




 本文详细介绍了CSV文件的特点,如逗号分隔、纯文本、字段分隔等,并讲解了Python中读取和写入CSV文件的方法,包括csv.reader、csv.DictReader、csv.writer和csv.DictWriter的使用。此外,还涉及了如何将CSV转换为Excel的xlsx格式,以及如何将CSV数据转换为数组和字典。
本文详细介绍了CSV文件的特点,如逗号分隔、纯文本、字段分隔等,并讲解了Python中读取和写入CSV文件的方法,包括csv.reader、csv.DictReader、csv.writer和csv.DictWriter的使用。此外,还涉及了如何将CSV转换为Excel的xlsx格式,以及如何将CSV数据转换为数组和字典。
CSV的特点
- CSV(Comma-Separated Values)一般是以逗号为分隔符,其文件以纯文本形式存储表格数据(数字和文本),有时也称为字符分隔值,因为分隔字符也可以不是逗号。
- 通常用于在在电子表格软件和纯文本之间交互数据;
- 纯文本,使用某个字符集,比如ASCII、Unicode、EBCDIC或GB2312;
- 由记录组成(典型的是每行一条记录);
- 每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格);
- 每条记录都有同样的字段序列。
- 其他:
- 每条记录占一行 以逗号为分隔符 逗号前后的空格会被忽略
- 字段中包含有逗号,该字段必须用双引号括起来
- 字段中包含有换行符,该字段必须用双引号括起来
- 字段前后包含有空格,该字段必须用双引号括起来
- 字段中的双引号用两个双引号表示
- 字段中如果有双引号,该字段必须用双引号括起来
- 第一条记录,可以是字段名
- csv.reader()函数与csv.writer()相反,用于返回一个可迭代对象,可以读取该对象,并且解析为CSV数据的每一行;
- csv.DictReader类和csv.DictWriter类,用于将CSV数据都进到字典中(首先检查是否使用给定字段名,如果没有,就使用第一行作为键),接着将字典字段写入CSV文件中;
CSV文件的读写格式参数:
- 'r':读
- 'w':写
- 'a':追加
- 'r+' == r+w(可读可写,文件若不存在,就报错(IOError))
- 'w+' == w+r(可读可写,文件若不存在,就创建)
- 'a+' ==a+r(可追加可写,文件若不存在,就创建)
- 如果是二进制文件,就都加一个b:'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
1、读取csv文件
test.csv文件内容
no, name, time, num
1,jay,2020-11-1,10
2,tom,2020-11-2,20
3,bobo,2020-11-3,30
1)csv.reader(fp)读取csv文件
- reader读取全部内容,然后按照行进行输出;
- 可以自定义输出格式;
import csv
# 读取csv
csv_path = 'test.csv' # 读取csv位置
new_line = '' # 换行符
fp = open(csv_path, 'r', encoding='utf-8', newline=new_line)
reader = csv.reader(fp) # 读取csv内容
for no, name, time, num in reader:
print('%s %s %s %s' % (no, name, time, num))
fp.close输出结果:输出的格式自定义过了,与csv格式不同了
no name time num
1 jay 2020-11-1 10
2 tom 2020-11-2 20
3 bobo 2020-11-3 30
2)csv.DictReader(fp)读取csv文件
- 读取到的内容是字典格式,第一行作为字典的key;从第二行开始,作为字典key对应的取值;
- 除了第一行外,有几行就有几个字典值;
import csv
# DictReader读取csv
csv_path = 'test.csv' # csv位置
new_line = '' # 换行符
fp = open(csv_path, 'r', encoding='utf-8', newline=new_line)
# 将CSV 数据读进列表中(首先查找是否使用给定字段名,如果没有,就是用第一行作为键)
reader = csv.DictReader(fp)
print(reader)
print('****************')
for i in reader:
print(i)
fp.close()输出结果:
<csv.DictReader object at 0x000002539979A880>
****************
{'no': '1', ' name': 'jay', ' time': '2020-11-1', ' num': '10'}
{'no': '2', ' name': 'tom', ' time': '2020-11-2', ' num': '20'}
{'no': '3', ' name': 'bobo', ' time': '2020-11-3', ' num': '30'}
2、保存csv文件
1)csv.writer(fp)保存csv文件
import csv
# 保存csv
data = (
('学科编号', '学科', '开班时间', '预计人数'),
('1', 'java', '2020-11-1', '10'),
('2', 'python', '2020-11-2', '20')
)
csv_path = 'output.csv' # 保存csv位置
new_line = '' # 换行符
fp = open(csv_path, 'w', encoding='utf-8', newline=new_line)
writer = csv.writer(fp)
for record in data:
writer.writerow(record)
fp.close()保存的out.csv文件为:
学科编号,学科,开班时间,预计人数
1,java,2020-11-1,10
2,python,2020-11-2,20
2)csv.DictWriter(fp, fieldnames=field_name)保存csv文件
- 表头,如果是字典类型,输出的列名无顺序,每次运行列所在位置不固定;field_name = {'学科编号', '学科', '开班时间', '预计人数'}
- 表头,如果是元组类型,输出的列名有顺序,可以按照定义的位置显示; field_name = ('学科编号', '学科', '开班时间', '预计人数')
- 写入表头,writer.writeheader()
- 字典字段写入到CSV文件,writer.writerow(data)
- data要是字典格式,如data = {'学科编号': '1', '学科': 'java', '开班时间': '2020-11-1', '预计人数': '10'}
- 如果没有指定newline=''为空,输出的记录行之间有空行;
import csv
# DictWriter保存csv
csv_path = 'output.csv' # csv位置
new_line = '' # 换行符
datas = [
{'学科编号': '1', '学科': 'java', '开班时间': '2020-11-1', '预计人数': '10'},
{'学科编号': '2', '学科': 'nodejs', '开班时间': '2020-11-2', '预计人数': '20'},
{'学科编号': '3', '学科': 'python', '开班时间': '2020-11-3', '预计人数': '30'}
]
with open(csv_path, 'w', encoding='utf-8', newline=new_line) as fp:
# 表头,如果是字典类型,输出的列名无顺序
# field_name = {'学科编号', '学科', '开班时间', '预计人数'}
# 表头,如果是元组类型,输出的列名有顺序
field_name = ('学科编号', '学科', '开班时间', '预计人数')
# 创建CSV文件对象
writer = csv.DictWriter(fp, fieldnames=field_name)
# 写入表头
writer.writeheader()
# 直接字典字段写入到CSV文件中
for data in datas:
writer.writerow(data)
print('运行结束')保存的out.csv文件为:
学科编号,学科,开班时间,预计人数
1,java,2020-11-1,10
2,nodejs,2020-11-2,20
3,python,2020-11-3,30
如果没有指定newline=''为空,输出的记录行之间有空行;
保存的out.csv文件为:

3、CSV转为excel的xlsx格式
安装模块:
- pip install --user pandas
- pip install --user openpyxl
csv转为xlsx格式
import pandas as pd
class CsvUtil:
def csv_to_xlsx(self):
input_file_path = r'D:\Nikey\Python\PyCharm\basicProgram\tb_api\data\output\all_reqs.csv'
output_file_path = r'D:\Nikey\Python\PyCharm\basicProgram\tb_api\data\output\all_reqs.xlsx'
csv = pd.read_csv(input_file_path, encoding='gbk')
csv.to_excel(output_file_path, sheet_name='all_reqs')
if __name__ == '__main__':
csv_util = CsvUtil()
csv_util.csv_to_xlsx()输出结果:转换后的xlsx格式的文件增加了第一行编号

4、CVS格式转为数组,每一行为一个字典,第一行是字典的关键字
test.csv文件
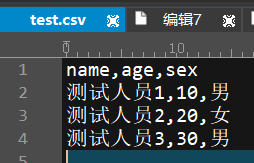
CVS格式转为数组,每一行为一个字典,第一行是字典的关键字
import pandas
class CsvUtil:
def __init__(self, file_path):
self.file_path = file_path # 文件所在位置
# 获取csv文件记录数据
def get_csv_data(self):
csv_read_data = pandas.read_csv(self.file_path, encoding='gbk')
return csv_read_data
# 获取csv文件的记录数据行总数,不包含第一行列标题
def get_csv_data_rows_count(self):
csv_data_rows = 0 # csv记录数据行数,包含的数据总行数,不包含第一行列标题
csv_read_data = self.get_csv_data()
csv_data_columns_list = self.get_csv_data_columns()
csv_data_columns_size = self.get_csv_data_columns_count()
for i in range(0, csv_data_columns_size - 1):
key = csv_data_columns_list[i] # 获取列标题
key_rows = csv_read_data.get(key).count() # 每一列对应的数据记录行数
if key_rows > csv_data_rows: # 取数据记录最大的为行总数
csv_data_rows = key_rows
return csv_data_rows
# 获取csv文件的列标题,数组
def get_csv_data_columns(self):
csv_read_data = self.get_csv_data()
csv_data_columns_list = csv_read_data.columns # 获取csv记录的列标题明细,数组
return csv_data_columns_list
# 获取csv文件的列总数
def get_csv_data_columns_count(self):
csv_data_columns_list = self.get_csv_data_columns()
csv_data_columns_size = csv_data_columns_list.size # 获取csv记录的列总数
return csv_data_columns_size
# 将Csv格式转为数组格式,每一行为一个字典,第一行是字典的关键字
def csv_data_to_list(self):
csv_read_data = self.get_csv_data()
csv_data_rows = self.get_csv_data_rows_count() # 记录数据总行数
csv_data_list = [] # 最终返回的数组
csv_keys = csv_read_data.keys() # 列标题
head = csv_read_data.head(csv_data_rows) # 全量数据
for i in range(0, csv_data_rows): # 每一行数据遍历,先给字典赋值,再将字典添加到数组中
csv_data = {}
for key in csv_keys:
csv_data[key] = head.get(key)[i]
csv_data_list.append(csv_data)
return csv_data_list
if __name__ == '__main__':
file_path = './data/input/test.csv'
csv_util = CsvUtil(file_path)
csv_data_list = csv_util.csv_data_to_list()
print(csv_data_list)
输出结果:
[{
'name': '测试人员1',
'age': 10,
'sex': '男'
}, {
'name': '测试人员2',
'age': 20,
'sex': '女'
}, {
'name': '测试人员3',
'age': 30,
'sex': '男'
}]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









