重向量
w
^
\widehat w
w
使得:
对于所有训练数据
∀
n
\forall n
∀n,和所有数据对应的所有不正确的标签
∀
y
∈
Y
−
{
y
^
n
}
\forall y\in Y-\{\widehat y^n\}
∀y∈Y−{y
n}:
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
≥
w
^
⋅
ϕ
(
x
n
,
y
)
+
δ
\widehat w\cdot \phi(x^n,\widehat y^n)\geq \widehat w\cdot \phi(x^n, y)+\delta
w
⋅ϕ(xn,y
n)≥w
⋅ϕ(xn,y)+δ
对于
w
^
\widehat w
w
,我们不是一般性的假设其长度为1:
∣
∣
w
^
∣
∣
=
1
||\widehat w||=1
∣∣w
∣∣=1(因为向量总是可以做normalization,使得长度变成1,所以为了便于计算,就直接定为1好了。)
开证
记
ρ
k
\rho_k
ρk为
w
^
\widehat w
w
和
w
k
w^k
wk的夹角,要证明:随着k的增加,这个夹角是越来越小的。即
c
o
s
ρ
k
cos \rho_k
cosρk是越来越大的。
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}
cosρk=∣∣w
∣∣w
⋅∣∣wk∣∣wk
先看分子,是
w
^
\widehat w
w
和
w
k
w^k
wk的点积,把前戏中的公式2带入:
w
^
⋅
w
k
=
w
^
⋅
(
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
=
w
^
⋅
w
k
−
1
+
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
^
⋅
ϕ
(
x
n
,
y
~
n
)
(2)
\widehat w\cdot w^k=\widehat w\cdot(w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))\\ =\widehat w\cdot w^{k-1}+\widehat w\cdot\phi(x^n,\widehat{y}^n) -\widehat w\cdot \phi(x^n,\tilde{y}^n)\tag2
w
⋅wk=w
⋅(wk−1+ϕ(xn,y
n)−ϕ(xn,y~n))=w
⋅wk−1+w
⋅ϕ(xn,y
n)−w
⋅ϕ(xn,y~n)(2)
根据本节最开始给出的
δ
\delta
δ的定义(也就是数据线性可分的假设)。
w
^
⋅
ϕ
(
x
1
,
y
^
1
)
≥
w
^
⋅
ϕ
(
x
1
,
y
)
+
δ
w
^
⋅
ϕ
(
x
2
,
y
^
2
)
≥
w
^
⋅
ϕ
(
x
2
,
y
)
+
δ
\widehat w\cdot \phi(x^1,\widehat y^1)\geq \widehat w\cdot \phi(x^1, y)+\delta\\ \widehat w\cdot \phi(x^2,\widehat y^2)\geq \widehat w\cdot \phi(x^2, y)+\delta
w
⋅ϕ(x1,y
1)≥w
⋅ϕ(x1,y)+δw
⋅ϕ(x2,y
2)≥w
⋅ϕ(x2,y)+δ
公式(2)中的后面两项的差是大于等于
δ
\delta
δ的
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
^
⋅
ϕ
(
x
n
,
y
~
n
)
≥
δ
\widehat w\cdot\phi(x^n,\widehat{y}^n) -\widehat w\cdot \phi(x^n,\tilde{y}^n)\geq\delta
w
⋅ϕ(xn,y
n)−w
⋅ϕ(xn,y~n)≥δ
因此公式(2)可以写为:
w
^
⋅
w
k
≥
w
^
⋅
w
k
−
1
+
δ
(3)
\widehat w\cdot w^k\geq\widehat w\cdot w^{k-1}+\delta\tag3
w
⋅wk≥w
⋅wk−1+δ(3)
算法中
w
w
w的初始值
w
0
=
0
w^0=0
w0=0
w
^
⋅
w
1
≥
w
^
⋅
w
0
+
δ
→
w
^
⋅
w
1
≥
δ
\widehat w\cdot w^1\geq\widehat w\cdot w^0+\delta\to\widehat w\cdot w^1\geq\delta
w
⋅w1≥w
⋅w0+δ→w
⋅w1≥δ
往下继续推:
w
^
⋅
w
2
≥
w
^
⋅
w
1
+
δ
→
w
^
⋅
w
2
≥
2
δ
\widehat w\cdot w^2\geq\widehat w\cdot w^1+\delta\to\widehat w\cdot w^2\geq2\delta
w
⋅w2≥w
⋅w1+δ→w
⋅w2≥2δ
最后:
w
^
⋅
w
k
≥
k
δ
\widehat w\cdot w^k\geq k\delta
w
⋅wk≥kδ
也就是说
c
o
s
ρ
k
cos \rho_k
cosρk的分子是随着k的增大而增大的,但是光分子变大并不能说明夹角变小,例如:

分子变大,很可能是造成向量的长度变长,这个时候的夹角并没有变化。
因此我们还要看
c
o
s
ρ
k
cos \rho_k
cosρk的分母,分母中,
∣
∣
w
^
∣
∣
=
1
||\widehat w||=1
∣∣w
∣∣=1,所以只要考虑
∣
∣
w
k
∣
∣
||w^k||
∣∣wk∣∣就可以,如果
∣
∣
w
k
∣
∣
||w^k||
∣∣wk∣∣不变,且分子变大,那么夹角就能证明是变小的拉。根据公式(1)
∣
∣
w
k
∣
∣
2
=
∣
∣
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
=
∣
∣
w
k
−
1
∣
∣
2
+
∣
∣
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
+
2
w
k
−
1
⋅
(
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
(4)
||w^k||^2=||w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2\\ =||w^{k-1}||^2+||\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2+2w^{k-1}\cdot(\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))\tag4
∣∣wk∣∣2=∣∣wk−1+ϕ(xn,y
n)−ϕ(xn,y~n)∣∣2=∣∣wk−1∣∣2+∣∣ϕ(xn,y
n)−ϕ(xn,y~n)∣∣2+2wk−1⋅(ϕ(xn,y
n)−ϕ(xn,y~n))(4)
公式中:
∣
∣
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
>
0
||\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2>0
∣∣ϕ(xn,y
n)−ϕ(xn,y~n)∣∣2>0
这个没啥疑问的,这个相当求距离,肯定大于0
2
w
k
−
1
⋅
(
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
<
0
2w^{k-1}\cdot(\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))<0
2wk−1⋅(ϕ(xn,y
n)−ϕ(xn,y~n))<0
这里是因为算法中规定,只有
ϕ
(
x
n
,
y
~
n
)
\phi(x^n,\tilde{y}^n)
ϕ(xn,y~n)比
ϕ
(
x
n
,
y
^
n
)
\phi(x^n,\widehat{y}^n)
ϕ(xn,y
n)大才会有更新动作,这里既然是出于更新中,所以这项小于0。
假设两个特征
ϕ
(
x
n
,
y
~
n
)
\phi(x^n,\tilde{y}^n)
ϕ(xn,y~n)和
ϕ
(
x
n
,
y
^
n
)
\phi(x^n,\widehat{y}^n)
ϕ(xn,y
n)的最大距离是
R
R
R,公式(4)可以写为:
∣
∣
w
k
∣
∣
2
≤
∣
∣
w
k
−
1
∣
∣
2
+
R
2
||w^k||^2\leq||w^{k-1}||^2+R^2
∣∣wk∣∣2≤∣∣wk−1∣∣2+R2
算法中
w
w
w的初始值
w
0
=
0
w^0=0
w0=0
∣
∣
w
1
∣
∣
2
≤
∣
∣
w
0
∣
∣
2
+
R
2
→
∣
∣
w
1
∣
∣
2
≤
R
2
||w^1||^2\leq||w^{0}||^2+R^2\to||w^1||^2\leq R^2
∣∣w1∣∣2≤∣∣w0∣∣2+R2→∣∣w1∣∣2≤R2
往下继续推:
∣
∣
w
2
∣
∣
2
≤
∣
∣
w
1
∣
∣
2
+
R
2
→
∣
∣
w
2
∣
∣
2
≤
2
R
2
||w^2||^2\leq||w^{1}||^2+R^2\to||w^2||^2\leq 2R^2
∣∣w2∣∣2≤∣∣w1∣∣2+R2→∣∣w2∣∣2≤2R2
最后:
∣
∣
w
k
∣
∣
2
≤
k
R
2
||w^k||^2\leq kR^2
∣∣wk∣∣2≤kR2
马上就好了,现在把我们算出来的写在一起:
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
w
^
⋅
w
k
≥
k
δ
∣
∣
w
k
∣
∣
2
≤
k
R
2
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}\quad\quad \widehat w\cdot w^k\geq k\delta \quad\quad ||w^k||^2\leq kR^2
cosρk=∣∣w
∣∣w
⋅∣∣wk∣∣wkw
⋅wk≥kδ∣∣wk∣∣2≤kR2
很容易得到:
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
≥
k
δ
k
R
2
=
k
δ
R
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}\geq\cfrac{k\delta}{\sqrt{kR^2}}=\sqrt k\frac{\delta}{R}
cosρk=∣∣w
∣∣w
⋅∣∣wk∣∣wk≥kR2kδ=kRδ

由于
c
o
s
cos
cos的值是小于等于1的,从图上可以看出:
k
δ
R
≤
1
→
k
≤
(
R
δ
)
2
\sqrt k\frac{\delta}{R}\leq1\to k\leq(\cfrac{R}{\delta})^2
kRδ≤1→k≤(δR)2
到这里证明结束,k的上限就是
(
R
δ
)
2
(\cfrac{R}{\delta})^2
(δR)2
最后讨论一下如何使得训练变快:
讨论
How to make training fast?不行
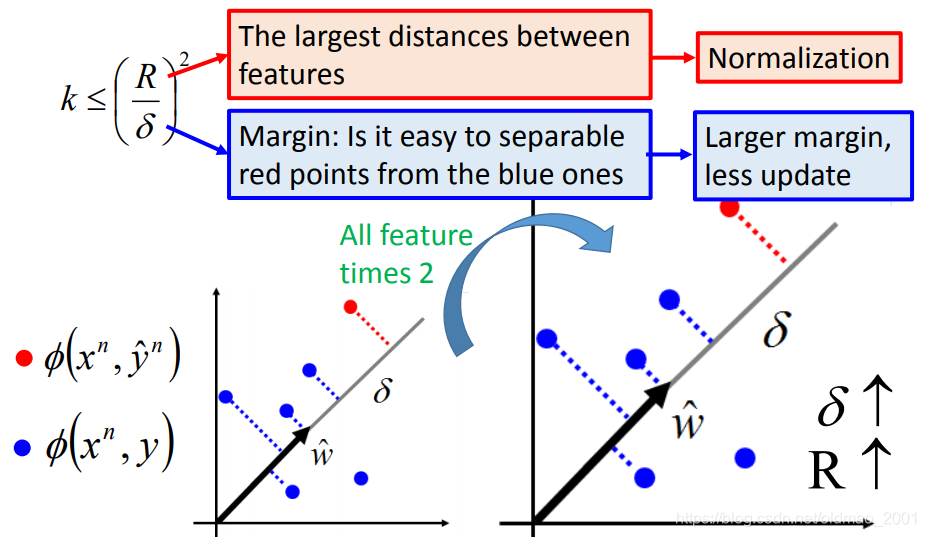
想把训练变快就是要使得k变小,使k变小就是要分母变大,或者分子变小,为了让分母变大,我们把数据都乘以2,
δ
\delta
δ就变大了,但是从图上可以看出来,分子R也变大了,所以这个方法是没有用的。
当然,在实操上面线性可分的数据基本上是不可能出现的,一般都是在理论上出现,因此下面我们来看线性不可分的情况。
Non-separable case
在数据(也就是
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y))线性不可分的情况下,权重
w
w
w仍然是可以有好坏之分的,我们可以用某些评估方法来对权重来甄别好坏,例如下图中,
w
′
w'
w′比
w
′
′
w''
w′′要好:

然后我们要做的是定义个衡量权重好坏的函数
Defining Cost Function
Define a cost
C
C
C to evaluate how bad a
w
w
w is, and then pick the
w
w
w minimizing the cost
C
C
C
C
C
C 是可以自己来定义的,老师给出一个定义:

关于
C
n
C_n
Cn,就是第n笔数据
x
n
x^n
xn的cost,意思是:给定的
w
w
w,在所有的
y
y
y里面,找到使得
w
⋅
ϕ
(
x
n
,
y
)
w\cdot\phi(x^n,y)
w⋅ϕ(xn,y)最大的值(就是上图中最上面那个),减去正确
y
^
n
\widehat y^n
y
n的
w
⋅
ϕ
(
x
n
,
y
^
n
)
w\cdot\phi(x^n,\widehat y^n)
w⋅ϕ(xn,y
n)的值。
把所有的cost累加起来就是
C
C
C
这里
C
n
C_n
Cn最小值是0;
为什么是减去正确
y
^
n
\widehat y^n
y
n的
w
⋅
ϕ
(
x
n
,
y
^
n
)
w\cdot\phi(x^n,\widehat y^n)
w⋅ϕ(xn,y
n)的值,因为之前上节课的假设中我们已经假定这个值我们会算,所以顺其自然的用这个值了,如果你要用最正确的前三个值也可以,但是你不会求这三个值,会很麻烦。
(Stochastic) Gradient Descent
虽然cost函数中有一个max操作,是不可导的,但是还是可以梯度下降的,例如之前激活函数ReLU虽然在0点不可导,还不是可以反向传播。
目标是:Find
w
w
w minimizing the cost
C
C
C
C
=
∑
n
=
1
N
C
n
C=\sum_{n=1}^NC^n
C=n=1∑NCn
C
n
=
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=arg\underset{y}{max}[w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
Cn=argymax[w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)
要求
▽
C
n
\triangledown C^n
▽Cn,需要注意的是:When w is different, the y can be different.(意思是当
w
w
w不一样的时候,取得第一项最大值的
y
y
y也不一样)下面看看
w
w
w(二维的向量)的图。
当
w
w
w在最左边区域的时候
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
argymax[w⋅ϕ(xn,y)]的取值是
y
′
y'
y′
当
w
w
w在最中间区域的时候
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
argymax[w⋅ϕ(xn,y)]的取值是
y
′
′
y''
y′′
当
w
w
w在最右边区域的时候
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
argymax[w⋅ϕ(xn,y)]的取值是
y
′
′
′
y'''
y′′′
因此在每个区域中的
C
n
C^n
Cn也可以很好算出来:
当
w
w
w在最左边区域的时候
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y')-w\cdot\phi(x^n,\widehat y^n)
Cn=w⋅ϕ(xn,y′)−w⋅ϕ(xn,y
n)
当
w
w
w在最中间区域的时候
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y'')-w\cdot\phi(x^n,\widehat y^n)
Cn=w⋅ϕ(xn,y′′)−w⋅ϕ(xn,y
n)
当
w
w
w在最右边区域的时候
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
′
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y''')-w\cdot\phi(x^n,\widehat y^n)
Cn=w⋅ϕ(xn,y′′′)−w⋅ϕ(xn,y
n)
这三个区域中的边界部分不可以微分,但是在中间的区域都是可以微分的,因此,三个区域对
w
w
w进行微分后求梯度
▽
C
n
\triangledown C^n
▽Cn变成:
当
w
w
w在最左边区域的时候
▽
C
n
=
ϕ
(
x
n
,
y
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y')-\phi(x^n,\widehat y^n)
▽Cn=ϕ(xn,y′)−ϕ(xn,y
n)
当
w
w
w在最中间区域的时候
▽
C
n
=
ϕ
(
x
n
,
y
′
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y'')-\phi(x^n,\widehat y^n)
▽Cn=ϕ(xn,y′′)−ϕ(xn,y
n)
当
w
w
w在最右边区域的时候
▽
C
n
=
ϕ
(
x
n
,
y
′
′
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y''')-\phi(x^n,\widehat y^n)
▽Cn=ϕ(xn,y′′′)−ϕ(xn,y
n)

那么整个算法的流程如下图所示:

最后的到结果如果把学习率
η
=
1
\eta=1
η=1,那么就变成了之前的 structured perceptron,减去错误加上正确的分类。
Considering Errors
看下Errors从何而来
先看看我们之前做的,实际上对于每个样本的计算,考虑的Errors都是一样的:

但是我们如果仔细看的话,会发现最下面那个其实和正确的答案已经差不多了,也就是说每个样本计算的时候Error是有所不一样的,把这些计算结果按Error进行排序(考虑错误的不同等级),就变成下面这样:

如此看来,我们希望我们找到的
w
w
w是能够考虑Error的:

现在的问题就变成,如何考虑Error,或者说如何来衡量计算结果与正确结果之间的差距(difference)?
Defining Error Function
△
(
y
^
,
y
)
>
0
\triangle (\widehat y,y)>0
△(y
,y)>0: difference between
y
^
\widehat y
y
and
y
y
y
A
(
y
)
A(y)
A(y) : area of bounding box
y
y
y
△
(
y
^
,
y
)
=
1
−
A
(
y
^
)
∩
A
(
y
)
A
(
y
^
)
∪
A
(
y
)
\triangle (\widehat y,y)=1-\cfrac{A(\widehat y)\cap A(y)}{A(\widehat y)\cup A(y)}
△(y
,y)=1−A(y
)∪A(y)A(y
)∩A(y)

考虑了Error之后,Cost函数也要改写下
Another Cost Function
从原来的:取分数最高的那个
y
y
y减去正确的
y
^
\widehat y
y
所得到的分数
C
n
=
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
Cn=ymax[w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)
变成:取分数最高的那个
y
y
y加上
Δ
\Delta
Δ,再减去正确的
y
^
\widehat y
y
所得到的分数
说人话,注意看下面的图,由于
Δ
\Delta
Δ的存在,使得黄色框框和红色框框不像的话,分数相差越远越好,反之,黄色框框和红色框框即使是分数没有拉开也没有关系。
换句人话,
C
n
C^n
Cn取最小值的条件是正确的
y
^
\widehat y
y
的得分不但要比其他的
y
y
y要大,而且还要大过
Δ
\Delta
Δ才行。
Δ
\Delta
Δ也叫Margin
C
n
=
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
Cn=ymax[△(y
,y)+w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)

先看怎么来解考虑了
Δ
\Delta
Δ的
C
n
C^n
Cn的梯度
Gradient Descent
为了和之前没有考虑Error的梯度求解区分开来,之前用的是
y
~
\tilde y
y~,这里用
y
ˉ
\bar y
yˉ,具体过程如下:
在每一个iteration,选择一个训练数据
{
x
n
,
y
^
n
}
\{x^n,\widehat y^n\}
{xn,y
n}
y
ˉ
n
=
a
r
g
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
\bar y^n=arg\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]
yˉn=argymax[△(y
,y)+w⋅ϕ(xn,y)]
上式就是之前没有解决的Problem2,所以
△
(
y
^
,
y
)
\triangle (\widehat y,y)
△(y
,y)这个函数要选好,不然不好解决这个问题。
▽
C
n
(
w
)
=
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n(w)=\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)
▽Cn(w)=ϕ(xn,yˉn)−ϕ(xn,y
n)
w
→
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
w\to w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]
w→w−η[ϕ(xn,yˉn)−ϕ(xn,y
n)]
Another Viewpoint
Minimizing the new cost function is minimizing the upper bound of the errors on training set.这里降低训练数据集中的Error上限不一定会减小Cost,只是有可能变小。
用于测试输出的函数是这个,也就是用内积最大的那个
y
y
y当做系统输出
y
~
\tilde y
y~:
y
~
=
a
r
g
m
a
x
y
w
⋅
ϕ
(
x
n
,
y
)
\tilde y=arg\underset{y}{max}w\cdot\phi(x^n,y)
y~=argymaxw⋅ϕ(xn,y)
我们要找到一个
w
w
w,使得系统输出的
y
~
\tilde y
y~和正确答案的
y
^
\widehat y
y
的差别的累加
C
′
C'
C′最小。写成:
C
′
=
∑
n
=
1
N
Δ
(
y
^
n
,
y
~
n
)
C'=\sum_{n=1}^N\Delta(\widehat y^n,\tilde y^n)
C′=n=1∑NΔ(y
n,y~n)
We want to find
w
w
w minimizing
C
′
C'
C′(和最小化errors是一样样的)
It is hard!
Because
y
y
y can be any kind of objects,
Δ
(
⋅
,
⋅
)
\Delta(\cdot,\cdot)
Δ(⋅,⋅) can be any function…
换个思路,找到
C
′
C'
C′的上界
C
C
C
C
′
=
∑
n
=
1
N
Δ
(
y
^
n
,
y
~
n
)
≤
C
=
∑
n
=
1
N
C
n
C'=\sum_{n=1}^N\Delta(\widehat y^n,\tilde y^n)\leq C=\sum_{n=1}^NC^n
C′=n=1∑NΔ(y
n,y~n)≤C=n=1∑NCn
现在要证明(从数学上证明上界这个事情):
Δ
(
y
^
n
,
y
~
n
)
≤
C
n
\Delta(\widehat y^n,\tilde y^n)\leq C^n
Δ(y
n,y~n)≤Cn
开始:
由于:
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
≥
0
[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]\geq0
[w⋅ϕ(xn,y~n)−w⋅ϕ(xn,y
n)]≥0
所以:
Δ
(
y
^
n
,
y
~
n
)
≤
Δ
(
y
^
n
,
y
~
n
)
+
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
\Delta(\widehat y^n,\tilde y^n)\leq\Delta(\widehat y^n,\tilde y^n)+[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]
Δ(y
n,y~n)≤Δ(y
n,y~n)+[w⋅ϕ(xn,y~n)−w⋅ϕ(xn,y
n)]
Δ
(
y
^
n
,
y
~
n
)
+
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
=
[
Δ
(
y
^
n
,
y
~
n
)
+
w
⋅
ϕ
(
x
n
,
y
~
n
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
\Delta(\widehat y^n,\tilde y^n)+[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]=[\Delta(\widehat y^n,\tilde y^n)+w\cdot\phi(x^n,\tilde y^n)]-w\cdot\phi(x^n,\widehat y^n)
Δ(y
n,y~n)+[w⋅ϕ(xn,y~n)−w⋅ϕ(xn,y
n)]=[Δ(y
n,y~n)+w⋅ϕ(xn,y~n)]−w⋅ϕ(xn,y
n)
然后从
y
~
n
\tilde y^n
y~n里面可以选出一个
y
y
y,使得:
[
Δ
(
y
^
n
,
y
~
n
)
+
w
⋅
ϕ
(
x
n
,
y
~
n
)
]
≤
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
[\Delta(\widehat y^n,\tilde y^n)+w\cdot\phi(x^n,\tilde y^n)]\leq \underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]
[Δ(y
n,y~n)+w⋅ϕ(xn,y~n)]≤ymax[Δ(y
n,y)+w⋅ϕ(xn,y)]
因此整理后,可得:
Δ
(
y
^
n
,
y
~
n
)
≤
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
C
n
\Delta(\widehat y^n,\tilde y^n)\leq \underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)=C^n
Δ(y
n,y~n)≤ymax[Δ(y
n,y)+w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)=Cn
More Cost Functions
我们把上面的解决方案称为:Margin rescaling:
C
n
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
Cn=ymax[Δ(y
n,y)+w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)
除了这种方法,还有别的方法,例如:
Slack variable rescaling:
C
n
=
m
a
x
y
Δ
(
y
^
n
,
y
)
[
1
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
C^n=\underset{y}{max}\Delta(\widehat y^n, y)[1+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)]
Cn=ymaxΔ(y
n,y)[1+w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)]
这个方法的大概思想是:
y
y
y与
y
^
\widehat y
y
的差距很大,
Δ
\Delta
Δ也就很大,乘起来之后结果会把差距放大;反之,
y
y
y与
y
^
\widehat y
y
的差距很小,
Δ
\Delta
Δ也就很小,乘起来之后结果也会很小。
另外之前那种用的加法,有缺陷,没有考虑到
w
w
w和
Δ
\Delta
Δ的大小(因为
Δ
\Delta
Δ自己定义的),例如一个是0.001,一个是1000,那么加法对这个权重上没有考虑清楚,用乘法的话就是自带normalization效果,所以这个方法有它的道理。
Regularization
Training data and testing data can have different distribution.
w
w
w close to zero can minimize the influence of mismatch.
因此原有的Cost函数变成:

其中
λ
\lambda
λ是调整系数,当Cost函数变成下面式子后,具体的梯度下降算法伪代码和前面差不多:
在每一个iteration,选择一个训练数据
{
x
n
,
y
^
n
}
\{x^n,\widehat y^n\}
{xn,y
n}
y
ˉ
=
a
r
g
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
\bar y=arg\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]
yˉ=argymax[△(y
,y)+w⋅ϕ(xn,y)]
▽
C
n
(
w
)
=
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
+
w
\triangledown C^n(w)=\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)+w
▽Cn(w)=ϕ(xn,yˉn)−ϕ(xn,y
n)+w
上式中的
w
w
w是
1
2
∣
∣
w
∣
∣
2
\cfrac{1}{2}||w||^2
21∣∣w∣∣2对
w
w
w做偏导得到的结果。
w
→
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
−
η
w
=
(
1
−
η
)
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
w\to w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]-\eta w\\ =(1-\eta)w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]
w→w−η[ϕ(xn,yˉn)−ϕ(xn,y
n)]−ηw=(1−η)w−η[ϕ(xn,yˉn)−ϕ(xn,y
n)]
前面这项就相当于DNN中的Weight Decay。
Structured SVM
把之前得到的结果写出来,然后看看Structured SVM是这么回事:
描述1:
Find
w
w
w minimizing
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^NC^n
C=21∣∣w∣∣2+λn=1∑NCn
C
n
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
Cn=ymax[Δ(y
n,y)+w⋅ϕ(xn,y)]−w⋅ϕ(xn,y
n)
移项:
C
n
+
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
(1)
C^n+w\cdot\phi(x^n,\widehat y^n)=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)] \tag 1
Cn+w⋅ϕ(xn,y
n)=ymax[Δ(y
n,y)+w⋅ϕ(xn,y)](1)
说明:
f
(
x
)
=
m
a
x
y
(
y
)
(a)
f(x)=\underset{y}{max}(y)\tag a
f(x)=ymax(y)(a)
如果
y
=
{
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
}
y=\{1,2,3,4,5,6,7,8,9\}
y={1,2,3,4,5,6,7,8,9},那么
f
(
x
)
=
9
f(x)=9
f(x)=9
如果我们直接写
f
(
x
)
≥
∀
y
(b)
f(x)\geq \forall y\tag b
f(x)≥∀y(b)
显然(a)和(b)不等价,因为在(b)中,
f
(
x
)
f(x)
f(x)可以等于10,11,12,etc。
但是如果我们加上一个约束:
m
i
n
i
m
i
z
e
f
(
x
)
minimize\quad f(x)
minimizef(x)
这个时候(a)和(b)就等价了
根据说明,我们的目标是minimizing
C
C
C,因此公式(1)等价下面的式子:
f
o
r
∀
y
:
C
n
+
w
⋅
ϕ
(
x
n
,
y
^
n
)
≥
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
for \quad\forall y:\\C^n+w\cdot\phi(x^n,\widehat y^n)\geq \Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)
for∀y:Cn+w⋅ϕ(xn,y
n)≥Δ(y
n,y)+w⋅ϕ(xn,y)
移项:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
C
n
w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-C^n
w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)≥Δ(y
n,y)−Cn
由上式可得,描述1等价于:
描述2:
Find
w
w
w minimizing
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^NC^n
C=21∣∣w∣∣2+λn=1∑NCn
f
o
r
∀
n
:
f
o
r
∀
y
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
C
n
for \quad\forall n:\\for \quad\forall y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-C^n
for∀n:for∀y:w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)≥Δ(y
n,y)−Cn
到这里,通常是把 C C C换成 ε \varepsilon ε(江湖人称slack variable,中文名:松弛因子),描述2等价于:
描述3:
Find
w
,
ε
1
,
⋯
,
ε
N
w,\varepsilon^1,\cdots,\varepsilon^N
w,ε1,⋯,εN minimizing
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
ε
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^N\varepsilon^n
C=21∣∣w∣∣2+λn=1∑Nεn
f
o
r
∀
n
:
f
o
r
∀
y
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
(2)
for \quad\forall n:\\for \quad\forall y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n\tag2
for∀n:for∀y:w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)≥Δ(y
n,y)−εn(2)
对于描述3中的公式2,如果
y
=
y
^
n
y=\widehat y^n
y=y
n
那么就有:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
=
0
Δ
(
y
^
n
,
y
)
=
0
w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)=0\\ \Delta(\widehat y^n, y)=0
w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)=0Δ(y
n,y)=0
剩下就是:
ε
n
≥
0
\varepsilon^n\geq0
εn≥0
描述3中的公式2就等价于:
F
o
r
∀
y
≠
y
^
n
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
For \space \forall y\neq\widehat y^n:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
For ∀y=y
n:w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)≥Δ(y
n,y)−εn,εn≥0
上面推导没看懂,老师贴心的给出了直观的解释:
Intuition Explanation
黄框与红框差距越大,它们之间的margin也就是
Δ
\Delta
Δ也就越大,因此我们要找的参数
w
w
w要满足下面的条件:

当然黄色的框框不止这两个,还有很多很多个,就是除了正确的红框之外的任意位置都可以有黄框,写成数学表达就是:
∀
y
≠
y
^
\forall y \neq \widehat y
∀y=y
,所以上面的不等式也是有无穷多个。
这样我们就很难找到一个参数
w
w
w使得所有的不等式都成立。
因此我们想办法把margin变小一点,不用
Δ
\Delta
Δ来作为margin,而是用:
Δ
−
ε
\Delta-\varepsilon
Δ−ε来作为margin(注意,使得margin变小是要减去一个正数才可以,否则减去负数就变大了。所以这里默认
ε
≥
0
\varepsilon\geq0
ε≥0,如果
ε
≤
0
\varepsilon\leq0
ε≤0会是使得上面的不等式约束更加严格。):

上图中的绿色margin长度应该变小就更加逼真了。。。
由于
ε
\varepsilon
ε的作用是放宽约束,所以起了一个名字叫松弛因子。我们当然不会希望约束放得太宽,否则margin就失去存在的意义了(例如:
ε
→
∞
\varepsilon\to\infty
ε→∞,margin 就变成了负值,随便一个参数
w
w
w就能满足条件),因此,我们还加上了一个条件就是
ε
\varepsilon
ε要最小化。
就好比妹子想找高富帅,这个条件没法找到,她也不会找一个矮矬穷,会想办法找一个高富,高帅,富帅。
下面举例:
假设我们有两个training data

对于
x
1
x^1
x1,满足下面的式子,其中红框就是
y
^
1
\widehat y^1
y
1:

对于
x
2
x^2
x2,满足下面的式子,其中红框就是
y
^
2
\widehat y^2
y
2:

根据分析,我们还希望
ε
1
+
ε
2
\varepsilon^1+\varepsilon^2
ε1+ε2还要最小,最后还考虑正则项,就是我们之前的描述3的内容了。
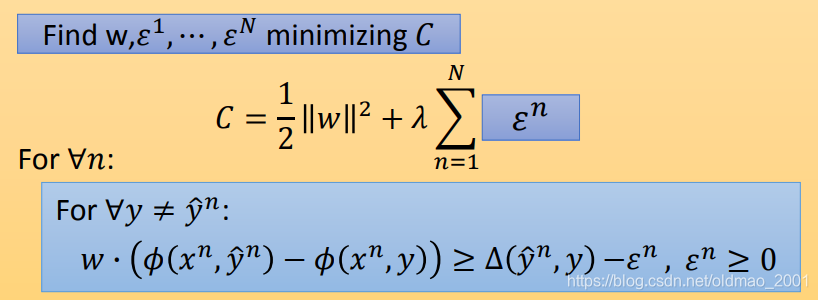
但是这个问题不好解,下面看咋弄。
Cutting Plane Algorithm for Structured SVM
问题的图形化描述
下图是参数
w
,
ε
1
,
.
.
.
,
ε
N
w,\varepsilon^1,...,\varepsilon^N
w,ε1,...,εN形成的图像,本来是高维的,这里用二维的平面来做个样例。
平面上的颜色代表了Cost
C
C
C的值,右下角有一个绿点,那个就是还没有引入任何约束的时候的Cost
C
C
C的最小值。
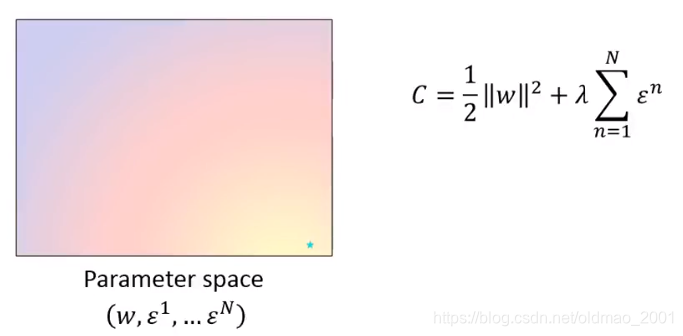
我们现在把之前推导出来的约束加上:
f
o
r
∀
n
:
f
o
r
∀
y
,
y
≠
y
^
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
for \quad\forall n:\\for \quad\forall y, y\neq\widehat y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
for∀n:for∀y,y=y
:w⋅ϕ(xn,y
n)−w⋅ϕ(xn,y)≥Δ(y
n,y)−εn,εn≥0
图像变成:

只有中间阴影部分是满足约束条件的,最小值也从右下角变成了上图中的位置。
中间是阴影形状是怎么来的呢?我们观察约束可以看到,虽然约束很多,但是很多约束实际上是冗余的,真正起到决定Cost最小值的是下图中的两条红线,其他约束去掉也不会影响结果:

既然不是所有约束都有用,我们就把无用的约束去掉,只留下有用的约束,并把这些有用的约束集合记为(英文名:Working set):
A
n
A^n
An
则约束条件变成:
f
o
r
∀
n
:
f
o
r
y
∈
A
n
,
y
≠
y
^
:
w
⋅
[
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
)
]
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
≥
0
for \quad\forall n:\\for \quad y\in A^n, y\neq\widehat y:\\w\cdot[\phi(x^n,\widehat y^n)-\phi(x^n,y)]\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon\geq0
for∀n:fory∈An,y=y
:w⋅[ϕ(xn,y
n)−ϕ(xn,y)]≥Δ(y
n,y)−εn,ε≥0
如果Working set比较小,那么Cost最小值就是有可能解出来的,下面来看如何确定Working set,用的是一个迭代的算法。
Cutting Plane Algorithm
Elements in working set
A
n
A^n
An is selected iteratively.
对每一个example都初始化它的working set ,初始化
A
n
A^n
An:
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A1,A2,...,AN
根据初始化后的
A
n
A^n
An,解方程
根据
A
n
A^n
An,解出一个
w
w
w后,用
w
w
w去update
A
n
A^n
An,这个过程不断循环。这个流程和EM很像。
Quadratic Program (QP):凸优化的二次规划问题。

下面是图解这个算法如何运作的。
Initialize
A
n
=
n
u
l
l
A^n=null
An=null,最开始是不考虑约束的。解出来就是蓝色星星那个点。

看看蓝色的点是没有办法满足哪些约束。例如下图中的红色约束:

虽然蓝点不满足很多约束,我们选择 the most violated one,这个选择标准后面再解释(应该是按垂直距离),先假设找出这条:

我们把找出来的这个约束记为:
y
′
y'
y′,然后把
y
′
y'
y′加入到working set 中:
A
n
=
A
n
∪
{
y
′
}
A^n=A^n\cup \{y'\}
An=An∪{y′}
新的working set不再是空的了,里面有东西了,根据新的working set,我们重新算最小值:

然后再看这个蓝色星星不满足哪些约束:

我们把找出来的这个约束记为:
y
′
′
y''
y′′,然后把
y
′
′
y''
y′′加入到working set 中:
A
n
=
A
n
∪
{
y
′
′
}
=
{
y
′
,
y
′
′
}
A^n=A^n\cup \{y''\}=\{y',y''\}
An=An∪{y′′}={y′,y′′}
下面又重复迭代,根据新的working set计算最小值

下面文字就不用写了。


Find the most violated one
上面挖了个坑,如何找到最小值相对应最不满足的约束条件是什么?现在来填:
Given
w
′
w'
w′ and
ε
′
\varepsilon′
ε′ from working sets at hand, which constraint is the most violated one?
先把约束和不满足(违反)约束的数学形式写出来:
Constraint:
w
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
≥
Δ
(
y
^
,
y
)
−
ε
\text{Constraint:}\quad w\cdot[\phi(x,\widehat y)-\phi(x,y)]\geq \Delta(\widehat y, y)-\varepsilon
Constraint:w⋅[ϕ(x,y
)−ϕ(x,y)]≥Δ(y
,y)−ε
Violate a Constraint:
w
′
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
<
Δ
(
y
^
,
y
)
−
ε
′
\text{Violate a Constraint:}\quad w'\cdot[\phi(x,\widehat y)-\phi(x,y)]< \Delta(\widehat y, y)-\varepsilon'
Violate a Constraint:w′⋅[ϕ(x,y
)−ϕ(x,y)]<Δ(y
,y)−ε′
在给出不满足(违反)约束的程度评价标准(上式右边减左边):
Degree of Violation:
Δ
(
y
^
,
y
)
−
ε
′
−
w
′
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
\text{Degree of Violation:}\quad \Delta(\widehat y, y)-\varepsilon'-w'\cdot[\phi(x,\widehat y)-\phi(x,y)]
Degree of Violation:Δ(y
,y)−ε′−w′⋅[ϕ(x,y
)−ϕ(x,y)]
由于
ε
′
\varepsilon'
ε′和
ϕ
(
x
,
y
^
)
\phi(x,\widehat y)
ϕ(x,y
)是固定值,不影响评价标准,所以上面式子中的这两项可以去掉:
Δ
(
y
^
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
)
\Delta(\widehat y, y)+w'\cdot\phi(x,y)
Δ(y
,y)+w′⋅ϕ(x,y)
有了评价标准后,最不满足的就是最大值那个拉:
The most violated one:
a
r
g
m
a
x
y
[
Δ
(
y
^
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
)
]
\text{The most violated one:}\quad arg\underset{y}{max}[\Delta(\widehat y, y)+w'\cdot\phi(x,y)]
The most violated one:argymax[Δ(y
,y)+w′⋅ϕ(x,y)]
算法总结
Given training data:
{
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
.
.
.
,
(
x
N
,
y
^
N
)
}
\{(x^1,\widehat y^1),(x^2,\widehat y^2),...,(x^N,\widehat y^N)\}
{(x1,y
1),(x2,y
2),...,(xN,y
N)}
对每一个training data都初始一个working set:
A
1
=
n
u
l
l
,
A
2
=
n
u
l
l
,
.
.
.
,
A
N
=
n
u
l
l
A^1=null,A^2=null,...,A^N=null
A1=null,A2=null,...,AN=null
重复执行:
解决 QP with Working Set
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A1,A2,...,AN,并更新
w
w
w
QP问题如下图:

For each training data
(
x
n
,
y
^
n
)
(x^n,\widehat y^n)
(xn,y
n)
find the most violated constraints:
y
ˉ
n
=
a
r
g
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
n
)
]
\text{find the most violated constraints: }\bar y^n=arg\underset{y}{max}[\Delta(\widehat y^n, y)+w'\cdot\phi(x,y^n)]
find the most violated constraints: yˉn=argymax[Δ(y
n,y)+w′⋅ϕ(x,yn)]
把找到的最难搞的约束更新到working set:
A
n
=
A
n
∪
y
ˉ
n
A^n=A^n\cup\bar y^n
An=An∪yˉn
Until
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A1,A2,...,AN doesn’t change any more(停止循环的条件)
Return
w
w
w
图例解释

A
1
=
n
u
l
l
,
A
2
=
n
u
l
l
A^1=null,A^2=null
A1=null,A2=null

上图的约束少写了:
ε
1
>
0
,
ε
2
>
0
\varepsilon^1>0,\varepsilon^2>0
ε1>0,ε2>0
由于没有约束,上面那个式子很容易看出来,当
w
=
0
w=0
w=0的时候,得到最小值。
然后用
w
=
0
w=0
w=0去找the most violated的约束。
对于第一个training data来说
y
ˉ
1
=
a
r
g
m
a
x
y
[
Δ
(
y
^
1
,
y
)
+
0
⋅
ϕ
(
x
,
y
1
)
]
\bar y^1=arg\underset{y}{max}[\Delta(\widehat y^1, y)+0\cdot\phi(x,y^1)]
yˉ1=argymax[Δ(y
1,y)+0⋅ϕ(x,y1)]
下面给出六个黄框框

由于
w
=
0
w=0
w=0,后面那个没有了

只剩下
Δ
\Delta
Δ,这个玩意如果黄框不和红框重叠,值就会很大:

看到
Δ
\Delta
Δ有三个一样的都最大,都是1,我们随便挑一个,右下角那个作为
y
ˉ
1
\bar y^1
yˉ1
同样去计算
y
2
y^2
y2对应的
y
ˉ
2
=
a
r
g
m
a
x
y
[
Δ
(
y
^
2
,
y
)
+
0
⋅
ϕ
(
x
,
y
2
)
]
\bar y^2=arg\underset{y}{max}[\Delta(\widehat y^2, y)+0\cdot\phi(x,y^2)]
yˉ2=argymax[Δ(y
2,y)+0⋅ϕ(x,y2)]
然后更新working set得到:

然后用新的working set解决下图QP问题(下图中的working set中有两个约束),计算得到
w
=
w
1
w=w^1
w=w1

用
w
1
w^1
w1去找the most violated的约束。

对于第一个training data来说
y
ˉ
1
=
a
r
g
m
a
x
y
[
Δ
(
y
^
1
,
y
)
+
0
⋅
ϕ
(
x
,
y
1
)
]
\bar y^1=arg\underset{y}{max}[\Delta(\widehat y^1, y)+0\cdot\phi(x,y^1)]
yˉ1=argymax[Δ(y
1,y)+0⋅ϕ(x,y1)]
我们用右上角那个
y
ˉ
1
=
1.55
\bar y^1=1.55
yˉ1=1.55的黄色框框作为the most violated的约束
当然对第二个training data也做同样的事情,然后更新working set:
然后用新的working set解决下图QP问题(下图中的working set中有四个约束),计算得到
w
=
w
2
w=w^2
w=w2

这个过程不断迭代下去,直到
A
1
,
A
2
A^1,A^2
A1,A2 不再变化为止。
这里有学生提问,老师又补充了一些知识,在Structured SVM的原版文章中,作者在更新working set上有一个条件,就是在the most violated的约束基础上还要加一个值,满足这个条件的约束才加入working set中,否则不加,这个值越大,整个算法的迭代次数就越少。
Multi-class and binary SVM
Multi-class SVM
•Problem 1: Evaluation
If there are
K
K
K classes, then we have K weight vectors
{
w
1
,
w
2
,
.
.
.
,
w
K
}
\{w^1,w^2,...,w^K\}
{w1,w2,...,wK}
y
y
y的标签自然就是:
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
y\in\{1,2,...,k,...,K\}
y∈{1,2,...,k,...,K}
F
(
x
,
y
)
=
w
y
⋅
x
→
F(x,y)=w^y\cdot\overrightarrow{x}
F(x,y)=wy⋅x
x
→
\overrightarrow{x}
x:vector, representation of
x
x
x(
x
x
x是要分类的对象,
x
→
\overrightarrow{x}
x是这个对象的向量表示)
但是之前的
F
(
x
,
y
)
F(x,y)
F(x,y)不是这样表示的,而是表示为:
F
(
x
,
y
)
=
w
⋅
ϕ
(
x
,
y
)
F(x,y)=w\cdot\phi(x,y)
F(x,y)=w⋅ϕ(x,y)
那现在我们来看看这两个式子是否等价,首先
w
w
w可以写为向量的形式,而
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y)可以表示为当
x
x
x属于第k个分类的时候,我们就把
x
→
\overrightarrow{x}
x放到
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y)这个向量的第k个位置。所以实际上,这两个表示是等价的。
w
=
[
w
1
w
2
⋮
w
k
⋮
w
K
]
ϕ
(
x
,
y
)
=
[
0
0
⋮
x
→
⋮
0
]
w=\begin{bmatrix}w^1\\ w^2\\ \vdots\\ w^k\\ \vdots\\ w^K\end{bmatrix}\quad \phi(x,y)=\begin{bmatrix}0\\ 0\\ \vdots\\ \overrightarrow{x}\\ \vdots\\ 0\end{bmatrix}
w=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡w1w2⋮wk⋮wK⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤ϕ(x,y)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡00⋮x⋮0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
• Problem 2: Inference
F
(
x
,
y
)
=
w
y
⋅
x
→
F(x,y)=w^y\cdot\overrightarrow{x}
F(x,y)=wy⋅x
我们就是要穷举所有的
y
y
y找到最大那个
y
^
\widehat y
y
y
^
=
a
r
g
m
a
x
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
F
(
x
,
y
)
=
a
r
g
m
a
x
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
w
y
⋅
x
→
\widehat y=arg\underset{y\in\{1,2,...,k,...,K\}}{max}F(x,y)=arg\underset{y\in\{1,2,...,k,...,K\}}{max}w^y\cdot\overrightarrow{x}
y
=argy∈{1,2,...,k,...,K}maxF(x,y)=argy∈{1,2,...,k,...,K}maxwy⋅x
The number of classes are usually small, so we can just enumerate them.
由于分类一般数量较小,所以直接硬算就可以。
• Problem 3: Training
Find
w
,
ε
1
,
.
.
.
,
ε
N
w,\varepsilon^1,...,\varepsilon^N
w,ε1,...,εN minimizing
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
ε
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^N\varepsilon^n
C=21∣∣w∣∣2+λn=1∑Nεn
F
o
r
∀
n
:
For\space\forall n:
For ∀n:
F
o
r
∀
y
≠
y
^
n
:
\quad \quad For\space\forall y\ne\widehat y^n:
For ∀y=y
n:
w
⋅
[
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
)
]
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(3)
w\cdot[\phi(x^n,\widehat y^n)-\phi(x^n,y)]\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0\tag3
w⋅[ϕ(xn,y
n)−ϕ(xn,y)]≥Δ(y
n,y)−εn,εn≥0(3)
有
N
N
N笔训练数据,每一个数据有
K
K
K个分类,只有一个分类是正确的,那么由
K
−
1
K-1
K−1个分类是错误的,所以我们的约束的数量就是
N
(
K
−
1
)
N(K-1)
N(K−1)
按老师的说法,这些个约束不多,直接算即可。
根据前面的定义,我们有:
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
w
y
^
n
⋅
x
→
,
w
⋅
ϕ
(
x
n
,
y
)
=
w
y
⋅
x
→
(4)
w\cdot\phi(x^n,\widehat y^n)=w^{\widehat y^n}\cdot\overrightarrow{x},\quad w\cdot\phi(x^n,y)=w^y\cdot\overrightarrow{x}\tag4
w⋅ϕ(xn,y
n)=wy
n⋅x,w⋅ϕ(xn,y)=wy⋅x(4)
把4带入3得:
w
y
^
n
⋅
x
→
−
w
y
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
w^{\widehat y^n}\cdot\overrightarrow{x}-w^y\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
wy
n⋅x−wy⋅x≥Δ(y
n,y)−εn,εn≥0
化简:
(
w
y
^
n
−
w
y
)
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(w^{\widehat y^n}-w^y)\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
(wy
n−wy)⋅x≥Δ(y
n,y)−εn,εn≥0
上式中的
Δ
(
y
^
n
,
y
)
\Delta(\widehat y^n, y)
Δ(y
n,y)按之前的说法是指正确分类和错误分类的差距,这个差距是我们可以自己定义的,例如下面:
y
∈
d
o
g
,
c
a
t
,
b
u
s
,
c
a
r
Δ
(
y
^
=
d
o
g
,
y
=
c
a
t
)
=
1
Δ
(
y
^
=
d
o
g
,
y
=
b
u
s
)
=
100
y\in dog,cat,bus,car\\ \Delta (\widehat y=dog,y=cat)=1\\ \Delta (\widehat y=dog,y=bus)=100
y∈dog,cat,bus,carΔ(y
=dog,y=cat)=1Δ(y
=dog,y=bus)=100
(defined as your wish)
Binary SVM
就是多分类中的K=2的场景,这个时候
y
∈
{
1
,
2
}
y\in\{1,2\}
y∈{1,2}
F
o
r
∀
y
≠
y
^
n
:
For\space\forall y\ne\widehat y^n:
For ∀y=y
n:
(
w
y
^
n
−
w
y
)
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(w^{\widehat y^n}-w^y)\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
(wy
n−wy)⋅x≥Δ(y
n,y)−εn,εn≥0
由于是二分类,我们可以定义当分类不正确的时候
Δ
(
y
^
n
,
y
)
=
1
\Delta(\widehat y^n, y)=1
Δ(y
n,y)=1
当
y
=
1
y=1
y=1的时候:
(
w
1
−
w
2
)
⋅
x
→
≥
1
−
ε
n
(w^1-w^2)\cdot\overrightarrow{x}\geq 1-\varepsilon^n
(w1−w2)⋅x≥1−εn
当
y
=
2
y=2
y=2的时候:
(
w
2
−
w
1
)
⋅
x
→
≥
1
−
ε
n
(w^2-w^1)\cdot\overrightarrow{x}\geq 1-\varepsilon^n
(w2−w1)⋅x≥1−εn
记:
(
w
1
−
w
2
)
=
w
(w^1-w^2)=w
(w1−w2)=w,则:
当
y
=
1
y=1
y=1的时候:
w
⋅
x
→
≥
1
−
ε
n
w\cdot\overrightarrow{x}\geq 1-\varepsilon^n
w⋅x≥1−εn
当
y
=
2
y=2
y=2的时候:
−
w
⋅
x
→
≥
1
−
ε
n
-w\cdot\overrightarrow{x}\geq 1-\varepsilon^n
−w⋅x≥1−εn
这里就推出了二分类的SVM 的形式,感觉上面的
ε
n
\varepsilon^n
εn应该对应到相应的上标。
Beyond Structured SVM(open question)
Structured SVM有一个很大的缺陷,就是它是linear的(怪怪的,不是说有一个核的方法来做划分平面,来解决非线性划分方法吗),而且特征的定义(就是那个
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y)函数)也对结果影响很大,因此可以用DNN来自动抽取特征:

Ref: Hao Tang, Chao-hong Meng, Lin-shan Lee, “An initial attempt for phoneme recognition using Structured Support Vector Machine (SVM),” ICASSP, 2010
Shi-Xiong Zhang, Gales, M.J.F., “Structured SVMs for Automatic Speech Recognition,” in Audio, Speech, and Language Processing, IEEE Transactions on, vol.21, no.3, pp.544-555, March 2013
进一步发展,DNN和Structured SVM一起进行训练

Ref: Shi-Xiong Zhang, Chaojun Liu, Kaisheng Yao, and Yifan Gong, “DEEP NEURAL SUPPORT VECTOR MACHINES FOR SPEECH RECOGNITION”, Interspeech 2015
再进一步:

C
=
1
2
∣
∣
θ
∣
∣
2
+
1
2
∣
∣
θ
′
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||\theta||^2+\cfrac{1}{2}||\theta'||^2+\lambda\sum_{n=1}^NC^n
C=21∣∣θ∣∣2+21∣∣θ′∣∣2+λn=1∑NCn
C
n
=
m
y
a
x
[
Δ
(
y
^
n
,
y
)
+
F
(
x
n
,
y
)
]
−
F
(
x
n
,
y
^
n
)
C^n= \underset{y}max{}[\Delta(\widehat y^n, y)+F(x^n,y)]-F(x^n,\widehat y^n)
Cn=ymax[Δ(y
n,y)+F(xn,y)]−F(xn,y
n)
Ref: Yi-Hsiu Liao, Hung-yi Lee, Lin-shan Lee, “Towards Structured Deep Neural Network for Automatic Speech Recognition”, ASRU, 2015



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











