




 本文介绍了如何使用Python操作InfluxDB数据库获取数据。InfluxDB是一个开源的时序数据库,专注于时间序列数据的存储。文章详细讲解了InfluxDB的基本原理,如tag、field和timestamp,并提供了环境准备、数据表结构和数据插入的说明。文中还展示了Python代码封装示例,用于查询磁盘使用率等系统监控数据,并讨论了是否需要像MySQL、Oracle那样关闭连接的问题。
本文介绍了如何使用Python操作InfluxDB数据库获取数据。InfluxDB是一个开源的时序数据库,专注于时间序列数据的存储。文章详细讲解了InfluxDB的基本原理,如tag、field和timestamp,并提供了环境准备、数据表结构和数据插入的说明。文中还展示了Python代码封装示例,用于查询磁盘使用率等系统监控数据,并讨论了是否需要像MySQL、Oracle那样关闭连接的问题。
前言
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。特色功能包括
1、基于时间序列,支持与时间有关的相关函数
2、可度量性:你可以实时对大量数据进行计算
3、基于事件:它支持任意的事件数据
原理
1)tag–标签,在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引,是“key-value”的形式。
2)field–数据,field主要是用来存放数据的部分,也是“key-value”的形式。
3)timestamp–时间戳,作为时序型数据库,时间戳是InfluxDB中最重要的部分,在插入数据时可以自己指定也可留空让系统指定。
说明:在插入新数据时,tag、field和timestamp之间用空格分隔。
4)series–序列,所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线。
5)Retention policy–数据保留策略,可以定义数据保留的时长,每个数据库可以有多个数据保留策略,但只能有一个默认策略。。
6)Point–点,表示每个表里某个时刻的某个条件下的一个field的数据,因为体现在图表上就是一个点,于是将其称为point。
环境准备
安装influxdb数据库就不细说。直接说python和influxdb的交互。
pip install influxdb==5.2.0
influxdb数据库表
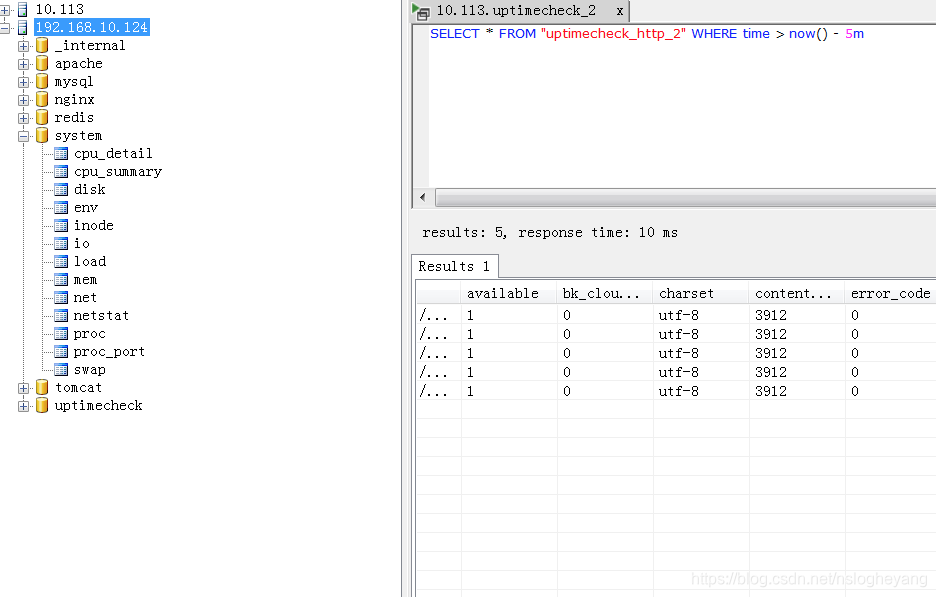
上代码
操作influxdb数据库代码进行封装如下:
from influxdb import InfluxDBClient
import pytz
import time
import dateutil.parser
import datetime
class DBApi(object):
"""
通过infludb获取数据
"""
def __init__(self, ip, port):
"""
初始化数据
:param ip:influxdb地址
:param port: 端口
"""
self.db_name = 'system'
self.use_cpu_table = 'cpu_summary' # cpu使用率表
self.phy_mem_table = 'mem'# 物理内存表
self.traffic_table = 'net'# 接收流量表
self.disk_table = 'disk'# 磁盘表
self.swap_table = 'swap' # 交换分区表
self.client = InfluxDBClient(ip, port, '', '', self.db_name) # 连接influxdb数据库
说明
influxdb.InfluxDBClient(host=u'localhost', port=8086, username=u'root', password=u'root', database=None, ssl=False, verify_ssl=False, timeout=None, retries=3, use_udp=False, udp_port=4444, proxies=None)
参数
host (str) – 用于连接的InfluxDB主机名称,默认‘localhost’
port (int) – 用于连接的Influxport端口,默认8086
username (str) – 用于连接的用户名,默认‘root’
password (str) – 用户密码,默认‘root’
database (str) – 需要连接的数据库,默认None
ssl (bool) – 使用https连接,默认False
verify_ssl (bool) – 验证https请求的SSL证书,默认False
timeout (int) – 连接超时时间(单位:秒),默认None,
retries (int) – 终止前尝试次数(number of retries your client will try before aborting, defaults to 3. 0 indicates try until success)
use_udp (bool) – 使用UDP连接到InfluxDB默认False
udp_port (int) – 使用UDP端口连接,默认4444
proxies (dict) – 为请求使用http(s)代理,默认 {}
示例,获取磁盘使用率,最高值,最低值,平均值。
def get_use_disk(self, ip, s_time, e_time):
"""
获取磁盘io使用率
:param ip: 查询的主机ip
:param s_time: 开始时间
:param e_time: 结束时间
:return:
"""
response = {}
s = time.strptime(s_time, '%Y-%m-%d %H:%M:%S')
e = time.strptime(e_time, '%Y-%m-%d %H:%M:%S')
start_time = int(time.mktime(s)) * 1000 * 1000 * 1000
end_time = int(time.mktime(e)) * 1000 * 1000 * 1000
max_list = min_list = avg_list = ['0.0']
max_list = self.client.query(
"select max(in_use) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
min_list = self.client.query(
"select min(in_use) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
avg_list = self.client.query(
"select MEAN(in_use) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
response["in_use"] = {}
for max, min, avg in zip(max_list, min_list, avg_list):
data_max_value = {}
data_min_value = {}
data_avg_value = {}
data = {}
data_max_value["value"] = round(max[0]["max"], 2)
data_max_value["time"] = self.change_time(max[0]["time"])
data_min_value["value"] = round(min[0]["min"], 2)
data_min_value["time"] = self.change_time(min[0]["time"])
data_avg_value["value"] = round(avg[0]["mean"], 2)
data["value_max"] = data_max_value
data["value_min"] = data_min_value
data["value_avg"] = data_avg_value
response["in_use"] = data
max_list = min_list = avg_list = ['0']
max_list = self.client.query(
"select max(used) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
min_list = self.client.query(
"select min(used) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
avg_list = self.client.query(
"select MEAN(used) from %s where time>=%s and time<=%s and ip='%s';" % (
self.disk_table, start_time, end_time, ip))
response["disk_used_capacity"] = {
'value_avg': {'value': 0},
'value_min': {'value': 0, 'time': '2019-03-14 09:00:33'},
'value_max': {'value': 0, 'time': '2019-03-14 09:50:33'}
}
for max, min, avg in zip(max_list, min_list, avg_list):
data_max_value = {}
data_min_value = {}
data_avg_value = {}
data = {}
data_max_value["value"] = round(max[0]["max"], 2)
data_max_value["time"] = self.change_time(max[0]["time"])
data_min_value["value"] = round(min[0]["min"], 2)
data_min_value["time"] = self.change_time(min[0]["time"])
data_avg_value["value"] = round(avg[0]["mean"], 2)
data["value_max"] = data_max_value
data["value_min"] = data_min_value
data["value_avg"] = data_avg_value
response["disk_used_capacity"] = data
return response
代码中有用到时间转换,时间戳转为正常时间字符串。
def change_time(self, params):
"""
时间转换
:param params:
:return:
"""
item = dateutil.parser.parse(params).astimezone(pytz.timezone('Asia/Shanghai'))
result = str(item).split("+")[0]
response = time.strptime(result, '%Y-%m-%d %H:%M:%S')
param = time.strftime('%Y-%m-%d %H:%M:%S', response)
return param
OK,封装完毕。代码中调试
# 引入省略
# INFLUXDB_IP influxdb所在主机
# INFLUXDB_PROT influxdb端口
db = DBApi(ip=INFLUXDB_IP, port=INFLUXDB_PROT)
ip = '192.168.10.1'
start_time = '2020-01-13 08:00:00'
end_time = '2020-01-15 08:00:00'
response = db.get_use_disk(ip, start_time, end_time)
结果
{
"disk_used_capacity": {
"value_avg": {
"value": 21443136558.22
},
"value_min": {
"value": 139886592,
"time": "2020-01-13 08:00:09"
},
"value_max": {
"value": 44364251136,
"time": "2020-01-15 07:59:09"
}
},
"in_use": {
"value_avg": {
"value": 40.38
},
"value_min": {
"value": 28.22,
"time": "2020-01-13 08:00:09"
},
"value_max": {
"value": 54.52,
"time": "2020-01-15 07:59:09"
}
}
}
结束
cpu、物理内存、接收流量、交换分区等数据查询同上。不再举例。
有点疑问,influxdb数据库连接操作结束后不需要像mysql、oracle一样关闭吗?


















 3267
3267





 到【灌水乐园】发言
到【灌水乐园】发言







