



Overview
- 进制
- 单位
- ASCII
- Unicode
- UTF-8
Description
1)进制
满N进1
| 二进制 | 八进制 | 十进制 | 十六进制 |
|---|---|---|---|
| 0 | 0 | 0 | 1 |
| 1 | 1 | 1 | 2 |
| 10 | 2 | 2 | 3 |
| 11 | 3 | 3 | 4 |
| 100 | 4 | 4 | 5 |
| 101 | 5 | 5 | 6 |
| 110 | 6 | 6 | 7 |
| 111 | 7 | 7 | 8 |
| 1000 | 10 | 8 | 9 |
| 1001 | 11 | 9 | a |
| 1010 | 12 | 10 | b |
| 1011 | 13 | 11 | c |
| 1100 | 14 | 12 | d |
| 1101 | 15 | 13 | e |
| 1110 | 16 | 14 | f |
| 1111 | 17 | 15 | 10 |
| 10000 | 20 | 16 | 11 |
| 10001 | 21 | 17 | 12 |
| ... | ... | ... | ... |
2)单位
计算机中底层处理的是二进制11011011 00110101类似的组合
位(b),一个二进制的位置
字节(byte):8位为一个字节
千字节(KB):1024个字节 = 1024 * 8 位
兆字节(MB):1024个千字节 = 1024 * 1024 字节 = 1024 * 1024 * 8
...
3) ASCII
| DEC | OCT | HEX | BIN | 缩写/符号 | HTML实体 | 描述 |
|---|---|---|---|---|---|---|
| 0 | 000 | 00 | 00000000 | NUL | � | Null char (空字符) |
| 1 | 001 | 01 | 00000001 | SOH |  | Start of Heading (标题开始) |
| 2 | 002 | 02 | 00000010 | STX |  | Start of Text (正文开始) |
| 3 | 003 | 03 | 00000011 | ETX |  | End of Text (正文结束) |
| ... | ... | ... | ... | ... | ... | ... |
| 126 | 176 | 7E | 01111110 | ~ | ~ | Equivalency sign (tilde) |
| 127 | 177 | 7F | 01111111 |  | Delete |
ASCII是早期计算机兴起的时候生产的一个编码表(American Standard Code for Information Interchange),是用于电子通信的7位编码系统,一共0-127个字节,虽然可以表示为8位,但是ASCII字符集只使用了7位来表示128个字符,因此最高位是01111111。
但早期的这个ASCII对应关系表并不足与满足当前社会所需的所有内容,比如汉字就无法表示,因此衍生了Unicode
4)Unicode
Unicode是万国码,基本上覆盖了全球所用的所有字符
Unicode有两种表示规则
- UCS2: 是早期的一个表示规则,用16位来表示所有的字符,8位一个字节,也就是2个字节表示所有的字符,共2*16=65535个字节,但也不足以满足当今社会所有的情况,于是衍生除了UCS4
- UCS4: 用32位来表示所有的字符,8位一个字节,也就是4个字节表示所有的字符,共2*32=4294967296个字符
UCS2可以兼容ASCII,UCS4可以兼容UCS2和ASCII
ASCII 是0-127个字节:
| ASCII |
| 00000000 |
| … |
| 01111111 |
Unicode的UCS2来表示ASCII是
| UCS2 | |
| 00000000 00000000 | 兼容ASCII的0-127个字节 |
| … | |
| 00000000 01111111 | |
| … | 表示其他字符 |
| 11111111 11111111 | |
Unicode的UCS4来表示ASCII和UCS2是
| UCS4 | |
| 00000000 00000000 00000000 00000000 |
兼容ASCII的0-127个字节 也意味着兼容UCS2的一部分字节 |
| … | |
| 00000000 00000000 00000000 01111111 | |
| … | 兼容UCS2剩余的字节 |
| 00000000 00000000 11111111 11111111 | |
| … | 表示其他字符 |
| 11111111 11111111 11111111 11111111 | |
虽然Unicode的UCS4覆盖面更广,但如果我所使用的字符在ASCII码中就可以找到,比如00000001,那么我使用ASCII就只使用1个字节,而Unicode的UCS2就需要用到2个字节,00000000 00000001,用UCS4就需要用到4个字节,00000000 00000000 00000000 00000001,所以在性能和存储上来说,此刻我肯定是直接使用ASCII来表示更好,那么我如何在使用的时候是找ASCII还是UCS2或者UCS4呢,那么如何解决这种问题避免浪费计算机资源呢?于是就衍生了UTF-8
5)码点
先了解概念:
在Unicode字符集中是通过码点找到对应字符的
在Unicode字符集中,码点是十六进制存在的
在Golang中,如果获取码点,则获取的默认是十进制显示的
我们有了码点,就可以通过UTF-8编码找到对应的码位范围,然后通过转换模板进行转换找到对应的字符,所以说UTF-8是可变长度的字符编码方式
以下介绍UTF-8
6)UTF-8
UTF-8编码是用于将Unicode字符集的码点编码为字节序列,以便在计算机中存储和传输
| 模板序号 | 码位范围(十六进制) | 转换模板 | 范围 | ||||
| 1 | 0000 - 007F | 0xxxxxxx | runes 0-127 | (ASCII) | |||
| 2 | 0080 - 07FF | 110xxxxx 10xxxxxx | 128-2047 | (values <128 unused) | |||
| 3 | 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 2048-65535 | (values <2048 unused) | |||
| 4 | 10000 - 10FFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 65536-0x10ffff | (other values unused) | |||
规律
0-127字节的二进制是以0开头
128-2047字节的二进制是110开头
2048-65536字节的二进制是1110开头
65535以上字节的二进制是1110开头
模板查找:
1)“A",使用rune获取"A"的十六进制码点,是41,在码位范围0000 - 007F,是第一个模板,那么转换模板就是0xxxxxxx
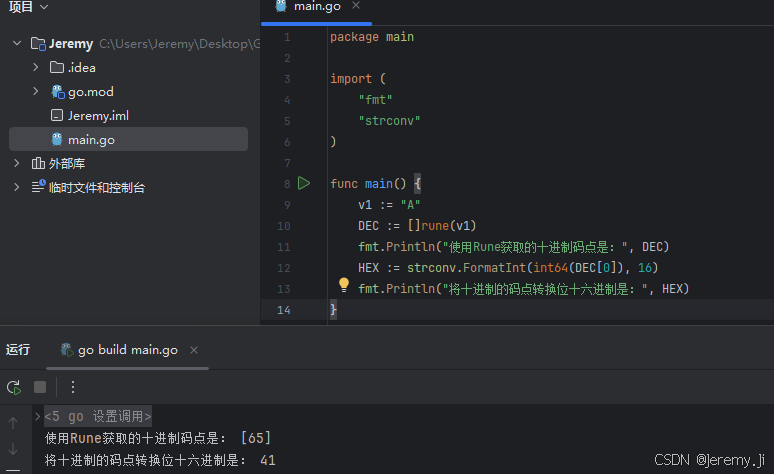
package main
import (
"fmt"
"strconv"
)
func main() {
v1 := "A"
DEC := []rune(v1)
fmt.Println("使用Rune获取的十进制码点是:", DEC)
HEX := strconv.FormatInt(int64(DEC[0]), 16)
fmt.Println("将十进制的码点转换位十六进制是:", HEX)
}
2)“ǣ”,使用rune获取“ǣ”的十六进制码点,是1e3,在码位范围0080 - 07FF,是第二个模板,那么转换模板就是110xxxxx 10xxxxxx
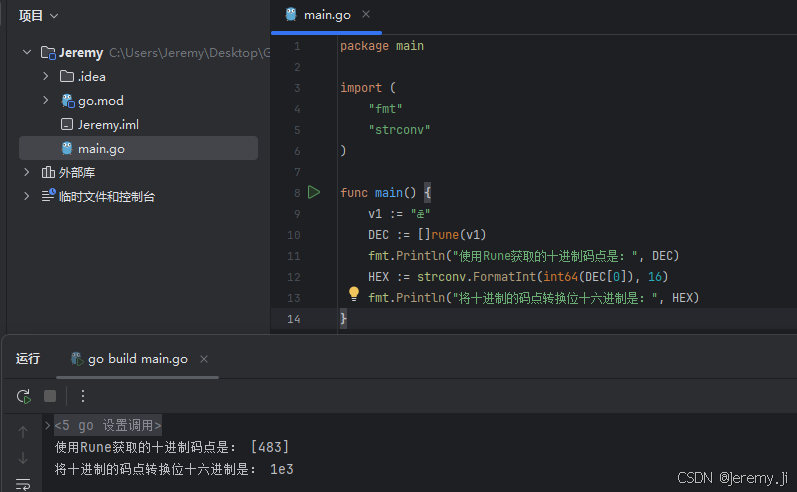
package main
import (
"fmt"
"strconv"
)
func main() {
v1 := "ǣ"
DEC := []rune(v1)
fmt.Println("使用Rune获取的十进制码点是:", DEC)
HEX := strconv.FormatInt(int64(DEC[0]), 16)
fmt.Println("将十进制的码点转换位十六进制是:", HEX)
}
3)“国”,使用rune获取"国"的十六进制码点,是56fd,在码位范围0800 - FFFF,是第三个模板,那么转换模板就是1110xxxx 10xxxxxx 10xxxxxx
package main
import (
"fmt"
"strconv"
)
func main() {
v1 := "国"
DEC := []rune(v1)
fmt.Println("使用Rune获取的十进制码点是:", DEC)
HEX := strconv.FormatInt(int64(DEC[0]), 16)
fmt.Println("将十进制的码点转换位十六进制是:", HEX)
}
对”国“进行编码解释:
编码填充:
进行UTF-8编码填充,“国”的十六进制是56fd,将56fd对应的二进制输出:
| 十六进制 | 5 | 6 | f | d |
| 二进制 | 101 | 110 | 1111 | 1101 |
也就是0101 0110 1111 1101
填充模板1110xxxx 10xxxxxx 10xxxxxx
所以UTF-8编码点位就是11100101 10011011 10111101
代码验证:
将码点转换位十进制的字节后,使用byte来查看是否最终是”国“
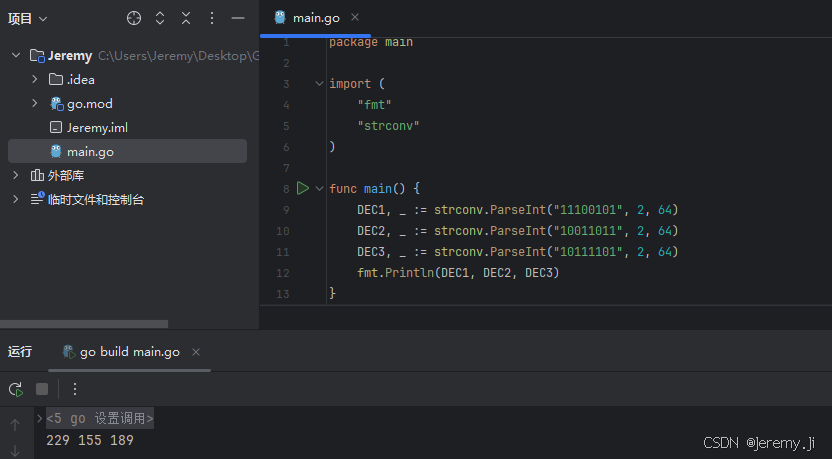
package main
import (
"fmt"
"strconv"
)
func main() {
DEC1, _ := strconv.ParseInt("11100101", 2, 64)
DEC2, _ := strconv.ParseInt("10011011", 2, 64)
DEC3, _ := strconv.ParseInt("10111101", 2, 64)
fmt.Println(DEC1, DEC2, DEC3)
}
可以看到将UTF-8编码的二进制码点转换为十进制后是229 155 189,使用byte来将十进制的字节转换为字符:
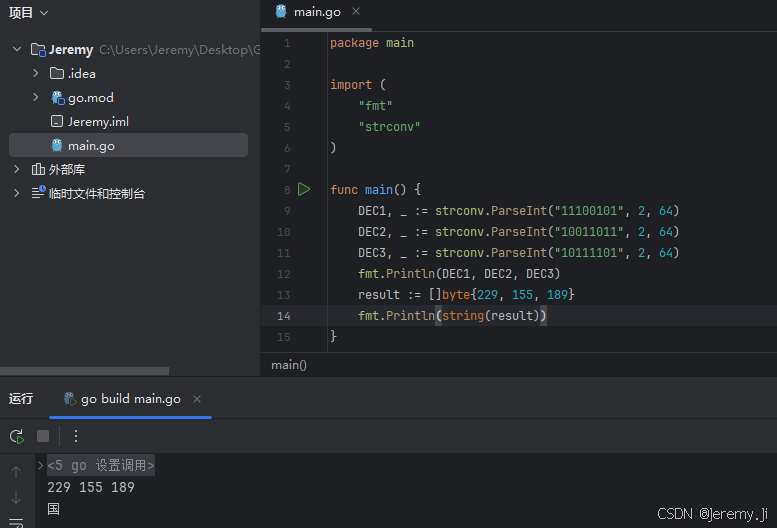
package main
import (
"fmt"
"strconv"
)
func main() {
DEC1, _ := strconv.ParseInt("11100101", 2, 64)
DEC2, _ := strconv.ParseInt("10011011", 2, 64)
DEC3, _ := strconv.ParseInt("10111101", 2, 64)
fmt.Println(DEC1, DEC2, DEC3)
result := []byte{229, 155, 189}
fmt.Println(string(result))
}
可以看到结果是”国“

















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









