







 本文深入探讨了数据预处理的重要性和方法,包括数据清洗、数据变换、离群点检测和数据简化。同时,详细讲解了数据降维的目的、好处及常用方法,如PCA、LDA和流形学习,并对比了它们的优缺点。
本文深入探讨了数据预处理的重要性和方法,包括数据清洗、数据变换、离群点检测和数据简化。同时,详细讲解了数据降维的目的、好处及常用方法,如PCA、LDA和流形学习,并对比了它们的优缺点。
1 为什么要进行数据预处理

1.1 数据清洗
1.1.1 数据清洗常见问题
a. 缺失值处理
b. 噪声数据处理
c. 异常值处理
d. 脏数据处理
e. 去重处理
f. ETL - extract、transform、load
g. 离群点与噪声
噪声: 被测量的变量的随机误差或者方差(一般指错误的数据)
离群点: 数据集中包含一些数据对象,他们与数据的一般行为或模型不一致。(正常值, 但偏离大多数数据)

h. 数据清洗常见问题简介

1.2 数据变换的一般方法

1.3 离群点检测

1.4 数据简化
1.4.1 数据简化定义
也称为数据“规约”,指在尽可能保持数据原貌的前提下,最大限度地精简数据量,它小得多, 但是保持原始数据的完整性。也就是说,在归约后的数据集上挖掘更有效果,仍然产生相同( 或几乎形同)的分析结果。注意:用于数据归约的时间不应当超过或“抵消”在归约后的数据挖掘上挖掘节省的时间。
1.4.2 数据简化常见方法
a. 维规约 - 即“降维”
也称“降维”,减少要考虑的变量及属性的个数。方法包括小波变换和主成分分析,他们把原始数据变换或投影到较小的空间。另外属性子集选择也是一种维归约方法,其中不相关、弱相关或冗余的属性或维被检测和删除。
b. 数量规约
用替代的、较小的数据表示形式替换原始数据。
c. 数据压缩
使用变换,以便得到原始数据的归约或“压缩”表示。如果原始数据可以从压缩后的数据重构,而不损失信息,则该数据归约称为无损的。反之,称之为有损的。维归约和数量归约也可以视为某种形式的数据压缩。
2 数据降维
2.1 选择合适的角度投影,你将看到更多的信息

2.1 什么是数据降维
2.1.1 概念:将数据从高维特征空间向低纬特征空间映射的过程
2.1.2 目的: 直观地好处是维度降低了,便于计算和可视化,其更深层次的意义在于有效信息的提取综合及无用信息的摈弃。
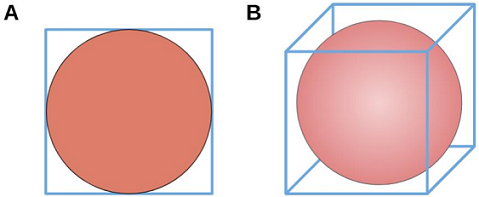
2.2 为什么要进行数据降维
2.2.1 共线性
数据的多重共线性:特征属性之间存在着相互关联关系。多重共线性会导致解的空间不稳定,从而导致模型的泛化能力弱;
2.2.2 稀疏性
高纬空间样本具有稀疏性,导致模型比较难找到数据特征;
2.2.3 找规律
过多的变量会妨碍模型查找规律;
2.2.4 潜在关系
仅仅考虑单个变量对于目标属性的影响可能忽略变量之间的潜在关系;
2.2.5 减少特征属性
减少特征属性的个数;
2.2.6 相互独立
确保特征属性之间是相互独立的;
2.3 数据降维的好处
有时候也存在特征矩阵过大,导致计算量比较大,训练时间长的问题。
降维可以方便数据可视化+数据分析+数据压缩+数据提取等。
2.4 数据降维的常见方法
2.4.1 LDA(线性判别式分析)法
LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
a. 优点
在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识;
LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优;
b. 缺点
LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题;
LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好;
LDA可能过度拟合数据
2.4.2 PCA(主成分分析)法:
主成分分析(Principal components analysis,以下简称PCA)是重要的降维方法之一。PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。中心思想:“使得降维后数据整体的方差最大!”
2.5 PCA与LDA降维方法对比分析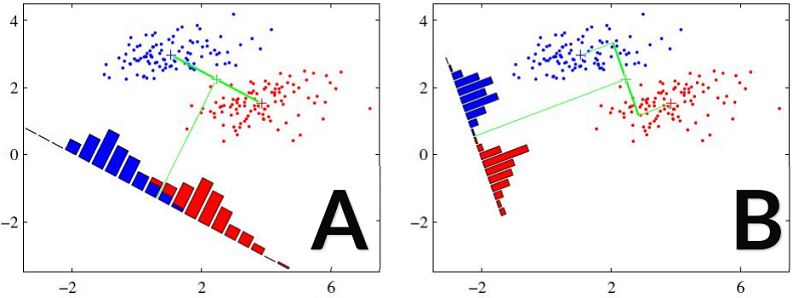
A:PCA降维 B:LDA降维
PCA与LDA的区别

3 流形学习方法
3.1 流形学习思想
基本思想就是在高维空间中发现低维结构。 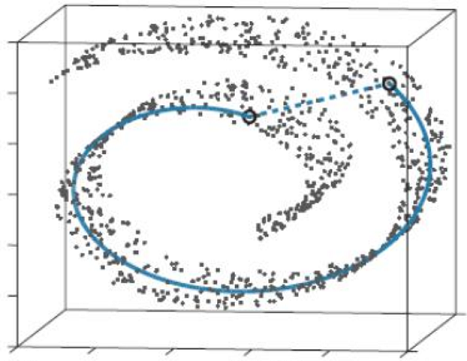
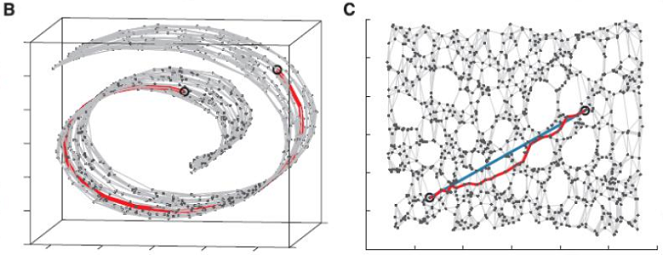
这些点都处于一个三维空间里,但我们人一看就知道它像一块卷起来的布,图中圈出来的两个点更合理的距离是A中蓝色实线标注的距离,而不是两个点之间的欧式距离(A中蓝色虚线)。
此时如果你要用PCA降维的话,它根本无法发现这样卷曲的结构(因为PCA是典型的线性降维,而图示的结构显然是非线性的),最后的降维结果就会一团乱麻,没法很好的反映点之间的关系。而流形学习在这样的场景就会有很好的效果 。
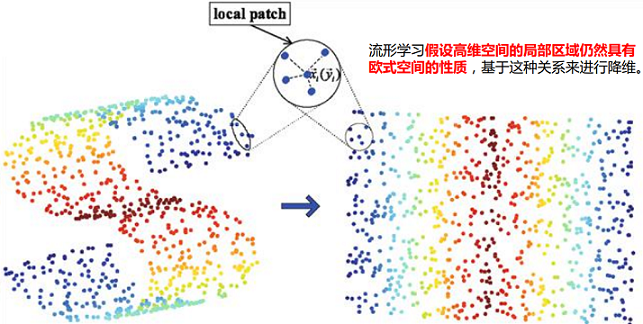
3.2 流形学习的步骤
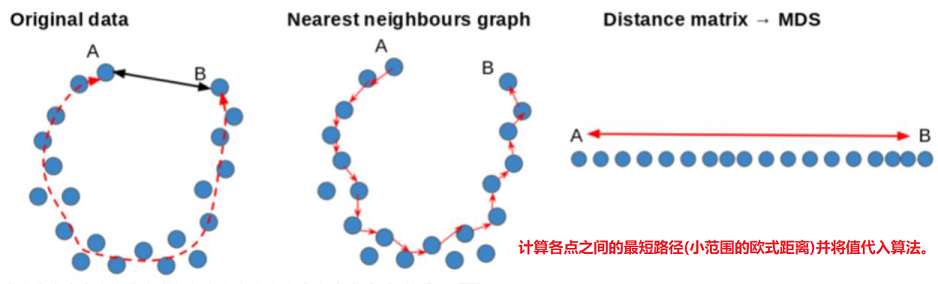
通过kNN(k-Nearest Neighbor)找到点的k个最近邻(小范围),将它们连接起来构造一张图。
通过计算图中各点之间的最短路径,作为点之间的距离dij放入距离矩阵D
将D传给流形学习算法(MDS),得到降维后的结果。
3.3 PCA与流形学习对比
PCA:提供点的坐标降维,找出最能体现数据特点的特征
流形学习:提供点之间距离的降维,更注重原始数据之间的相对关系并展现出来(多维结构)
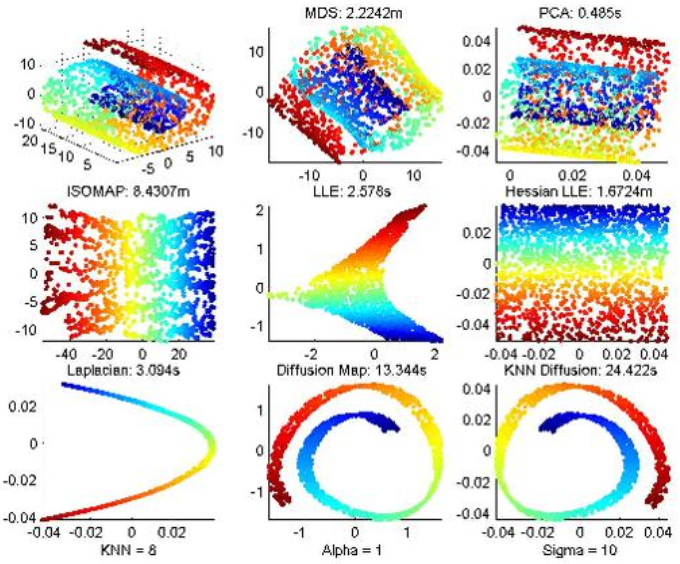
4 各种降维方法展示
---------------------
作者:撇味大白菜
来源:优快云
原文:https://blog.youkuaiyun.com/weixin_42219368/article/details/81009387
版权声明:本文为博主原创文章,转载请附上博文链接!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









