from builtins import range
import numpy as np
from random import shuffle
from past.builtins import xrange
def softmax_loss_naive(W, X, y, reg):
"""
Softmax loss function, naive implementation (with loops)
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability. Don't forget the #
# regularization! #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
num_classes = W.shape[1]
for i in xrange(num_train):
scores = X[i].dot(W) # X的第i行,也就是第i个图像点乘参数矩阵,得到的矩阵维度为(1,C)
scores -= max(scores) # 减去最大值防止计算时数值错误
loss += -np.log(np.exp(scores[y[i]]) / np.sum(np.exp(scores))) # 跟下面的公式是一样的,下面的使用了对数化简公式log(a/b)=log(a)-log(b)
# loss += -score[y[i]] + np.log(np.sum(np.exp(scores)))
# 对W的更新要放在i的循环中,每轮都要对所有W进行更新,也即每求出一个X的预测矩阵后都要反向更新W
for j in range(num_classes):
if j == y[i]:
dW[:, j] += (np.exp(scores[j]) / np.sum(np.exp(scores))) * X[i] - X[i] # 代入公式,图中有详细推导
else:
dW[:, j] += (np.exp(scores[j]) / np.sum(np.exp(scores))) * X[i]
loss /= num_train
loss += 0.5 * reg * np.sum(W*W)
dW /= num_train
dW += reg * W
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
def softmax_loss_vectorized(W, X, y, reg):
"""
Softmax loss function, vectorized version.
Inputs and outputs are the same as softmax_loss_naive.
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using no explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability. Don't forget the #
# regularization! #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
# scores是N*C矩阵,N对应N个实例,C代表每一项的得分
scores = X.dot(W)
# 减去最大值防止出现数值错误
scores -= np.max(scores, axis=1, keepdims=True)
# 求概率,用指数矩阵除以每一行的指数行和
prob = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
# loss
loss = -np.sum(np.log(prob[range(num_train), y]))
loss = loss / num_train + 0.5 * reg * np.sum(W * W)
# 根据循环法的公式,先给出一个掩膜矩阵,表示当j=y[i]时,-X[i]那一项
mask_minus_ones = np.zeros_like(scores)
mask_minus_ones[range(num_train), y] = -1
# 另外一个矩阵,用来乘以概率,表示循环法中两种情况下的prob*X[i]
mask_ones = np.ones_like(scores)
# 两个矩阵相加得到最终的更新矩阵,该更新方法与SVM类似
update = mask_ones * prob + mask_minus_ones
dW += np.dot(X.T, update) / num_train + reg * W
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
2. softmax.ipynb
# Use the validation set to tune hyperparameters (regularization strength and
# learning rate). You should experiment with different ranges for the learning
# rates and regularization strengths; if you are careful you should be able to
# get a classification accuracy of over 0.35 on the validation set.
from cs231n.classifiers import Softmax
results = {}
best_val = -1
best_softmax = None
learning_rates = [1e-7, 5e-7]
regularization_strengths = [2.5e4, 5e4]
################################################################################
# TODO: #
# Use the validation set to set the learning rate and regularization strength. #
# This should be identical to the validation that you did for the SVM; save #
# the best trained softmax classifer in best_softmax. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for learning_rate in learning_rates:
for regularization_strength in regularization_strengths:
softmax = Softmax()
softmax.train(X_train, y_train, learning_rate, regularization_strength, num_iters = 500)
acc_train = np.mean(y_train == softmax.predict(X_train))
acc_val = np.mean(y_val == softmax.predict(X_val))
results[(learning_rate,regularization_strength)] = (acc_train,acc_val)
if acc_val > best_val :
best_val = acc_val
best_softmax = softmax
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)





 本文深入解析Softmax和SVM损失函数的梯度推导过程,对比两者在求导和向量化实现上的异同,特别强调在循环法中对特殊情况的处理,以及如何通过向量化提高计算效率。
本文深入解析Softmax和SVM损失函数的梯度推导过程,对比两者在求导和向量化实现上的异同,特别强调在循环法中对特殊情况的处理,以及如何通过向量化提高计算效率。
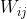 的前世今生,来展现整个softmax梯度的推导过程,其中字母有些混乱,i/j傻傻分不清楚,有多个地方都用到j,但代表的含义不尽相同:
的前世今生,来展现整个softmax梯度的推导过程,其中字母有些混乱,i/j傻傻分不清楚,有多个地方都用到j,但代表的含义不尽相同:

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









