




 本文深入解析Transformer-XL模型,一种超越固定长度上下文限制的注意力语言模型。文章探讨了RNN与Transformer的基本原理,详细介绍了Transformer-XL如何通过引入RNN机制和相对位置编码解决长距离依赖问题,实现更长上下文的建模。
本文深入解析Transformer-XL模型,一种超越固定长度上下文限制的注意力语言模型。文章探讨了RNN与Transformer的基本原理,详细介绍了Transformer-XL如何通过引入RNN机制和相对位置编码解决长距离依赖问题,实现更长上下文的建模。
前言
Transformer-XL:Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL:不受固定长度限制的attention语言模型
作者:Zihang Dai
单位:Carnegie Mellon University
发表会议及时间:ACL2019
在线LaTeX公式编辑器
别人的讲解
a.RNN
RNN及其变种是NLP中常用的序列建模方法。受限于其无法并行以及无法建模长距离的限制,目前已逐渐被Transformer取代。
b. Transformer
Transformer是目前最火热的序列建模方法,掌握其具体的架构以及多头自注意力机制的计算方法
c.了解Transformer-XL模型的细节
对比Transformer,XL在建模多个segment之间的依赖关系上进行了改进。同时改进了相对位置编码方式。
第一课 论文导读
RNN
自展开,自回归的模型,不能用并行
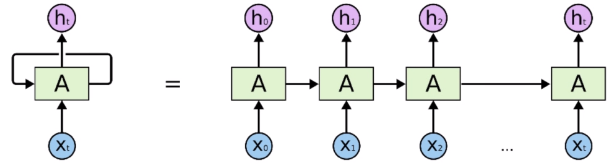
1.基于recurrent结构,不能并行
2.RNN不能很深,梯度爆炸
3顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特列长期的依赖现象LSTM依旧无能为力。
即使是变体:GRU,也不能避免上面的缺点
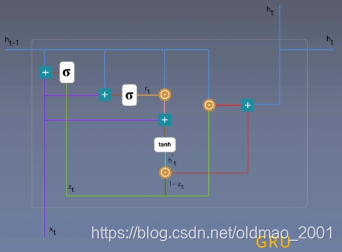
写过太多遍,直接贴图:
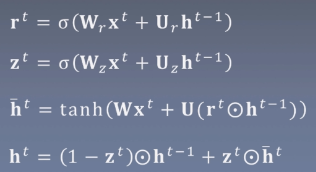
Transformer
Transformer中抛弃了传统的CNN和RNN,由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层(有残差),总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
1.第t个时间步的计算依赖第t-1时刻的结果,限制并行能力
2.顺序计算的过程中信息会丢失,长距离依赖
Transformer的提出解决了LSTM的上面的两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
概况
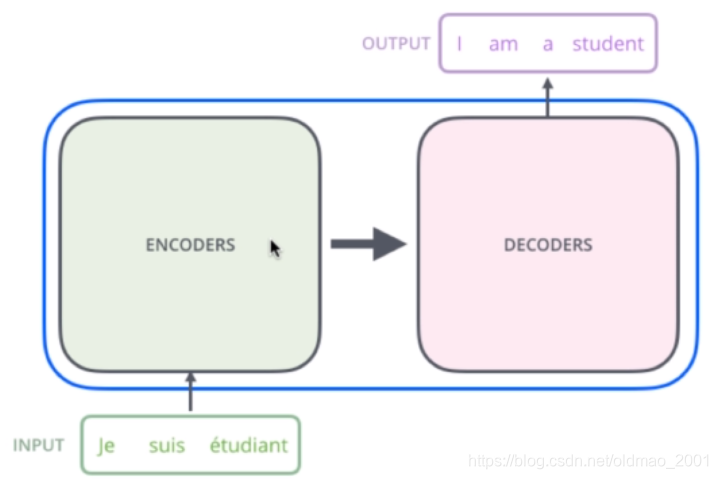
论文中的验证Transformer的实验是基于机器翻译的,下面我们就以机器翻译为例子详细剖析Transformer的结构,在机器翻译中,Transformer可概括为下图。

Transformer的本质上是一个Encoder-Decoder的结构,那么上图可以表示为下图的结构:
如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成,编码器的输出会作为解码器的输入,如下图所示
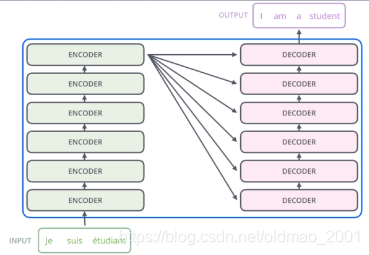
Encoder的结构如下图所示,数据首先会经过一个self-attention模块得到一个加权之后的特征向量Z,它会被送到encoder的下一个模块,即Feed Forward Neural Network,它是一个两层的全连接(第一层激活函数是ReLU,第二层没有激活函数)
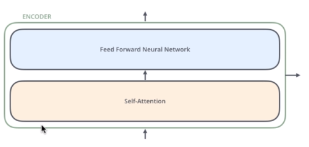
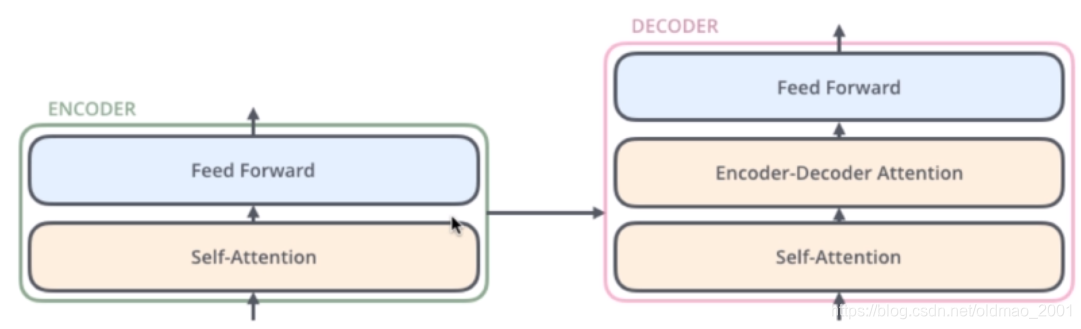
Decoder的结构如图5所示,它和Encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
1.Self-Attention:当前翻译和已经翻译的前文之间的关系;(对于自己本身而言)
2.Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。(对于Encoder而言)
自注意力机制
Attention的核心内容是为输入向量的每个单词学习一个权重。讲过很多次了,不过这次讲得比较清楚。
例子:The animal didn’t cross the street because it was too tired

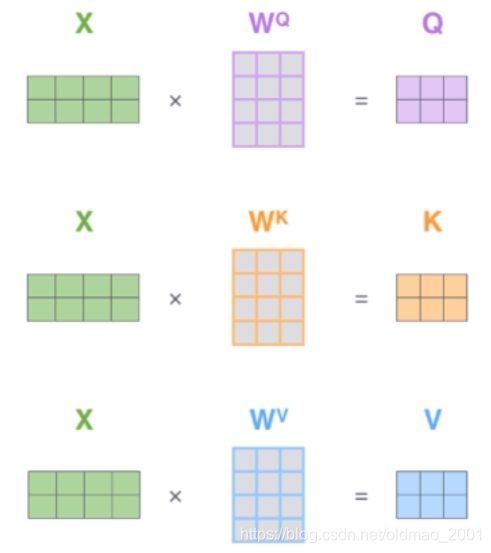
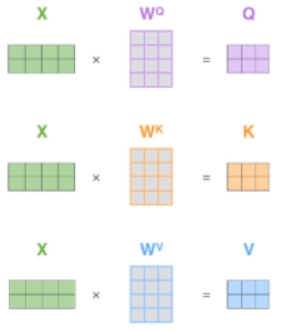
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量(q),Key向量(k)和Value向量(v),维度均是64。它们是通过3个不同的权值矩阵由嵌入向量x乘以三个不同的权值矩阵
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV得到,其中三个矩阵的尺寸也是相同的。均是512*64。
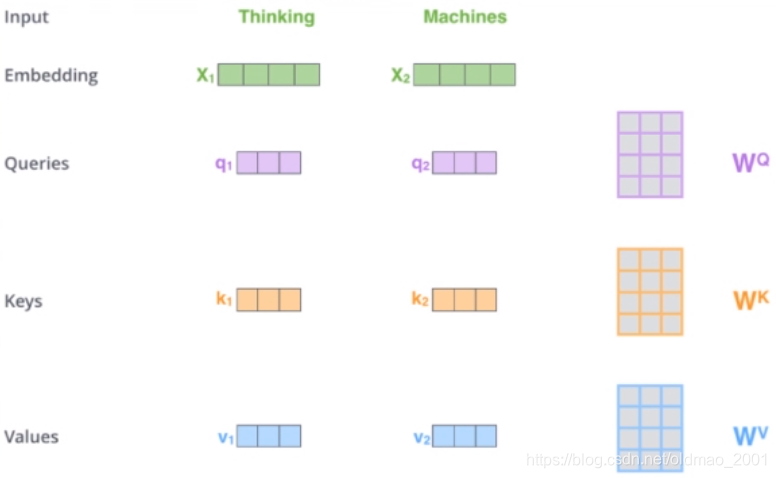
上图中的
q
1
,
k
1
,
v
1
q_1,k_1,v_1
q1,k1,v1就是x分别与
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV相乘得到的。
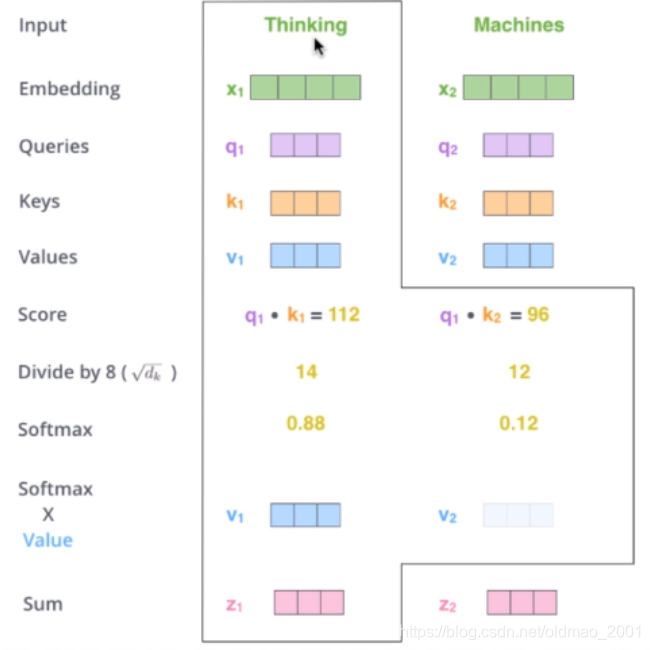
那么Query,Key,Value是什么意思呢?它们在Attention的计算中扮演着什么角色呢?我们先看一下Attention的计算方法,整个过程可以分成7步:
1.将输入单词转化成嵌入向量x;
2.根据嵌入向量得到三个向量q、k、v;
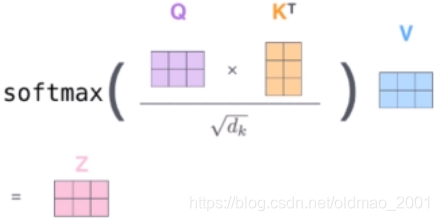
3.为每个向量计算一个score:
q
T
k
q^Tk
qTk;
4.为了梯度的稳定,Transformer使用了score归一化,即除以
d
k
\sqrt{d_k}
dk;
5.对score施以softmax激活函数;
5.softmax点乘Value值v,得到加权的每个输入向量;
6.相加之后得到最终的输出结果z。
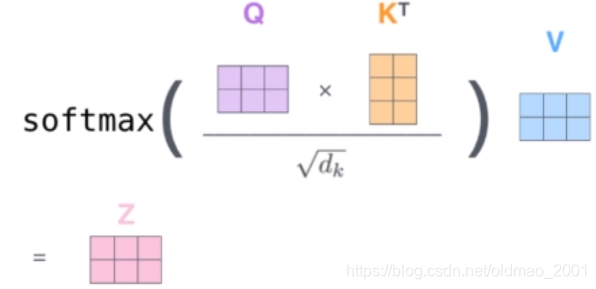
实际计算过程中是采用基于矩阵的并行计算方式,那么计算方式如下:
多头注意力机制
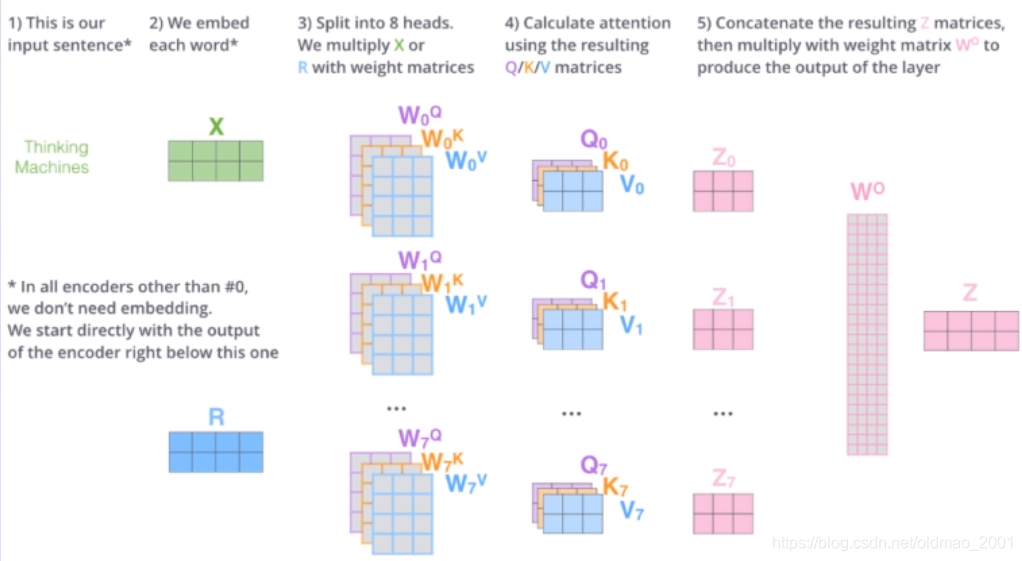
Multi-Head Attention相当于h个不同的self-attention的集成(ensemble),在这里我们以h=8举例说明。Multi-Head Attention的输出分成3步:
1.将X分别输入到8个self-attention中,得到8个加权后的特征矩阵
Z
i
Z_i
Zi。
2.将8个
Z
i
Z_i
Zi按列拼成一个大的特征矩阵;
3.特征矩阵经过一层全连接后得到输出Z。
多个头,每一个头捕获不同的表示或特征。具体如下图所示,有8个头,就有8组权重,8组
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV,分别是
W
0
Q
∼
W
7
Q
W^Q_0\sim W^Q_7
W0Q∼W7Q等,这些不同的权重都和X相乘做计算。
编码-解码注意力
解码器比编码器中多了个encoder-decoder attention:Q来之与解码器的上一个输出,K和V则来自于与编码器的输出。其计算方式完全和self-attention完全相同。
位置向量
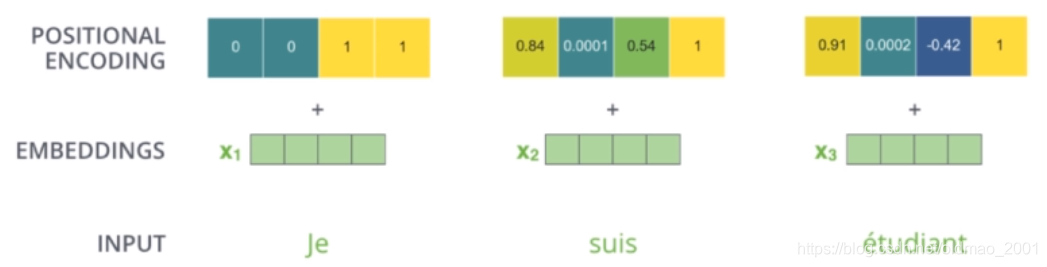
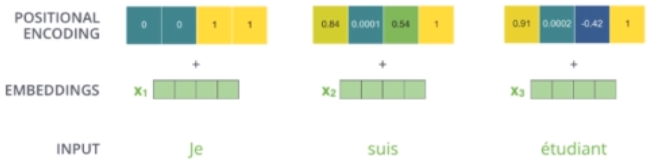
截止目前为止,我们介绍的Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
前期知识储备
RNN:了解RNN的缺陷
Self-attention:了解自注意力机制,以及它在多种NLP任务中的应用
Transformer:了解Transformer的编码-解码结构,阅读源码
第二课 论文精读
动机
在普通版的Transformer语言模型中,训练阶段因为无法支持无限长的文本输入,一般都会将文本进行截断,形成一些segments,每一个segment长几百个词,在训练的时候都只在segment内部进行训练,忽略掉segment之间的关系,因此这样的话最长能够建模的长程依赖的上限便是设置的segment长度,这样对于Transformer的self-attention优势是没有充分利用的(优势主要是指相比RNN的梯度消失问题)。
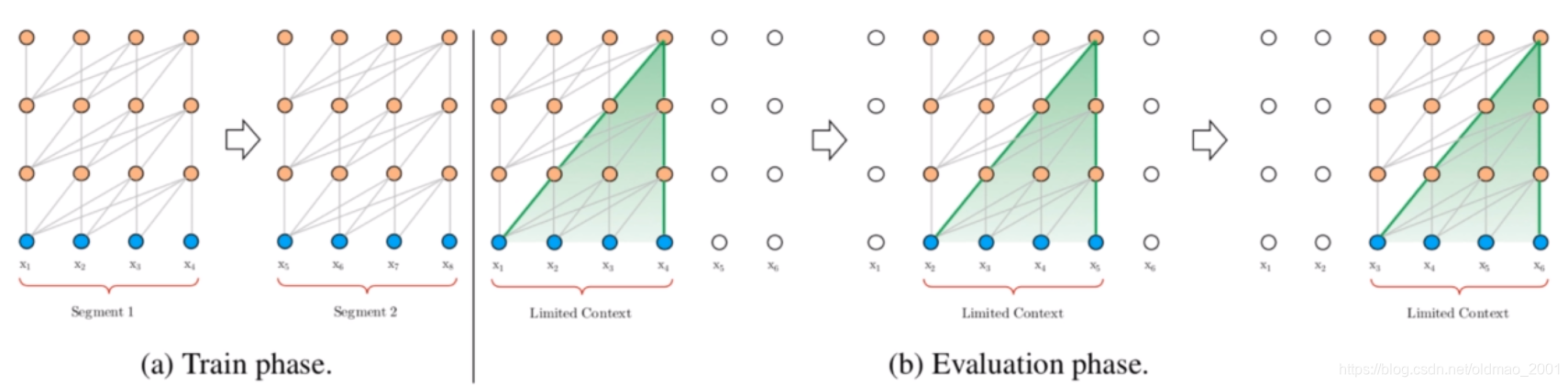
模型
针对普通版Transformer语言模型在训练阶段,各个segment缺乏联系的缺点,Transformer-XL给出的解决方法是在segment之间引入RNN机制,具体而言,就是把上一个segment计算好的hidden state进行存储,然后在计算下一个segment的时候,将上一个segment的这些信息作为一个context融入到当前segment的计算当中。下式中的n是Transformer层数,
τ
\tau
τ表示上一个segment,
τ
+
1
\tau+1
τ+1表示当前segment,简单而言就是会把上一个segment的hidden state沿着句子长度的方向与当前segment的hidden state进行concat,因此比如每个segment长度为4,那么concat之后长度就为8,然后再在这个concat过后的长度上进行Transformer操作。
h
~
τ
+
1
n
−
1
=
[
S
G
(
h
τ
n
−
1
)
∘
h
τ
+
1
n
−
1
]
,
\tilde h_{\tau+1} ^{n-1}=[SG(h_{\tau} ^{n-1})\circ h_{\tau+1} ^{n-1}],
h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1],
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
=
h
τ
+
1
n
−
1
W
q
⊤
,
h
~
τ
+
1
n
−
1
W
k
⊤
,
h
~
τ
+
1
n
−
1
W
v
⊤
,
q_{\tau+1} ^{n},k_{\tau+1} ^{n},v_{\tau+1} ^{n}=h_{\tau+1} ^{n-1}W_q^\top,\tilde h_{\tau+1} ^{n-1}W_k^\top,\tilde h_{\tau+1} ^{n-1}W_v^\top,
qτ+1n,kτ+1n,vτ+1n=hτ+1n−1Wq⊤,h~τ+1n−1Wk⊤,h~τ+1n−1Wv⊤,
h
τ
+
1
n
=
T
r
a
n
s
f
o
r
m
e
r
−
L
a
y
e
r
(
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
)
.
h_{\tau+1} ^{n}=Transformer-Layer(q_{\tau+1} ^{n},k_{\tau+1} ^{n},v_{\tau+1} ^{n}).
hτ+1n=Transformer−Layer(qτ+1n,kτ+1n,vτ+1n).
h
τ
n
−
1
h_{\tau} ^{n-1}
hτn−1表示上一个segment的第n-1层,SG表示对梯度进行截断计算,这样的计算不会影响(更新)上一个segment的第n-1层的参数。
∘
\circ
∘表示拼接

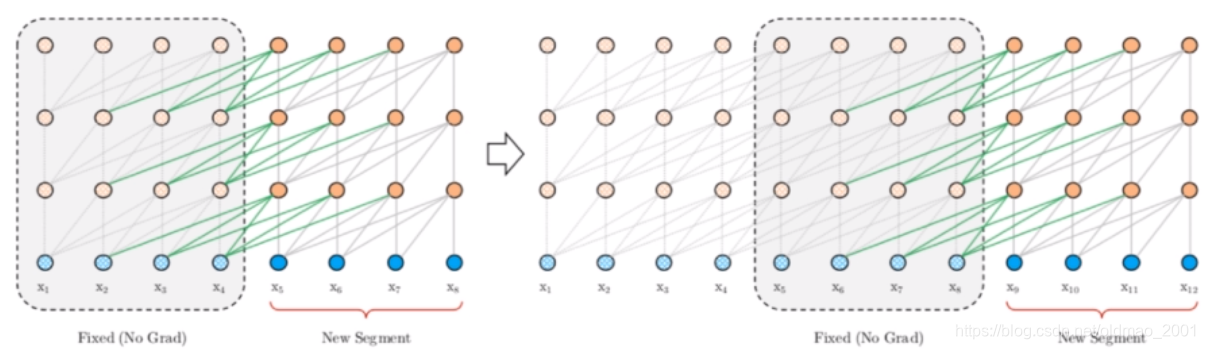
用这种方法能够建模得到的最长依赖为NL,N是Transformer的层数,L是每个segment的长度。这里的原因是每一层都可以往前建模L的依赖,累积N层后,最长的依赖关系便是NL。注意,该方法可以存储多个segment的隐状态来继续增大感受野,而不仅仅局限于前一个segment。
为了建模位置信息,普通的Transformer引入了一个positional embedding,如果在recurrence-level segement中也同样使用这样的absolute position embedding的话可能会有个问题,如下式所示,因为这两个segment使用的是同一个,那么可能会导致模型无法区分这两个segment的相对位置。比如,如果前一个segment的长度为4,其位置序列为[0,1,2,3]。当处理当前的segment时,我们将两个segment合并,得到位置
[0,1,2,3,0,1,2,3],其中每个位置id的语义在整个序列中是不连贯的。
h
τ
+
1
=
f
(
h
τ
,
E
s
τ
+
1
+
U
1
:
L
)
h_{\tau+1}=f(h_\tau,E_{s_{\tau+1}}+U_{1:L})
hτ+1=f(hτ,Esτ+1+U1:L)
h
τ
=
f
(
h
τ
−
1
,
E
s
τ
+
U
1
:
L
)
h_\tau=f(h_{\tau-1},E_{s_{\tau}}+U_{1:L})
hτ=f(hτ−1,Esτ+U1:L)
为了解决这个问题,本文提出了一种新的positional embedding方法:
第一步:
第二步:
第三步
位置信息在第一步的时候就和词向量进行了相加。最后整个公式表达出来如下:
A
i
,
j
a
b
s
(
W
q
(
E
x
i
+
U
i
)
)
T
+
W
k
(
E
x
j
+
U
i
)
A_{i,j}^{abs}(W_q(E_{x_i}+U_i))^T+W_k(E_{x_j}+U_i)
Ai,jabs(Wq(Exi+Ui))T+Wk(Exj+Ui)
U就是位置信息,把上面的公式进行拆分得到:
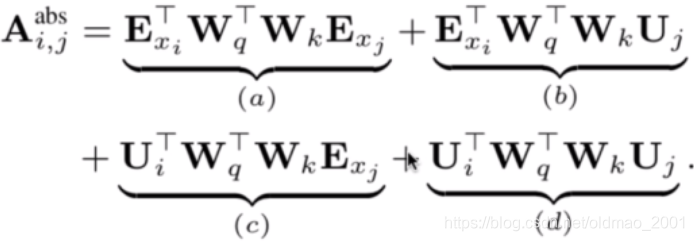
这里的每一项分别表示:
a第i个词与第j个词的语义相关性
b第i个词与第j个词的位置做了一个相乘
c第i个词的位置与第j个词的语义
d第i个词与第j个词的位置
我们想要表示每个词之间的相对位置,因此把
U
i
,
U
j
U_i,U_j
Ui,Uj替换掉,变成i与j之间差多少个词,也就是下面蓝色的部分
(请忽略中间那个箭头)
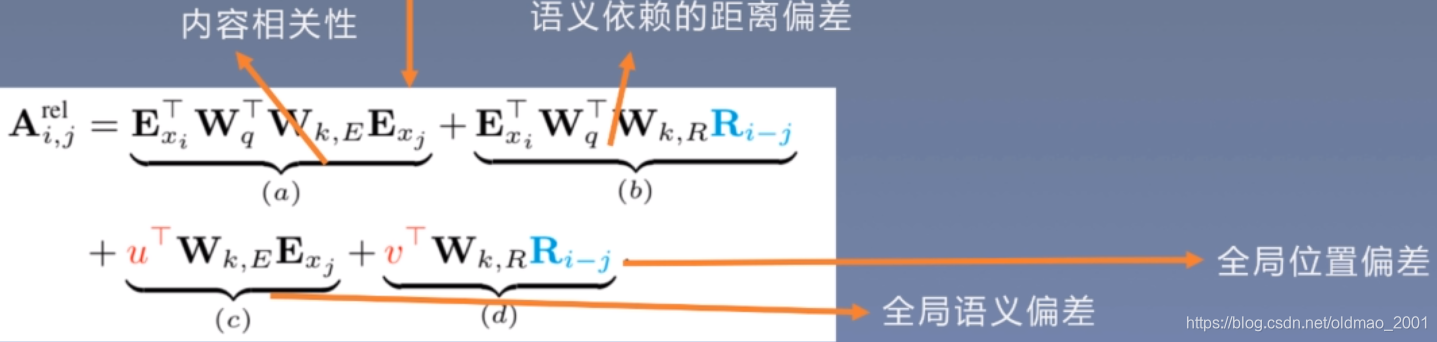
因此,对于位置编码,本文工作如下:
1.引入相对位置编码,用的是Transformer里用的sinusoid encoding matrix
2.引入u和v,在计算self-attention时,由于query所有位置对应的query向量是一样的,因此不管的query位置如何,对不同单词的attention偏差应保持相同。
实验结果
主要结果
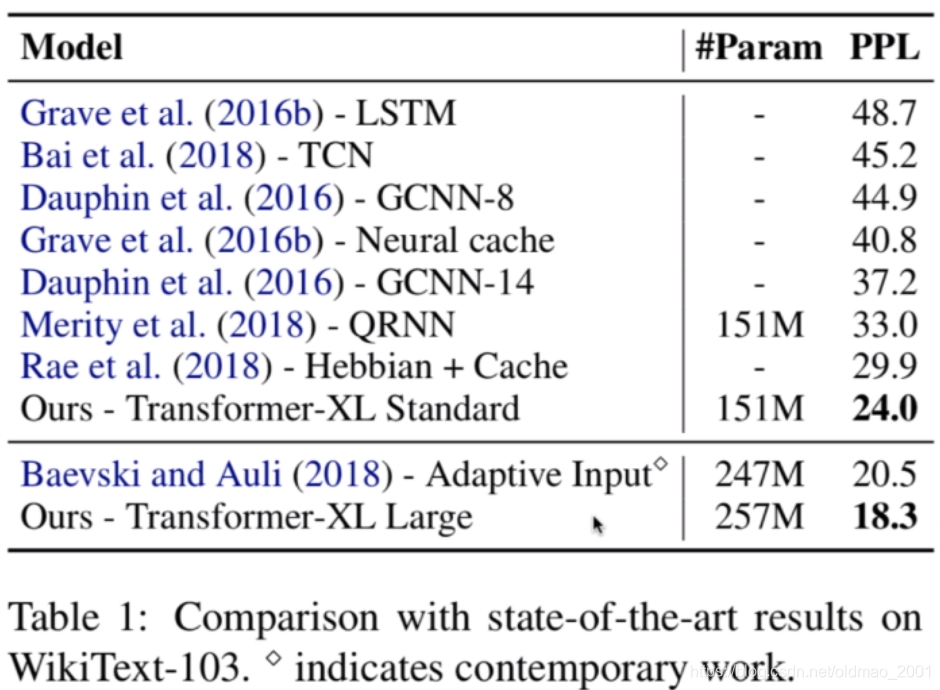

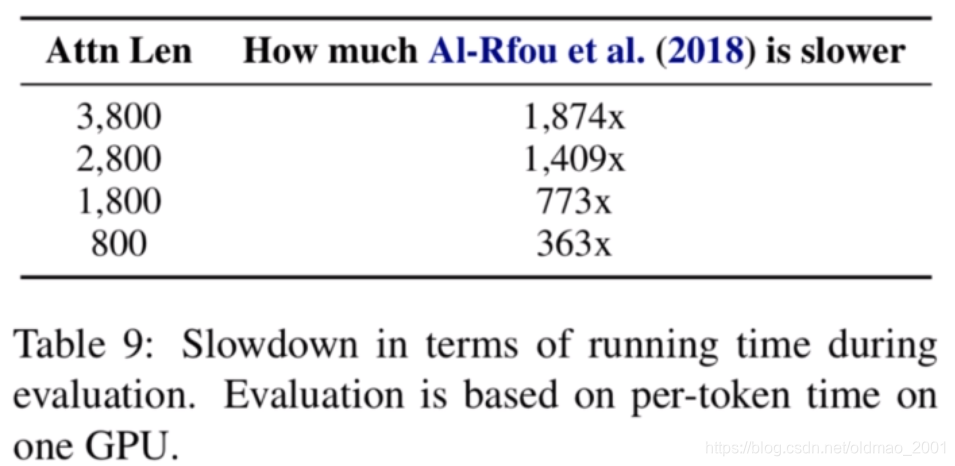
下图是表示本文的方法要比LSTM能够对更长的上下文进行建模。

总结
A.能够建模更长上下文
1.Recurrence机制
2.相对位置表示
B.在语言模型任务上获得了最好性能。加快速度
C.对后续工作有很大启发,XLNet实验分析十分详尽



















 2660
2660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











