




 本文介绍Python中两种字符串格式化的方法:百分号方式和format方式。包括格式化参数、对齐方式、符号显示等内容,并附带编码相关知识。
本文介绍Python中两种字符串格式化的方法:百分号方式和format方式。包括格式化参数、对齐方式、符号显示等内容,并附带编码相关知识。
一、字符串格式化
python字符串格式化两种方式:百分号方式、format方式。
1.百分号
%[(name)][flags][width].[precision]typecode
- name 可选,用于选择指定的key
- flags 可选,可供选择的值有:
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
- width 可选,占有宽度
- .precision 可选,小数点后保留的位数
- typecode 必选
- s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
- r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
- c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
- o,将整数转换成 八 进制表示,并将其格式化到指定位置
- x,将整数转换成十六进制表示,并将其格式化到指定位置
- d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
- e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
- E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
- f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
- F,同上
- g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
- G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
以上转载。
msg = "i am %s" % "liang"
msg = "i am %s age %d" % ("liang", 18)
msg = "i am %(name)s age %(age)d" % {"name": "liang", "age": 18}
msg = "percent %.2f" % 99.97623二、format格式化
[[fill]align][sign][#][0][width][,][.precision][type]
- fill 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
- , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
- 传入” 字符串类型 “的参数
tpl = "i am {}, age {}, {}".format("seven", 18, 'alex')
tpl = "i am {}, age {}, {}".format(*["seven", 18, 'alex'])
tpl = "i am {0}, age {1}, really {0}".format("seven", 18)
tpl = "i am {0}, age {1}, really {0}".format(*["seven", 18])
tpl = "i am {name}, age {age}, really {name}".format(name="seven", age=18)
tpl = "i am {name}, age {age}, really {name}".format(**{"name": "seven", "age": 18})
tpl = "i am {0[0]}, age {0[1]}, really {0[2]}".format([1, 2, 3], [11, 22, 33])
tpl = "i am {:s}, age {:d}, money {:f}".format("seven", 18, 88888.1)
tpl = "i am {:s}, age {:d}".format(*["seven", 18])
tpl = "i am {name:s}, age {age:d}".format(name="seven", age=18)
tpl = "i am {name:s}, age {age:d}".format(**{"name": "seven", "age": 18})
tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)
tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)
tpl = "numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15)
tpl = "numbers: {num:b},{num:o},{num:d},{num:x},{num:X}, {num:%}".format(num=15)二、关于编码杂谈
ASCII 占1个字节,只支持英文
GB2312 占2个字节,支持6700+汉字
GBK GB2312的升级版,支持21000+汉字
UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
python3 执行代码的过程:
1.解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2.把代码字符串按照语法规则进行解释,
4.所有的变量字符都会以unicode编码声明
但是python2不会自动转换。
在windows命令行下:
utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如python2 就不是,它的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味你以utf-8编码的文件,在windows是乱码。
因为只有2种情况 ,你的windows上显示才不会乱:1.字符串以GBK格式显示
2.字符串是unicode编码
转换规则:
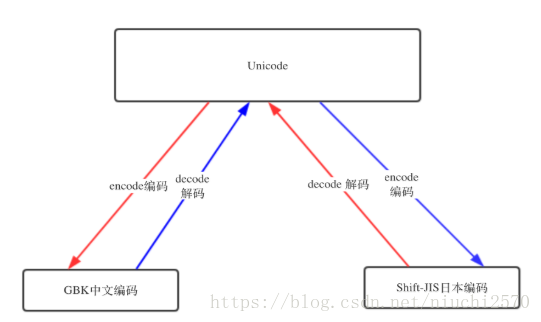
本节转自: http://www.cnblogs.com/alex3714/articles/7550940.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









