




 本文介绍了一种利用Python爬虫技术抓取百度翻译API中英文翻译内容的方法。通过分析百度翻译网页请求流程,确定了POST请求方式及所需参数,最终实现用户输入英文单词后自动获取其汉语翻译。
本文介绍了一种利用Python爬虫技术抓取百度翻译API中英文翻译内容的方法。通过分析百度翻译网页请求流程,确定了POST请求方式及所需参数,最终实现用户输入英文单词后自动获取其汉语翻译。
一 需求
爬取百度翻译中英文内容的翻译解释
如下图所示。首先打开百度翻译,输入cat,然后右击一下选择“检查”----“network”----刷新url界面----选择sug文件----选择preview----找到英文单词的四个翻译解释。
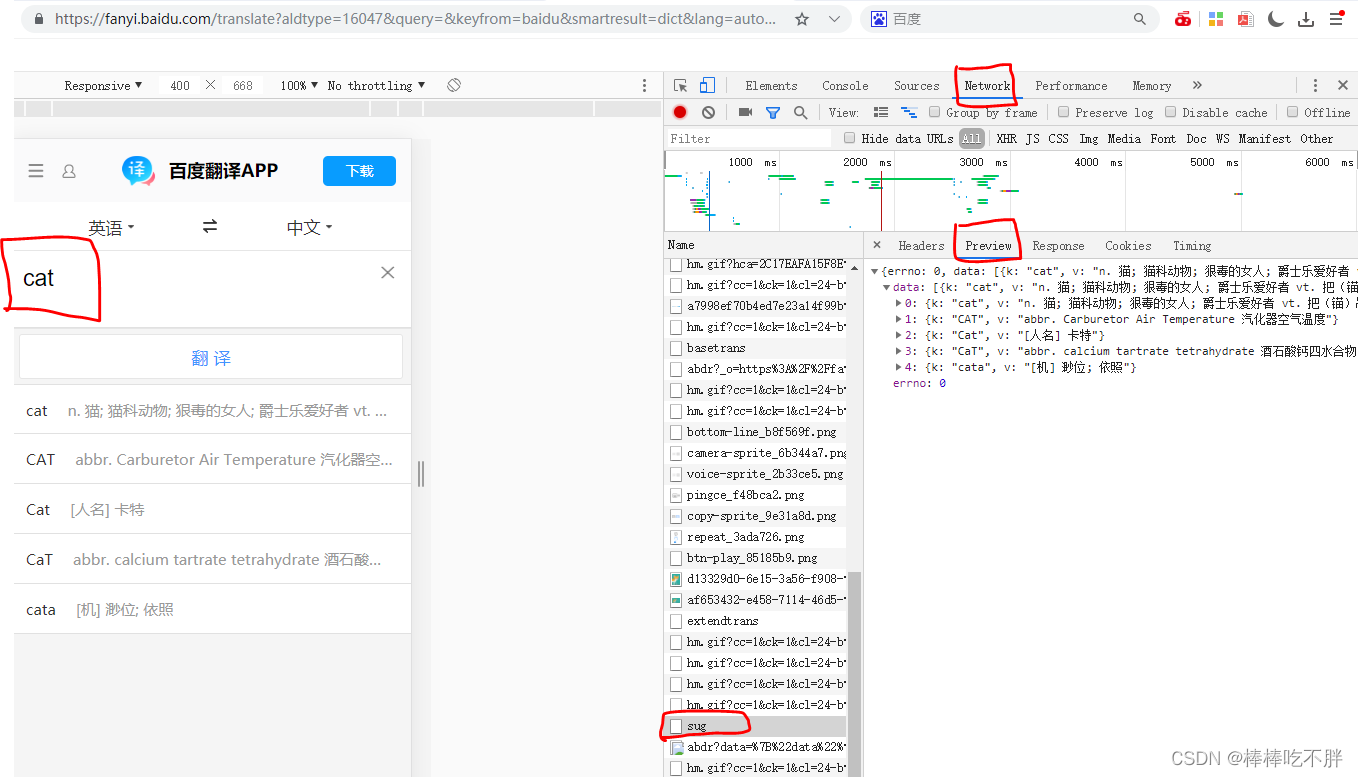
二 分析
首先找到需要搜索的url,并确定访问该网页是get还是post方式。
和上述步骤相似,但要选择headers,在下方会显示url信息,以及访问方式post
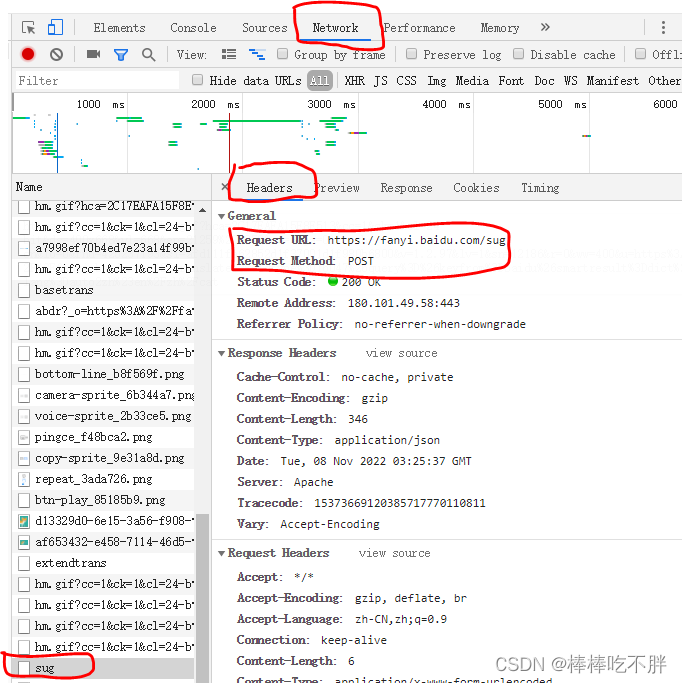
接着我们需要知道发送的数据是什么。
依旧是这一页面的内容,往下拉到底,找到Form Data,可以看到kw是cat。
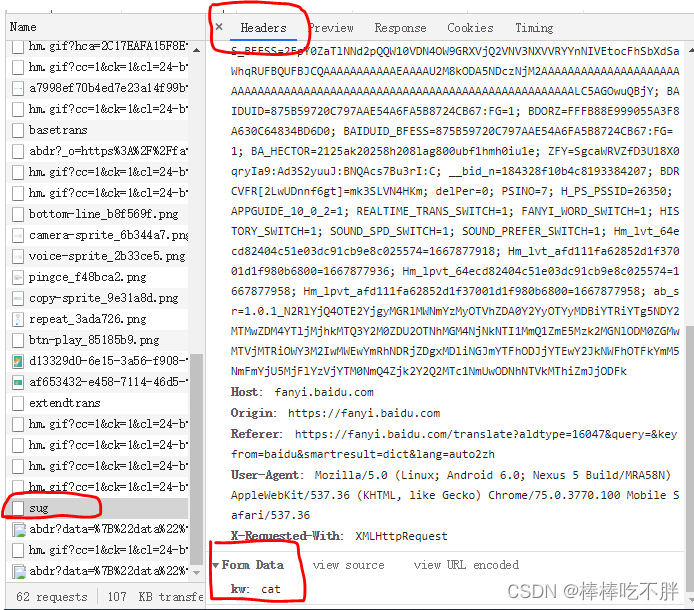
于是我们在写代码时,需要创建一个字典作为赋值数据的对象,里面的参数就是kw。
需要的信息已经收集完毕,接下来就是代码工作。
三 代码
import requests
# 找到的url
url = "https://fanyi.baidu.com/sug"
# 要翻译的英文
cont = input("请输入你要翻译的英文:")
# 要发送的数据必须存放在字典中
dict = {
"kw": cont
}
# 发送的post请求,通过data参数传递
response = requests.post(url, data=dict)
# 将服务器返回的数据直接返回成json格式,可以直接阅读
print(response.json())
# 关闭访问的链接,防止以后访问其他网页报错
response.close()
执行代码,交互式输入自己想要查询的英文单词汉语意思,就可以得到如下结果

此外,如果最后一行代码替换成print(response.text)
需要经过一番转换才能得到我们需要的结果。


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









