



1、Tranformer 架构图
来源:arxiv:1706.03762v7
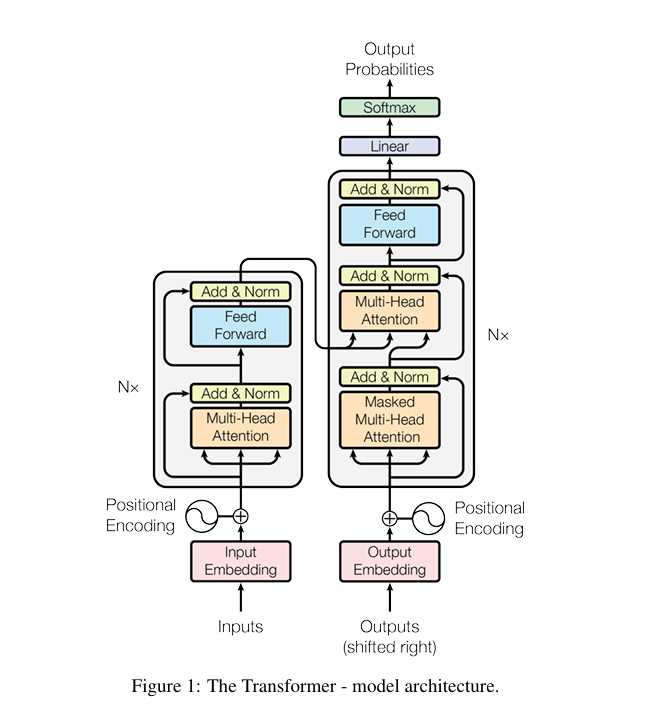
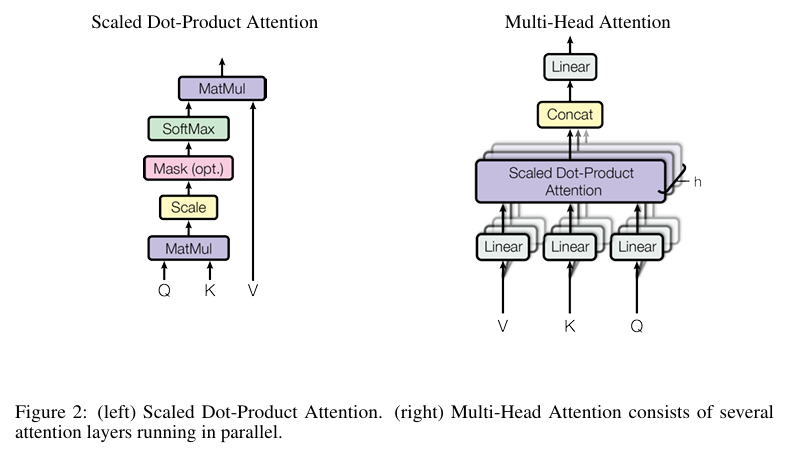
| 标准 Transformer 核心组件 | 代码实现对应类 / 模块 | 功能匹配度 |
|---|---|---|
| 位置编码(Positional Encoding) | PositionalEncoding类 | 完全匹配(正弦 / 余弦编码,不参与梯度更新) |
| 多头注意力(Multi-Head Attention) | MultiHeadAttention类 | 完全匹配(线性映射→分头→缩放点积→合并→输出映射) |
| 前馈网络(Feed-Forward Network) | FeedForwardNetwork类 | 完全匹配(Linear(d_model→d_ff)→ReLU→Dropout→Linear(d_ff→d_model)) |
| 编码器层(Encoder Layer) | EncoderLayer类 | 完全匹配(自注意力 + 残差 / 层归一化 → 前馈网络 + 残差 / 层归一化) |
| 解码器层(Decoder Layer) | DecoderLayer类 | 完全匹配(掩码自注意力 → 编码器 - 解码器注意力 → 前馈网络,均含残差 / 层归一化) |
| 完整 Transformer | Transformer类 | 完全匹配(嵌入层→位置编码→编码器堆叠→解码器堆叠→输出层) |
在标准 Transformer 中,“Output Embedding” 的核心作用是 “将目标语言的离散 token 转为向量,用于与解码器输出计算损失”,但代码中未单独命名该层,而是通过以下两部分协同实现:
-
目标语言嵌入层(
decoder_embedding):
训练时,目标序列(如翻译任务的 “参考译文”)先通过decoder_embedding转为向量(即 “目标 token 的嵌入”),作为解码器的输入(配合位置编码)。这一步本质是 “为待预测的目标 token 生成嵌入”,承担了 Output Embedding 的 “向量转换” 功能。 -
输出线性层(
fc_out):
解码器的最终输出(维度d_model)通过fc_out(nn.Linear(d_model, tgt_vocab_size))映射到 “目标词汇表维度”,得到每个 token 的预测概率(后续可通过F.log_softmax计算交叉熵损失)。这一步承担了 Output Embedding 的 “与预测结果对齐、计算损失” 功能。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# 1. 位置编码(Positional Encoding):为输入添加位置信息
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 预计算位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度用正弦
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度用余弦
pe = pe.unsqueeze(0) # 扩展为 (1, max_len, d_model),适配batch维度
self.register_buffer('pe', pe) # 不参与梯度更新的缓冲层
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = x + self.pe[:, :x.size(1), :]
return x
# 2. 多头注意力(Multi-Head Attention)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % n_heads == 0, "d_model必须能被n_heads整除"
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads # 每个头的维度
# 线性层:将Q、K、V映射到d_model维度
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
# 输出线性层
self.W_o = nn.Linear(d_model, d_model)
def split_heads(self, x):
# 拆分多头:(batch_size, seq_len, d_model) → (batch_size, n_heads, seq_len, d_k)
batch_size = x.size(0)
return x.view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
def scaled_dot_product_attention(self, q, k, v, mask=None):
# 计算注意力分数:Q·K^T / √d_k
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用掩码(如padding mask或look-ahead mask)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 注意力权重归一化(softmax)
attn_weights = F.softmax(scores, dim=-1)
# 加权求和V
output = torch.matmul(attn_weights, v)
return output, attn_weights
def forward(self, q, k, v, mask=None):
# 1. 线性映射
q = self.W_q(q)
k = self.W_k(k)
v = self.W_v(v)
# 2. 拆分多头
q = self.split_heads(q)
k = self.split_heads(k)
v = self.split_heads(v)
# 3. 缩放点积注意力
attn_output, attn_weights = self.scaled_dot_product_attention(q, k, v, mask)
# 4. 合并多头:(batch_size, n_heads, seq_len, d_k) → (batch_size, seq_len, d_model)
batch_size = attn_output.size(0)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, -1, self.n_heads * self.d_k)
# 5. 输出线性层
output = self.W_o(attn_output)
return output, attn_weights
# 3. 前馈网络(Feed-Forward Network)
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff) # 第一层线性变换
self.fc2 = nn.Linear(d_ff, d_model) # 第二层线性变换
self.dropout = nn.Dropout(dropout) # Dropout层(防止过拟合)
def forward(self, x):
# x: (batch_size, seq_len, d_model) → (batch_size, seq_len, d_ff) → (batch_size, seq_len, d_model)
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return x
# 4. 编码器层(Encoder Layer):多头注意力 + 前馈网络(均含残差连接和层归一化)
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads) # 自注意力
self.ffn = FeedForwardNetwork(d_model, d_ff, dropout) # 前馈网络
# 层归一化(Layer Normalization)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout层
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 1. 自注意力 + 残差连接 + 层归一化
attn_output, _ = self.self_attn(x, x, x, mask) # Q=K=V(自注意力)
x = x + self.dropout1(attn_output) # 残差连接
x = self.norm1(x) # 层归一化
# 2. 前馈网络 + 残差连接 + 层归一化
ffn_output = self.ffn(x)
x = x + self.dropout2(ffn_output) # 残差连接
x = self.norm2(x) # 层归一化
return x
# 5. 解码器层(Decoder Layer):掩码自注意力 + 编码器-解码器注意力 + 前馈网络
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.masked_self_attn = MultiHeadAttention(d_model, n_heads) # 掩码自注意力(防止看未来信息)
self.enc_dec_attn = MultiHeadAttention(d_model, n_heads) # 编码器-解码器注意力
self.ffn = FeedForwardNetwork(d_model, d_ff, dropout) # 前馈网络
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
# Dropout层
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, tgt_mask=None, src_mask=None):
# 1. 掩码自注意力 + 残差连接 + 层归一化
attn1, _ = self.masked_self_attn(x, x, x, tgt_mask)
x = x + self.dropout1(attn1)
x = self.norm1(x)
# 2. 编码器-解码器注意力(Q=解码器输出,K=V=编码器输出)+ 残差连接 + 层归一化
attn2, _ = self.enc_dec_attn(x, enc_output, enc_output, src_mask)
x = x + self.dropout2(attn2)
x = self.norm2(x)
# 3. 前馈网络 + 残差连接 + 层归一化
ffn_output = self.ffn(x)
x = x + self.dropout3(ffn_output)
x = self.norm3(x)
return x
# 6. 完整Transformer类
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, n_layers=6,
n_heads=8, d_ff=2048, dropout=0.1, max_len=5000):
super(Transformer, self).__init__()
# 编码器部分
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model) # 源语言嵌入
self.pos_encoding = PositionalEncoding(d_model, max_len) # 位置编码
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_layers)
]) # 堆叠n_layers个编码器层
# 解码器部分
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model) # 目标语言嵌入
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_layers)
]) # 堆叠n_layers个解码器层
# 输出层(映射到目标词汇表维度)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
# 初始化参数
self._init_weights()
def _init_weights(self):
# 线性层和嵌入层参数初始化
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def generate_mask(self, src, tgt):
# 1. 源语言掩码(src_mask):掩盖padding位置(值为0的位置)
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # (batch_size, 1, 1, src_seq_len)
# 2. 目标语言掩码(tgt_mask):包含padding掩码 + look-ahead掩码(防止看未来token)
tgt_pad_mask = (tgt != 0).unsqueeze(1).unsqueeze(3) # (batch_size, 1, tgt_seq_len, 1)
tgt_seq_len = tgt.size(1)
# look-ahead掩码:上三角矩阵(值为0的位置表示被掩盖)
tgt_look_ahead_mask = torch.triu(torch.ones(tgt_seq_len, tgt_seq_len, device=tgt.device), diagonal=1)
tgt_look_ahead_mask = tgt_look_ahead_mask == 0 # 反转:True表示可关注,False表示掩盖
# 合并padding掩码和look-ahead掩码
tgt_mask = tgt_pad_mask & tgt_look_ahead_mask # (batch_size, 1, tgt_seq_len, tgt_seq_len)
return src_mask, tgt_mask
def forward(self, src, tgt):
# 1. 生成掩码
src_mask, tgt_mask = self.generate_mask(src, tgt)
# 2. 编码器前向传播
enc_x = self.encoder_embedding(src) * math.sqrt(self.d_model) # 嵌入层(缩放)
enc_x = self.pos_encoding(enc_x) # 添加位置编码
for enc_layer in self.encoder_layers:
enc_x = enc_layer(enc_x, src_mask) # 编码器层堆叠
# 3. 解码器前向传播
dec_x = self.decoder_embedding(tgt) * math.sqrt(self.d_model) # 嵌入层(缩放)
dec_x = self.pos_encoding(dec_x) # 添加位置编码
for dec_layer in self.decoder_layers:
dec_x = dec_layer(dec_x, enc_x, tgt_mask, src_mask) # 解码器层堆叠
# 4. 输出层(映射到词汇表)
output = self.fc_out(dec_x) # (batch_size, tgt_seq_len, tgt_vocab_size)
return output
# ------------------- 测试代码 -------------------
if __name__ == "__main__":
# 超参数设置(与原Transformer论文一致)
src_vocab_size = 1000 # 源语言词汇表大小
tgt_vocab_size = 1000 # 目标语言词汇表大小
d_model = 512 # 模型维度(嵌入层/注意力层输出维度)
n_layers = 6 # 编码器/解码器堆叠层数
n_heads = 8 # 多头注意力头数
d_ff = 2048 # 前馈网络隐藏层维度
dropout = 0.1 # Dropout概率
# 初始化Transformer模型
model = Transformer(
src_vocab_size=src_vocab_size,
tgt_vocab_size=tgt_vocab_size,
d_model=d_model,
n_layers=n_layers,
n_heads=n_heads,
d_ff=d_ff,
dropout=dropout
)
# 构造测试输入(模拟 batch_size=2, src_seq_len=10, tgt_seq_len=8 的数据)
src = torch.randint(1, src_vocab_size, (2, 10)) # 源语言输入(避免0,0为padding)
tgt = torch.randint(1, tgt_vocab_size, (2, 8)) # 目标语言输入(训练时用tgt[:-1],预测用tgt[:i])
# 模型前向传播
output = model(src, tgt)
# 输出结果形状:(batch_size, tgt_seq_len, tgt_vocab_size)
print(f"输入源序列形状: {src.shape}")
print(f"输入目标序列形状: {tgt.shape}")
print(f"模型输出形状: {output.shape}") 请仔细检查代码,是否符合transformer 的标准架构,有output embedding 吗

















 2336
2336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









