




目录
在企业数字化转型的浪潮中,数据成为了企业发展的核心驱动力。而ETL(Extract, Transform, Load)作为数据处理的关键环节,对于企业挖掘数据价值起着至关重要的作用。Kettle作为一款知名的开源ETL工具,被广泛应用于各种数据处理场景。接下来,咱们就用三分钟时间全方位了解一下Kettle的性能。
一、数据抽取性能
1. 数据源连接能力
Kettle具有强大的数据源连接能力,这是其在数据抽取环节的重要基础。它可以连接多种类型的数据源,包括常见的关系型数据库,如MySQL、Oracle、SQL Server等。不管是小型企业使用的MySQL数据库,还是大型企业采用的Oracle数据库,Kettle都能轻松连接。而且,它还支持非关系型数据库,像MongoDB、Redis等。对于那些以文档形式存储数据的MongoDB数据库,Kettle也能顺利获取其中的数据。此外,Kettle还能连接文件系统,如CSV文件、Excel文件等,以及各种云存储服务。这就好比一个万能的数据接口,能让企业内分散在各处的数据都汇聚到Kettle中进行处理。
在连接数据源时,Kettle的配置相对简单。用户只需在界面上填写相应的连接信息,如数据库的地址、用户名、密码等,就能完成数据源的连接。而且,它还支持批量配置数据源,提高了工作效率。
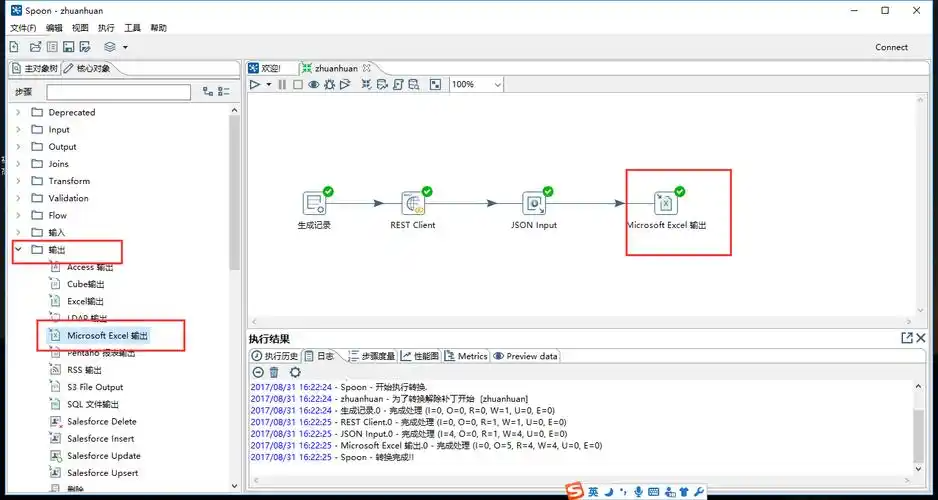
2. 数据抽取速度
Kettle的数据抽取速度在处理小规模数据时表现出色。它采用了多线程技术,能够同时从多个数据源抽取数据,大大提高了抽取效率。例如,在处理一个包含多个表的数据库时,Kettle可以同时对多个表进行数据抽取,减少了抽取时间。
然而,当面对大规模数据抽取时,Kettle的性能可能会受到一定影响。这是因为它主要基于单机或小规模集群进行数据处理,对于超大规模的数据,可能会出现抽取速度变慢的情况。在这一方面,国产工具FineDataLink具有很大的优势,它提供时间戳、触发器、全表同比、全表比对增量装载、日志解析等五大数据同步方式,可满足各种情况下的数据抽取和同步需求,如基于时间戳和主键的增量抽取,能定期查询源系统中更新或新增的数据并同步到目标系统。
在这个过程中,我经常使用实时数据集成工具FineDataLink,它能快速连接关系型数据库、非关系型数据库、接口、文件等 7 大类数据源,自动识别不同类型的数据源,将其接入平台,进行统一管理,方便后续的处理与分析。FineDataLink的使用地址我放在这里了,感兴趣的可以前去体验
3. 数据抽取稳定性
在数据抽取过程中,Kettle具有较好的稳定性。它能够处理各种异常情况,如网络中断、数据源故障等。当遇到网络中断时,Kettle会自动进行重试,确保数据抽取的完整性。而且,它还支持断点续传功能,当数据抽取过程中出现中断时,再次启动抽取任务时可以从断点处继续抽取,避免了数据的重复抽取和丢失。
二、数据转换性能
1. 数据转换功能丰富度
Kettle提供了丰富的数据转换功能,能够满足各种复杂的数据处理需求。它可以对数据进行清洗,去除重复数据、无效数据和错误数据。例如,在处理客户信息数据时,可能存在重复的客户记录,Kettle可以快速识别并删除这些重复记录,保证数据的准确性。
它还支持数据的格式转换,如将日期格式从“YYYY-MM-DD”转换为“DD/MM/YYYY”,或者将数字格式进行转换。在数据计算方面,Kettle可以进行各种数学运算,如求和、求平均值、计数等。而且,它还能进行复杂的逻辑判断和条件处理,根据不同的业务规则对数据进行筛选和转换。
2. 数据转换效率
Kettle的数据转换效率在处理简单数据转换任务时较高。它的转换组件经过了优化,能够快速完成数据的转换操作。例如,对于简单的数据清洗和格式转换任务,Kettle可以在短时间内完成。
但是,当遇到复杂的数据转换逻辑时,Kettle的效率可能会有所下降。因为复杂的转换逻辑需要更多的计算资源和时间来处理。不过,通过合理的设计转换流程和优化组件配置,可以提高数据转换的效率。例如,将复杂的转换任务分解为多个简单的子任务,依次进行处理。
3. 数据转换灵活性
Kettle具有很高的数据转换灵活性。它允许用户自定义转换规则和逻辑,根据不同的业务需求进行个性化的数据转换。用户可以通过编写脚本或者使用内置的函数来实现自定义的转换功能。例如,在处理特定行业的数据时,可能需要根据行业规则进行特殊的数据转换,Kettle可以满足这种个性化需求。
而且,Kettle的转换组件可以灵活组合和配置。用户可以根据数据处理的流程,将不同的转换组件连接起来,形成一个完整的转换流程。这就好比搭积木一样,用户可以根据自己的想法搭建出不同的转换模型。
三、数据加载性能
1. 目标数据源支持度
Kettle支持多种目标数据源,包括各种关系型数据库和非关系型数据库。它可以将处理后的数据加载到MySQL、Oracle、SQL Server等关系型数据库中,也可以加载到MongoDB、Redis等非关系型数据库中。此外,它还支持将数据加载到文件系统和云存储中,如CSV文件、Excel文件、HDFS等。
在加载数据到不同的目标数据源时,Kettle会根据数据源的特点进行优化。例如,在加载数据到关系型数据库时,它会采用批量插入的方式,提高数据加载的速度。
2. 数据加载速度
Kettle的数据加载速度在处理小规模数据时表现良好。它可以快速将处理后的数据加载到目标数据源中。但是,在处理大规模数据时,数据加载速度可能会受到一定影响。这是因为大规模数据的加载需要更多的资源和时间来完成。不过,通过调整加载参数和优化目标数据源的配置,可以提高数据加载的速度。例如,增加数据库的并发插入线程数,提高数据加载的效率。
3. 数据加载稳定性
Kettle在数据加载过程中具有较好的稳定性。它能够处理各种异常情况,如目标数据源故障、数据冲突等。当遇到目标数据源故障时,Kettle会自动进行重试,确保数据的加载成功。而且,它还支持数据的回滚操作,当数据加载过程中出现错误时,可以将已经加载的数据回滚到加载前的状态,保证数据的一致性。
四、系统资源占用情况
1. 内存占用
Kettle在运行过程中会占用一定的内存资源。尤其是在处理大规模数据时,内存占用会相对较高。因为Kettle需要将数据加载到内存中进行处理,大规模数据会导致内存使用量增加。不过,通过合理的配置和优化,如调整JVM的内存参数,可以降低Kettle的内存占用。
2. CPU占用
Kettle的CPU占用情况与数据处理的复杂度和规模有关。在处理简单的数据处理任务时,CPU占用相对较低。但在处理复杂的转换逻辑和大规模数据时,CPU占用会明显增加。企业可以通过优化转换流程和使用高性能的服务器来降低CPU的压力。
五、Q&A
Q:Kettle处理大规模数据时性能不佳怎么办?
A:可以通过合理配置和优化来提高性能。比如调整线程数量、优化数据库查询语句、将复杂任务分解为简单子任务、调整加载参数、优化目标数据源配置、调整JVM内存参数等。同时,FineDataLink作为企业级数据处理工具,完美解决大规模数据实时性问题。
Q:Kettle在数据处理过程中出现错误怎么办?
A:Kettle具有一定的容错和恢复机制。遇到错误时,它会自动进行重试。如果出现数据加载错误,还支持数据回滚操作,保证数据的一致性。
Q:Kettle的系统资源占用可以降低吗?
A:可以。通过调整JVM的内存参数可以降低内存占用,优化转换流程和使用高性能服务器可以降低CPU压力。
Kettle在数据抽取、转换和加载方面都有不错的表现。它具有强大的数据源连接能力、丰富的数据转换功能和广泛的目标数据源支持度。在处理小规模数据时,性能表现良好,能够快速、稳定地完成数据处理任务。但在处理大规模数据和复杂转换逻辑时,性能可能会受到一定影响。同时,Kettle在运行过程中会占用一定的系统资源。企业在使用Kettle时,需要根据自身的数据特点和业务需求,合理配置和优化,以充分发挥Kettle的性能优势,为企业的数据处理和分析提供有力支持。

















 9838
9838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









