




首先导入imdb数据
from keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words = 10000)
num_words=10000意思是只去频率最高的10000个词,这样可以减少工作量,剔除不常用的词。
数据预处理
import numpy as np
def vertorized_sequences(sequences,dimensions = 10000):
result = np.zeros((len(sequences),dimensions))
for i,sequence in enumerate(sequences):
result[i,sequence] = 1.
return result
x_train = vertorized_sequences(train_data)
x_test = vertorized_sequences(test_data)
将数据编为one-hot编码,one-hot编码比较适合用在分类问题中。
keras有内置的直接转换成one-hot编码的方法:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
因为y标签是二分类问题,所以只有0或1两种类别,如果是多分类问题,y标签也需要进行one-hot编码。
添加层
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32,activation = 'relu',input_shape = (10000,)))#input_dim = 10000也可以
model.add(layers.Dense(32,activation = 'relu'))
model.add(layers.Dense(32,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
Sequential是序贯模型,是最基础的模型,是多个网络层的线性堆叠,也就是“一条路走到黑”。
如果应用到多输入多输出的模型或者共享层等,需要使用函数式模型。
这里使用到了4层神经网络,都是使用的Dense层,Dense是全连接层,也就是说该层的每一个神经网络单元都和下一层的每个神经网络单元相连接。
前三层神经网络激活函数都使用relu,激活函数就是将该层的输出经过激活函数转换以后,作为下一层的输入,这样能避免多层网络都是线性模型。
最后一层网络激活函数是sigmoid,是因为要输出的是一个概率值,这个概率值接近0则划分为0类别,接近1则划分为1类别。
model.compile(optimizer = 'rmsprop',loss = 'binary_crossentropy',metrics = ['accuracy'])
模型优化器,optimizer是优化函数,使用rmsprop即可,这是一种梯度下降优化函数,关于keras优化函数以后再详细记录。
loss是损失函数,可以自定义,也可以使用内置函数。
metrics是评判标准,也可以认为是评价指标或者性能评估函数,可以自定义。
模型拟合
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
拟合之前,
将数据切分成两部分,用于选择模型时的验证。
history = model.fit(partial_x_train,partial_y_train,epochs = 20,batch_size = 512,validation_data=(x_val,y_val))
history是一个history对象,包含accuracy,loss以及验证集的accuracy和loss,可以根据这些指标的值选择第二代的次数。
epochs就是迭代的次数,迭代越多次,训练集上的正确率会越高,但是也会过拟合。
batch_size是每一批的数据个数,在这里就是每批512个数据。这个值越小,耗费的计算能力越多,因为权值的更新过于频繁。但是太大,有缺少随机性,容易陷入局部最优。
图像展示
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['acc']
epochs = range(1, len(acc) + 1)
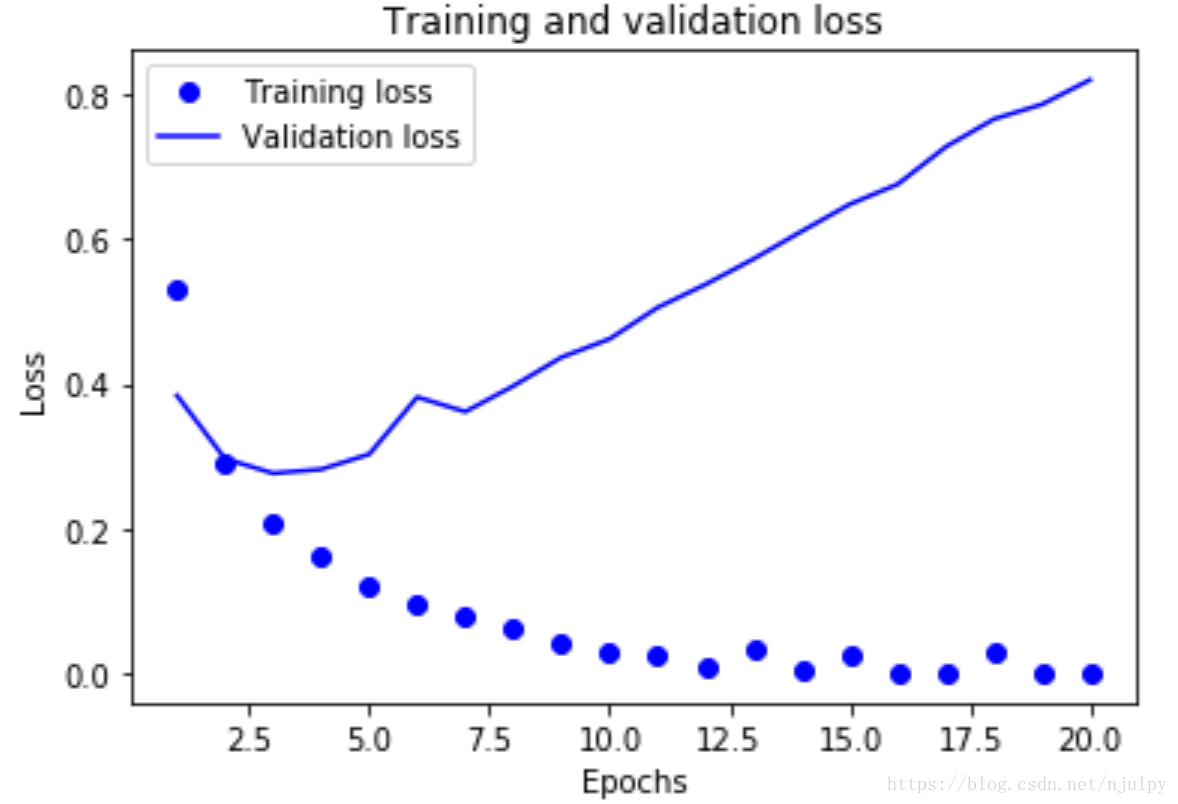
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs,acc,'bo',label = 'Training Acc')
plt.plot(epochs,val_acc,'b',label = 'Validation Acc')
plt.title('Training and Validation Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
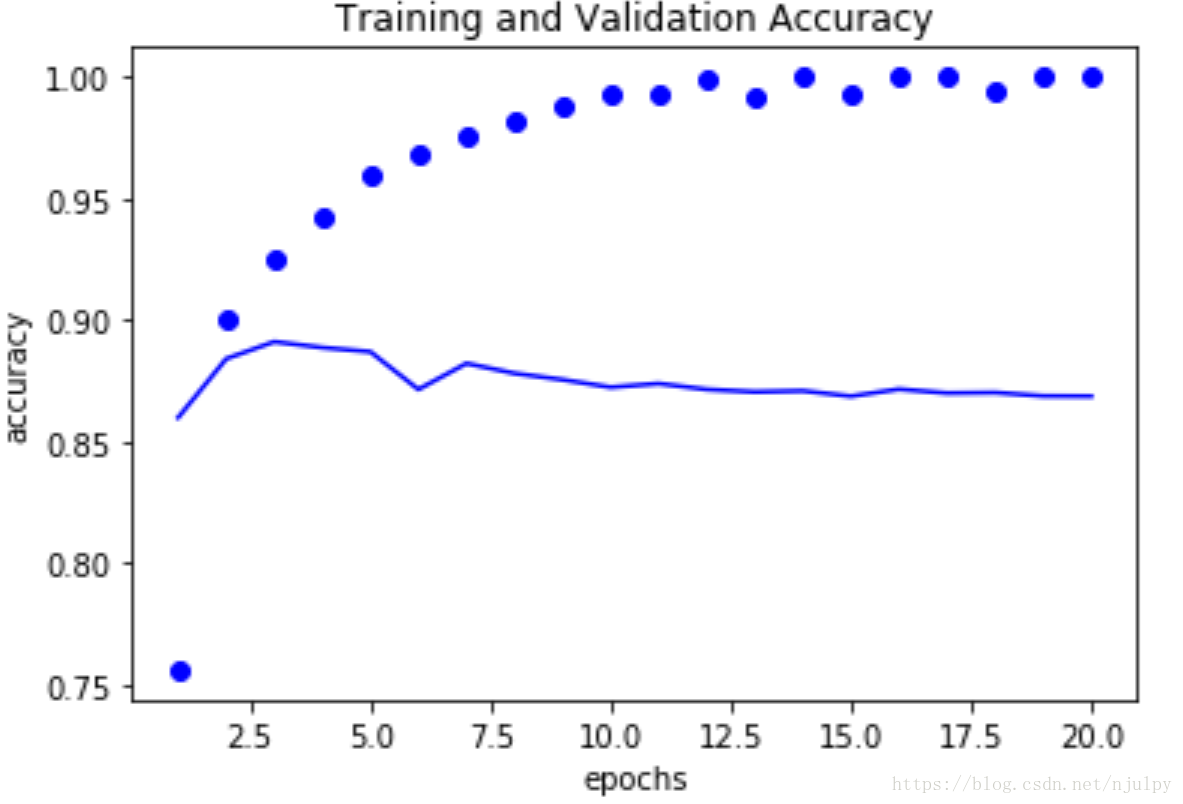
我们可以根据这两张图象选择合适的迭代次数来训练我们最终的模型。
最后,多分类问题与二分类问题类似,区别在于
1.最后一层网络需要使用softmax激活函数,这样才能输出多分类的概率分布。
2.损失函数需要使用categorical_crossentropy或者sparse_categorical_crossentropy,两者的区别在于后者需要时整型数据。
3.注意最后一层的输出单元要超过所分类别,不然结果不准确。

















 8203
8203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









