



 本文通过使用Keras和TensorFlow构建卷积神经网络,对手写数字数据集进行识别。介绍了Sklearn和Keras的基本用法,详细展示了模型构建、训练、测试及数据可视化的全过程。
本文通过使用Keras和TensorFlow构建卷积神经网络,对手写数字数据集进行识别。介绍了Sklearn和Keras的基本用法,详细展示了模型构建、训练、测试及数据可视化的全过程。
写在前面
近年来人工智能领域兴起,python作为一种易于学习的语言,担当起了发展该领域的主要角色。此篇博客,目的在于简要介绍keras的用法,并将它用于手写数字数据集(digits)的识别。
Sklearn介绍
关于Sklearn的介绍,我在上一篇博客中已经有所提及,简要来讲,就是应用于机器学习的常用库。
Keras介绍
Keras是一个高级神经网络API,在tensorflow库中,一般调用它来实现卷积神经网络模型的构建,以及训练等方面,初次接触卷积神经网络并打算用Python语言来学习实现,往往地最开始接触的内容就是Keras。
实验流程
导入手写数字数据集(digits)
digits中总共有四种数据:
data:存储各个图片的各个像素,是展开后的一维数组
target:存储每个图片的对应标签
target_names:记录各个标签对应的名字
images:和data数据内容一样,但是类型不同,属于二维数组。
from sklearn import datasets
digits = datasets.load_digits()
data,target,target_names,images = digits.data,digits.target,digits.target_names,digits.images
这样就将各个数据读取出来了。
print(data.shape)#确认数据集数量与大小,输出结果为(1797,64)
train_images,train_labels,test_images,test_labels = images[:1500],target[:1500],images[1500:],target[1500:]
#划分训练集和测试集
构建模型
模型的构建需要用tensorflow中的keras:
from tensorflow import keras
model = keras.Sequential([
keras.layers.Flatten(input_shape(8,8))#这一层是将输入数据扁平化,也就是将输入的图片变成一维数组
keras.layers.Dense(128,activation='relu')#激活函数为relu
keras.layers.Dense(10)#输出层,最后输出结果分为10组
])
但单单构建层数还不够,如果缺少损失函数,那么容易发生过拟合现象。
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
这样,模型就构建完了,接下来可以将测试集放入训练模型。
训练与测试模型
和Sklearn一样,构建完毕的模型使用fit()方法进行训练
model.fit(train_images,train_labels,epochs=10)#epochs表示模型训练的次数,理论上来说,训练次数越多模型越精确,但过多的训练次数会造成性能和时间的浪费
test_loss,test_acc = model.evaluate(test_images,
test_labels,
verbose=2)
print('测试集识别准确度为:' % test_acc)
此时最基础的功能就完成实现了,尽管还看不到训练成果如何。
概率计算与数据可视化
probability_model = keras.Sequential([model,
keras.layers.Softmax()])#利用Softmax函数实现归一化
predictions = probability_model.predict(test_images)
此时就能得到对于各个图片识别的概率判断了。
import matplotlib.pyplot as plt
import numpy as np
def plot_image(j,predictions_array,true_label,img):
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img,cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)#得到概率中的最大值
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f} % ({})".format(target_names[predicted_label],
100*np.max(predictions[j]),
target_names[true_label]),color=color)
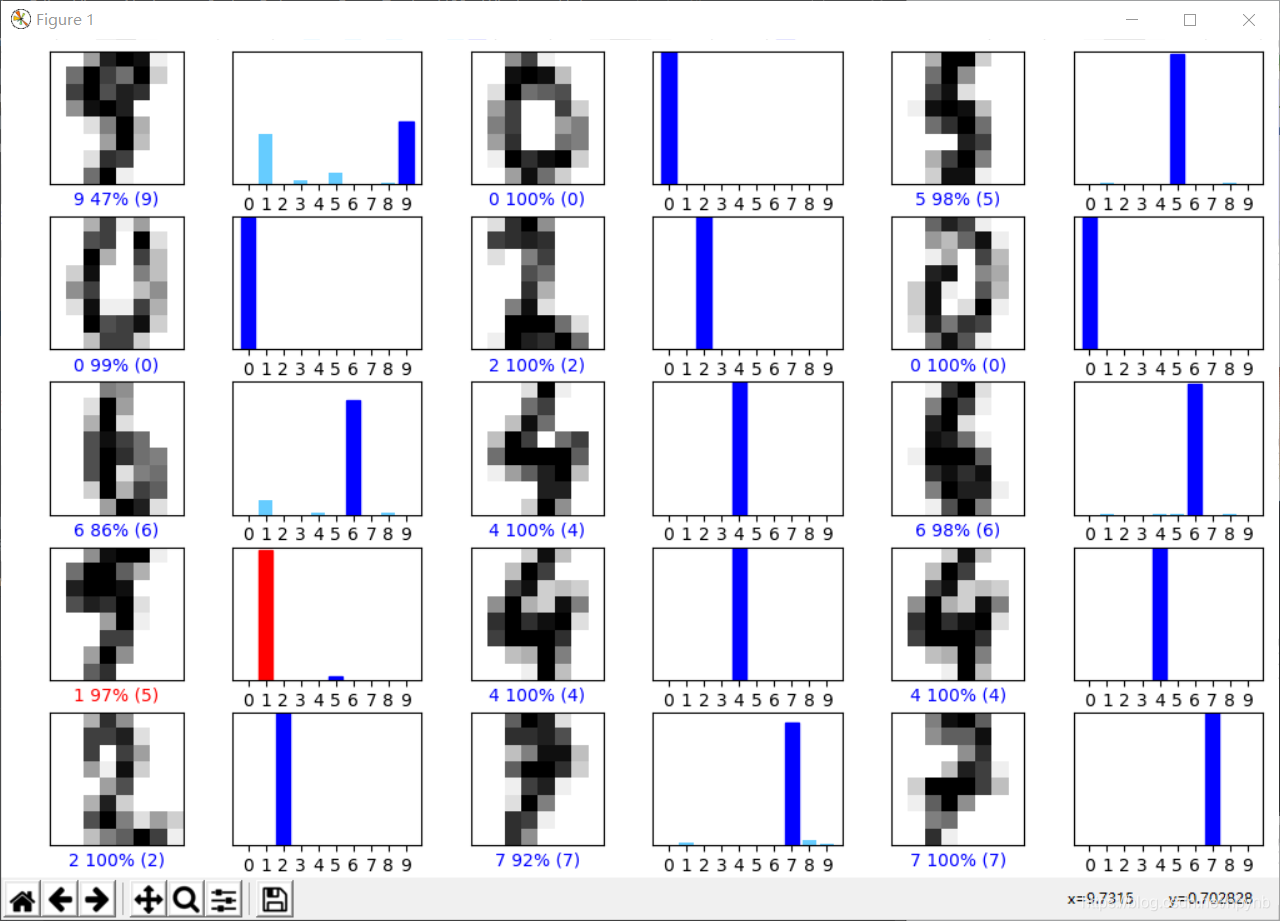
这一段函数可以实现所选择的测试集图片的出现以及概率的显示,并且会将识别错误的用红色字体表示,识别正确的用蓝色字体表示。
但这样显然依旧不够直观,虽然最终结果与概率有了,但依旧不能看到各个数字可能的概率,所以再创建另外一个函数:
def plot_value_array(predictions_array,true_label):
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10),predictions_array,color="#66CCFF")
plt.ylim([0,1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
这段函数可以实现将各个数字的概率以柱状图的形式表现出来
测试
num_row = 5
num_cols = 3
num_images = num_row*num_cols
plt.figure(figsize=(2*2*num_cols,2*num_row))
for i in range(num_images):
j = random.randint(0,len(test_images)+1)
plt.subplot(num_row,2*num_cols,2*i+1)
plot_image(j,predictions[j],test_labels[j],test_images[j])
plt.subplot(num_row,2*num_cols,2*i+2)
plot_value_array(predictions[j],test_labels[j])
plt.tight_layout()
plt.show()
最终生成结果如下:
完整代码
import matplotlib.pyplot as plt
import random
from tensorflow import keras
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
data,target,target_names,images = digits.data,digits.target,digits.target_names,digits.images
#print(data.shape)
#用于确认数据集大小与数量,输出结果为(1797,64)
train_images,train_labels,test_images,test_labels = images[:1500],target[:1500],images[1500:],target[1500:]
#训练集划分1500个数据,剩余数据用于测试
model = keras.Sequential([
keras.layers.Flatten(input_shape=(8,8)),
keras.layers.Dense(128,activation='relu'),
keras.layers.Dense(10)
])
print("------模型创建完毕------")
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_images,train_labels,epochs=10)
print("------模型训练完毕------")
#训练epochs次模型
test_loss,test_acc = model.evaluate(test_images,test_labels,verbose=2)
print("测试集识别准确度为:%s" % test_acc)
#测试
probability_model = keras.Sequential([model,
keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
#predictions存储判断各个数字的概率
def plot_image(j,predictions_array,true_label,img):
#predictions_array,train_labels,img = predictions_array,true_label[i],img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img,cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(target_names[predicted_label],
100*np.max(predictions[j]),
target_names[true_label]),color=color)
def plot_value_array(predictions_array,true_label):
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10),predictions_array,color="#66CCFF")
plt.ylim([0,1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
num_row = 5
num_cols = 3
num_images = num_row*num_cols
plt.figure(figsize=(2*2*num_cols,2*num_row))
for i in range(num_images):
j = random.randint(0,len(test_images)+1)
plt.subplot(num_row,2*num_cols,2*i+1)
plot_image(j,predictions[j],test_labels[j],test_images[j])
plt.subplot(num_row,2*num_cols,2*i+2)
plot_value_array(predictions[j],test_labels[j])
plt.tight_layout()
plt.show()
参考
·https://www.tensorflow.org/tutorials/keras/classification?hl=zh_cn


















 8064
8064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











