




字符串匹配之KMP算法
对于字符串匹配算法中,前面介绍的算法在字符串匹配中都会有重复比较的情况,那么对于已经比较过的子串,我们是否可以用某种方法把它保存起来,等到下次要比较的时候直接跳过已经比较过的字符串呢?
下面介绍一种由
Knuth、Morris
K
n
u
t
h
、
M
o
r
r
i
s
和
Pratt
P
r
a
t
t
三个大佬设计的字符串匹配算法:
例如找出模式串
P=ababaca
P
=
a
b
a
b
a
c
a
在文本串
T=bacbababaabcbab
T
=
b
a
c
b
a
b
a
b
a
a
b
c
b
a
b
的位置,用
m
m
和分别表示
P
P
和的长度,
S
S
表示当字符串匹配时的有效偏移。
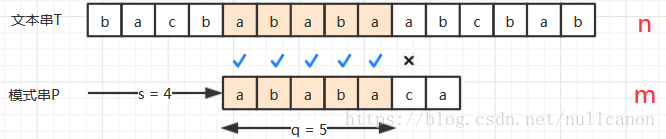
在这个例子中,个字符已经匹配成功,但模式
P
P
的第个字符匹配失败,然而
q
q
个字符已经匹配成功给了我们有用的信息,来看已经匹配成功的个字符
ababa
a
b
a
b
a
,如果我们下次
S
S
向前偏移一格,肯定是匹配失败的,再看的前三个字符和后三个字符都是
aba
a
b
a
,那前三个字符和后三个字符必然匹配,因此
S
S
一次可以直接偏移到后三个字符的位置,并且直接从阴影部分后面开始比较,这样会省去好多无用功。
![[图片KMP_2]](https://i-blog.csdnimg.cn/blog_migrate/e5b28702ba0ee0d6493830324668f3d1.png)
我们把叫做
ababa
a
b
a
b
a
的公共前后缀,
k
k
表示公共前后缀的长度。
从上面信息中可以得出,下一次跳转的位置为已匹配字符串的公共前后缀的长度存在某种确定关系。
下面列出模式串
P
P
的所有前缀的公共前后缀
![[图片KMP_3]](https://i-blog.csdnimg.cn/blog_migrate/686b3c5ff5907354ee3daaf9fef9c07f.png)
为了方便后面程序的计算,下面把模式串的所有前缀串的公共前后缀的情况映射为一个表格:
![[图片KMP_4]](https://i-blog.csdnimg.cn/blog_migrate/dc62dcf824c73f3fffc7bcfc70b9b2f2.png)
利用映射表,对和
T
T
做一下匹配:
![[图片KMP_5]](https://i-blog.csdnimg.cn/blog_migrate/83e91da5b2b659264ea7102002772913.png)
从上面可以看出,在最坏的情况下,遍历一遍和遍历一遍T就可以了,时间复杂度为
O(n+m)
O
(
n
+
m
)
。
来看一下如何构建公共前后缀表:
对于一个字符串,如果字符串有一个公共前后缀,比如说
ABA
A
B
A
,它的下一个公共前后缀长度如果是
2
2
的话,那么下一个字符必须为,即
ABAB
A
B
A
B
![[图片KMP_6]](https://i-blog.csdnimg.cn/blog_migrate/4abd0d4f7bd61b64384a9a46e3b039c5.png)
用
i
i
表示第二个的位置,用
len
l
e
n
表示所比较到的最长的长度(即第一个
B
B
的位置,这个的值是前后缀表
π[i]
π
[
i
]
),当
P[i]==P[len]
P
[
i
]
==
P
[
l
e
n
]
的时候,
len++
l
e
n
+
+
;然后把
len
l
e
n
赋给相应的前缀表的位置。
那么如果
ABA
A
B
A
的下一个字符不是
B
B
呢,比如说这样的字符串
![[图片KMP_7]](https://i-blog.csdnimg.cn/blog_migrate/1e80c280062320b0068d12ae38d6e09e.png)
我们采取这样的办法:把
len
l
e
n
取值的地方移动到前一个位置,即
len=prefix[len−1]
l
e
n
=
p
r
e
f
i
x
[
l
e
n
−
1
]
;
代码:
void PrefixTable(const char* P, int prefix[], int n)//n为前缀表的长度
{
prefix[0] = 0;
int len = 0;
int i = 1;
while (i < n)
{
if (P[len] == P[i])
{
len++;
prefix[i] = len;
i++;
}
else
{
//不相等的情况 例如ABA+A的情况
//len-1所对应的值就是新的len的取值
if (len > 0)
len = prefix[len - 1];
else
{
prefix[i] = len;
i++;
}
}
}
}
void MovePrefixTable(int prefix[], int n)
{
for (int i = n - 1; i > 0; i--)
prefix[i] = prefix[i - 1];
prefix[0] = -1;
}
void KMPSearch(const char* T, const char* P)
{
int n = strlen(T);
int m = strlen(P);
int* prefix = new int[n];
PrefixTable(P,prefix,n);
MovePrefixTable(prefix,n);
int q = 0;//q控制着P,i控制着T
for (int i = 0; i < n;)
{
if (q == m - 1 && P[q] == T[i])
{
printf("%d\n", i - q);
q = prefix[q];//匹配到了继续向后迭代
}
if (P[q] == T[i]) i++, q++;
else
{
q = prefix[q];
if (q == -1) i++, q++;
}
}
}参考:
1.《算法导论》
2.https://www.bilibili.com/video/av16828557?from=search&seid=6207513803182272645


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









