







 本文详细介绍了基于Hotspot的JVM垃圾收集器,包括串行、并行、吞吐量优先、并发标记清除、G1等收集器的特性、适用场景及关键参数配置。深入探讨了各收集器在不同代的垃圾回收策略,如复制算法、标记压缩算法,并分析了G1收集器的创新机制。
本文详细介绍了基于Hotspot的JVM垃圾收集器,包括串行、并行、吞吐量优先、并发标记清除、G1等收集器的特性、适用场景及关键参数配置。深入探讨了各收集器在不同代的垃圾回收策略,如复制算法、标记压缩算法,并分析了G1收集器的创新机制。
下面的 JVM 垃圾收集器都是基于 Hotspot 的,至于其他例如 JRockit 的会有所不同,但是原理都差不多,可能对于内存的划分等方面有些差异。
首先看看各收集器之间的共存关系
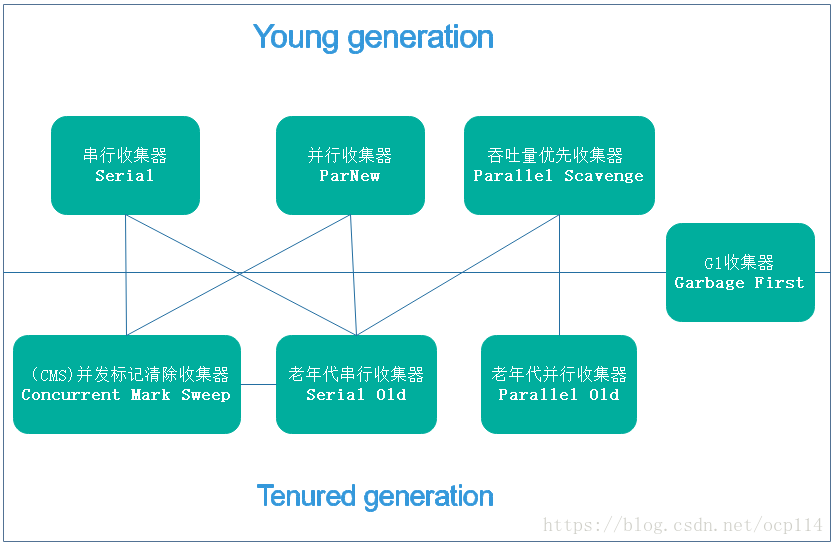
- Young generation 上半部分表示年轻代(新生代)可用的的收集器
- Tenured generation 下半部分表示老年代可用的的收集器
一、串行收集器(Serial)
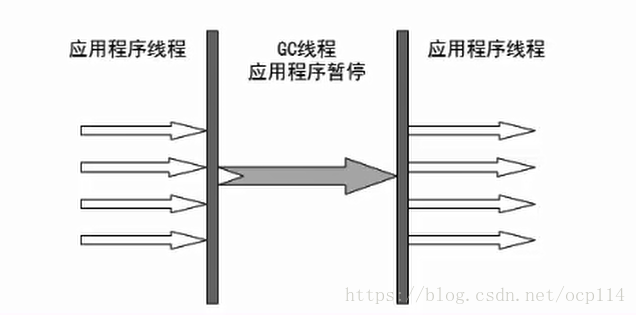
- 单线程
- 可能会产生较长时间停顿,但是垃圾回收效率高
- 新生代使用复制算法
- -XX:+UseSerialGC: 启用该收集器(新生代老年代都是这个)
二、并行收集器(ParNew)
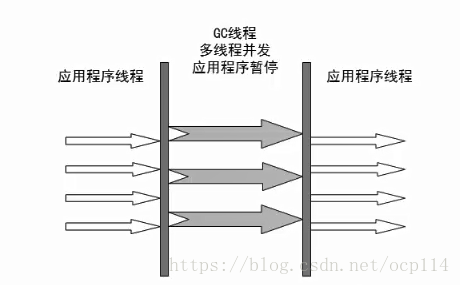
- 多线程,但需要多核 CPU 支持
- 是 Serial 的并行版本
- 新生代使用复制算法
- -XX:+UseParNewGC: 启用该收集器
- -XX:+ParallelGCThreads: 指定线程数量
- -XX:+UseAdaptiveSizePolicy: 该参数只能和并行收集器并用,打开后 -Xmn(新生代大小)、-XX:SurvivorRatio(eden: survivor 的比值)、-XX:PretenureSizeThreshold(晋升老年代的年龄,也就是被 GC 多少次后还没回收的次数)就不用设置了,JVM 会根据 GC 的情况动态调整上面的参数以更好适应实际需要
三、吞吐量优先收集器(Parallel Scavenge)
- 同样是多线程收集器,和 ParNew 类似,需要多核 CPU 支持
- 更加关注吞吐量(用户可用的时间,目标是减少 GC 停顿时间)
- 新生代使用复制算法
- -XX:+UseParallelGC: 启用该收集器
- 启用时,默认新生代并行 + 老年代串行
- -XX:MaxGCPauseMillis: 让 GC 尽量控制在该最大垃圾收集停顿时间之内
- -XX:GCTimeRatio: 设置吞吐量大小,将尽量控制在程序执行总时间程序执行总时间的 1/(1 + n) 内完成 GC,n 取值 0 - 100,默认 99,即 1%
- -XX:MaxGCPauseMillis 和 -XX:GCTimeRatio 两个相矛盾,所以要根据实际情况调节
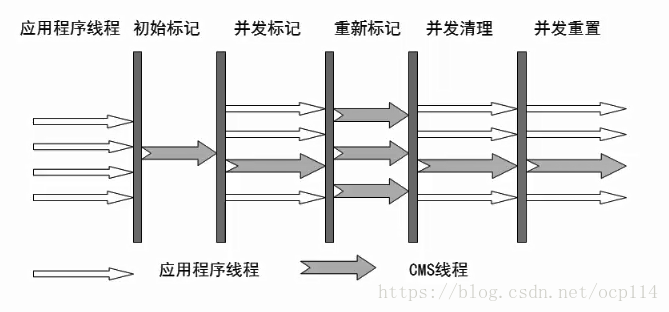
四、并发标记清除收集器(Concurrent Mark Sweep)
- 多线程,但需要多核 CPU 支持
- 目标是尽量减少老年代全局停顿时间
- 并发阶段与用户线程一起执行,会降低吞吐量
- 新生代默认使用 ParNew 收集器
- 采用标记清除算法
- 并发阶段会降低吞吐量,清理不彻底,不能在空间快满的是否再来执行,如果回收失败会使用串行收集器作为后背
- -XX:+UseConcMarkSweepGC: 启用该收集器
- -XX:+ParallelGCThreads: 指定线程数量
- -XX:+CMSInitiatingOccupancyFraction: 设置 CMS 收集器在老年代空间被使用多少后触发,默认为 68%
- -XX:+UseFullGCsBeforeCompaction: 设定进行多少次 CMS 垃圾回收后,进行一次内存压缩。
- -XX:+CMSClassUnloadingEnabled: 允许对类元数据进行回收
- -XX:+CMSParallelRemarkEndable: 启用并行重标记
- -XX:CMSInitatingPermOccupancyFraction: 当永久区占用率达到这一百分比后,启动 CMS 回收 (前提是-XX:+CMSClassUnloadingEnabled 激活了)
- -XX:UseCMSInitatingOccupancyOnly: 表示只在到达阈值的时候,才进行 CMS 回收
- -XX:+CMSIncrementalMode: 使用增量模式,比较适合单 CPU
五、老年代串行收集器(Serial Old)
- 和 Serial 一样,都是串行回收,差别在于老年代使用标记压缩算法
六、老年代并行收集器(Parallel Old)
- 老年代使用标记压缩算法
- -XX:UseParallelOldGC: 启用该收集器
- 启用时,默认新生代使用 Parallel Scavenge + 老年代并行
七、G1 收集器(Garabage Frist)
-
新生代老年代都能用的垃圾收集器
-
取消了新生代和老年代的做法,取而代之的是 把内存划分为若干个大小相等的区域/分区(Region)的做法,但是同样可以用分代的思想来理解数据的存放区域(这就是逻辑分区和物理分区的区别)
-
这里还多了一个 Humongous 区域,用来存放短时间的大对象(超过分区容量 50%),便于识别和清理,如果一个 H 区装不下,那么会寻找多个连续的 H 区内存空间来存放
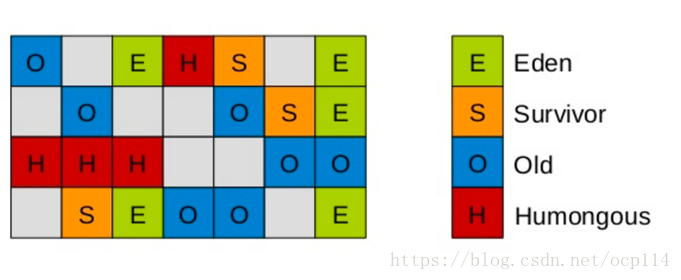
-
垃圾收集依然会 全局停顿(Stop The World),但是这个时间是可控的,然而可控的代价就是 G1 会根据目标暂停时间自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间越大
-
虽然表面上看程序员调优 JVM 的工作减轻了,但是内部结构却变复杂了
-
相关名词:
- 分区 Region
- 卡片 Card
- 堆 Heap
- 分代 Generation
- 本地分配缓冲 Local allocation buffer (Lab)
- 应用线程本地缓冲区(TLAB)
- GC 本地缓冲区(GCLAB)
- 晋升本地缓冲区(PLAB)
- 巨型对象 Humongous Region
- 已记忆集合 Remember Set (RSet)
- Per Region Table (PRT)
- 收集集合 (CSet)
- 年轻代收集集合 CSet of Young Collection
- 混合收集集合 CSet of Mixed Collection分区 Region
- 卡片 Card
- 堆 Heap
- 分代 Generation
- 本地分配缓冲 Local allocation buffer (Lab)
- 应用线程本地缓冲区(TLAB)
- GC 本地缓冲区(GCLAB)
- 晋升本地缓冲区(PLAB)
- 巨型对象 Humongous Region
- 已记忆集合 Remember Set (RSet)
- Per Region Table (PRT)
- 收集集合 (CSet)
- 年轻代收集集合 CSet of Young Collection
- 混合收集集合 CSet of Mixed Collection
- 写前栅栏 Pre-Write Barrrier
- 写后栅栏 Post-Write Barrrier
- 起始快照算法 Snapshot at the beginning (SATB)
- 并发优化线程 Concurrence Refinement Threads
- 并发标记周期 Concurrent Marking Cycle
- 并发标记线程 Concurrent Marking Threads
- 初始标记 Initial Mark
- 根分区扫描 Root Region Scanning
- 并发标记 Concurrent Marking
- 存活数据计算 Live Data Accounting
- 重新标记 Remark
- 清除 Cleanup
- 外部根分区扫描 Ext Root Scanning
- 更新已记忆集合 Update RS
- RSet扫描 Scan RS
- 代码根扫描 Code Root Scanning
- 转移和回收 Object Copy
- 终止 Termination
- GC外部的并行活动 GC Worker Other
- 代码根更新 Code Root Fixup
- 代码根清理 Code Root Purge
- 清除全局卡片标记 Clear CT
- 选择下次收集集合 Choose CSet
- 引用处理 Ref Proc
- 卡片重新脏化 Redirty Cards
- 回收空闲巨型分区 Humongous Reclaim
- 释放分区 Free CSet
- 其他活动 Other
- 混合收集周期 Mixed Collection Cycle
-
参考文章 ;下面两幅图都是大概描述了 G1 收集器的活动过程
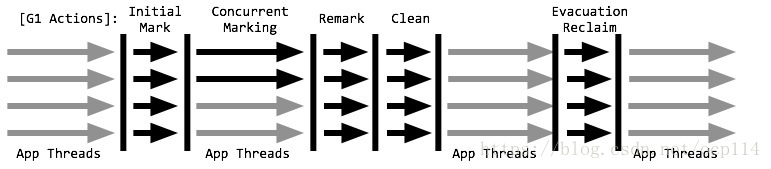
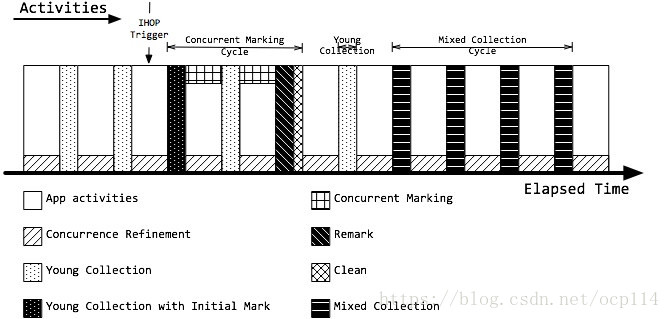
其他说明
- 上面每一个分点中的 GC 参数并非只能用于对应的收集器,有些参数或许能通用,但添加后或许会对收集器的某些特性失去
- Java 1.8 后,永久代(Permgem 区)改名为元数据区,目的是为了和 JRockit 合并
思考
既然垃圾收集越来越复杂,其复杂性都是围绕垃圾的 搜索 — 识别 — 清除 — 内存回收,那么有么有其他方式来帮助这些?我想到的就是在代码层面的操作的,例如
- 垃圾的识别:在不考虑老代码兼容的情况下,JVM 规范中可以加几条,让能运行在 JVM 上面的语言在创建对象的是否都有一个标记,当对象的变成垃圾时,该标记也会出发改变,那么对于垃圾的判定识别就方便很多,直接来个并行清除和内存回收就行,如果要兼容老代码,就需要做另外的判定了
- 空间的回收:在清除垃圾时,数据在内存区域的移动是不可避免的,能不能先复制后清除?也就是把非垃圾数据先进行复制操作,和原来的复制算法一样,区别在于,复制的时候系统线程同样可以运行,复制完成后,给两个数据都加把锁,然后更新对象的引用地址,更新完引用地址后解开锁,清除原来的数据
以上只是个人异想天开的愚见,高手们请多多指教,欢迎讨论交流,

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









