




聪明在于勤奋,天才在于积累。
目录

zset 有序集合
有序集合相对于字符串、列表、哈希、集合来说会有一些陌生。它保留了集合不能有重复成员的特点,但与集合不同的是,有序集合中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数。
下图是一个很典型的示例:
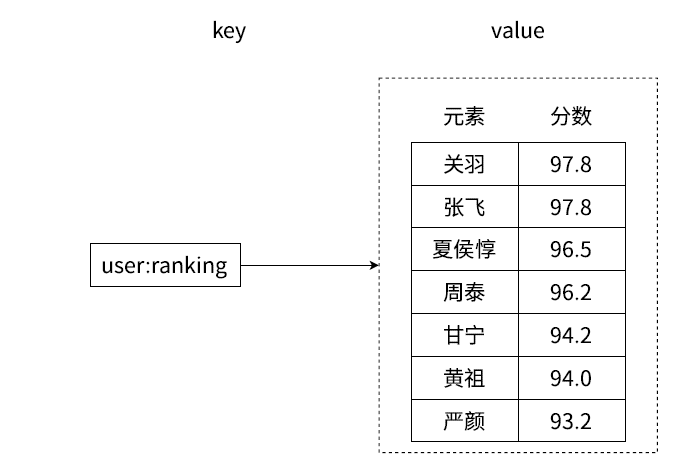
分数设置好之后,就可以根据分数来进行排序。
但是任然需要要求zset中的元素是唯一的,因为zset依然是一个集合类型。但是分数是可以重复的。zset主要还是用来存member,分数只是用来辅助的作用。
zset相关命令
zadd
往一个有序集合中添加member(元素)和分数。
member是唯一的,但是分数是可以相同的,相同的分数会有什么效果?相同的分数之间排序是根据member的字典顺序进行排序的。上面有一张图很好的说明了 这点。
语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]- key 是一个最基本的键值对,是zadd的作用对象。
- 添加的时候,既要添加元素,又要添加分数。这里的member和score称为一个pair。不要把pair理解为一个键值对。
- XX:(exists)仅仅用于更新已经存在的元素,不会添加新元素
- NX:(not exists)仅仅添加新元素,不会更新已经存在的元素
- GT:greater than。仅仅当更新分数的时候,新的分数小于原来的分数才生效。
- LT:less than。仅仅当更新分数的时候,新的分数大于原来的分数才生效。
- CH:(changed)默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
- incr:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定一个元素和分数。
- 时间复杂度:O(
N)。
- 返回值:本次添加成功的元素个数
示例:

查看里面的有序集合中的元素详细:
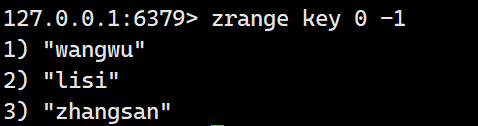
但是没有分数。携带参数withscores继续查询(查询结果是升序的):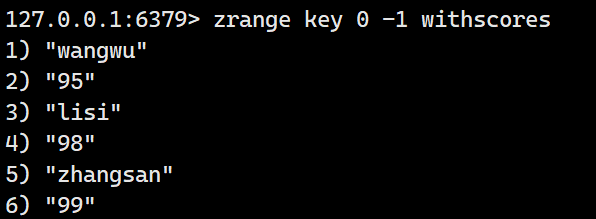
尝试将zhangsan的分数99改为97
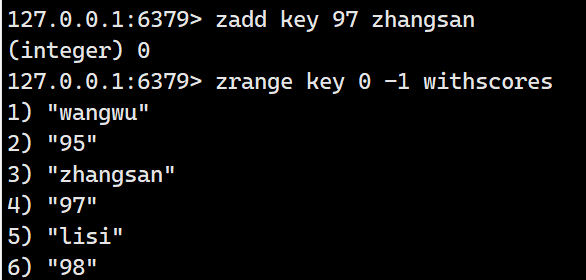
修改的分数会自动进行移动元素位置,保持原有的升序顺序。
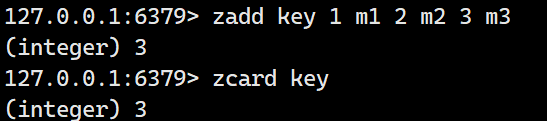
zcard
获取一个 zset 的基数(cardinality),即 zset 中的元素个数
语法:zcard key
- 时间复杂度:O(1)
- 返回值:zset 内的元素个数。
示例:
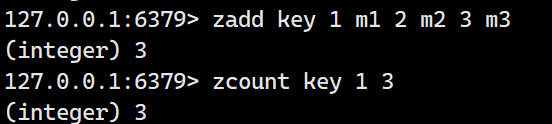
zcount
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:zcount key min max
- 时间复杂度:O(log(N))
- 返回值:满足条件的元素列表个数。
- min和max本身是可以写成浮点数的。
- min和max默认是闭区间,如果想排除边界值,可以在数值的前面加上括号
- 支持使用 'inf' 和 '-inf' 来表示min和max。
示例:
排除边界值1:

排除边界值3:

浮点数中存在两个特殊的数值:
- Inf:无穷大
- -inf:负无穷大
可以使用inf和-inf来找到zset中的所有元素:

zrange
返回指定区间里的元素,分数按照升序。带上 WITHSCORES (withsocres)可以把分数也返回。
语法:zrange key start stop [withscores]
- 此处的 [start, stop] 为下标构成的区间. 从 0 开始, 支持负数.
- 时间复杂度:O(log(N)+M)
- 返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset 2 3
1) "three"
redis> ZRANGE myzset -2 -1
1) "two"
2) "three"zrevrange
返回指定区间里的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
语法:zrevrange key start stop [withscores]
- 备注:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中
- 时间复杂度:O(log(N)+M)
- 返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
3) "two"
4) "2"
5) "one"
6) "1"
redis> ZREVRANGE myzset 0 -1
1) "three"
2) "two"
3) "one"
redis> ZREVRANGE myzset 2 3
1) "one"
redis> ZREVRANGE myzset -2 -1
1) "two"
2) "one"zrangebyscore
返回分数在 min 和 max 之间的元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:zrangebyscore key min max [withscores]
- 备注:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
- 时间复杂度:O(log(N)+M)
- 返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
redis> ZRANGEBYSCORE myzset (1 2
1) "two"
redis> ZRANGEBYSCORE myzset (1 (2
(empty array)zpopmax
删除并返回分数最高的 count 个元素。
语法:ZPOPMAX key [count]
- 时间复杂度:O(log(N) * M),N为有序集合的元素,M为count值
- 返回值:删除后的,显示分数和元素的列表。
- 如果最高分数存在多个member, 那么仍然只删除一个,并且删除的那个是经过字典序比较的最大的那个
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMAX myzset
1) "three"
2) "3"携带count版本:
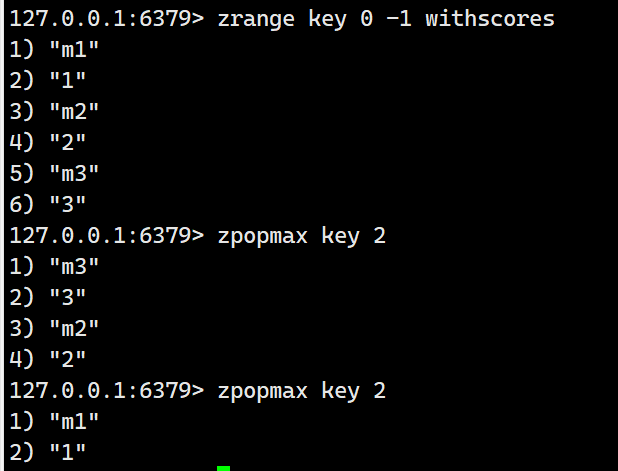
这个里面是删除的是最大值,最大值的位置位于尾部,那为什么不把最大值的元素的位置给记下来,那么这个删除操作不就成为了O(1)了?很遗憾redis目前并没有这么做,事实上redis源码中记录了这个特殊的位置,但是在删除的时候并没有调用这个特性,而是使用了一个通用的删除函数:给定一个member的值,进行时间复杂度为logN的查找,然后进行删除。
阻塞版本zpopmax
bzpopmax
删除并返回分数最高的 count 个元素,阻塞在有序集合为空的时候触发,直到有其他客户端向当前访问阻塞的key里面插入了新的元素,timeout表示超时时间,单位为秒。
语法:bzpopmax key [key ... ] timeout
- 时间复杂度:O(log(N))
- 返回值:元素列表。
- 多个key的情况,bzpopmin只从这众多的key中删除一次。
- 有序集合里面有元素的时候,bzpopmax和zpopmax无异。
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMAX zset1 zset2 0
1) "zset1"
2) "c"
3) "2"
有max,当然也有min,其用法和max一样。
zpopmin
删除并返回分数最低的 count 个元素。
语法:ZPOPMIN key [count]
- 时间复杂度:O(log(N) * M),N为有序集合的元素,M为count值
- 返回值:删除后的,显示分数和元素的列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMIN myzset
1) "one"
2) "1"bzpopmin
ZPOPMIN 的阻塞版本。删除并返回分数最低的 count 个元素,阻塞在有序集合为空的时候触发,直到有其他客户端向当前访问阻塞的key里面插入了新的元素,timeout表示超时时间,单位为秒。
语法:BZPOPMIN key [key ...] timeout
- 时间复杂度:O(log(N))。
- 返回值:执行删除操作之后的元素列表。
- 多个key的情况,bzpopmin只从这众多的key中删除一次。
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMIN zset1 zset2 0
1) "zset1"
2) "a"
3) "0"zrank
返回指定元素的排名,升序。降序版本命令为zrevrank, 其用法和zrank相同,这里不对zrank做过多的讲解。
语法:zrank key member
- 时间复杂度:O(log(N))
- 返回值:排名。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)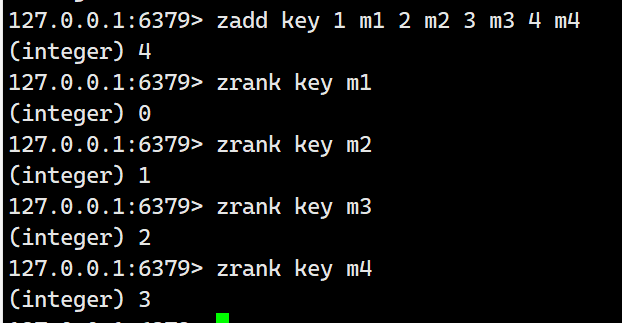
每一个元素进行排序之后,进行rank操作后会将其像列表一样排序如下,下面是一个对比图:

zscore
查询指定member的分数。
语法:zscore key member
- 时间复杂度O(1)
- 返回值:分数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"zrem
根据member名,删除指定的元素。
语法:zrem key member [ member ... ]
- 时间复杂度:O(M*log(N)),N是整个集合中元素的个数,M是参数中的member的个数。
- 返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"zRemRangeByRank
根据排名来进行返回删除。这里的排名可以理解为zset的有序的下标。
语法:zremrangebyrank key start stop
- 时间复杂度:O(log(N)+M),N是整个集合的元素个数,M是start和stop区间中的元素个数。
- 返回值:本次操作删除的元素个数。
- 元素包含start和stop下标的元素。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYRANK myzset 0 1
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"也可以根据分数来进行范围删除
zRemRangeByScore
按照分数删除指定范围的元素,左闭右闭。
语法:zRemRangeByScore key min max
- 时间复杂度:O(log(N)+M)
- 返回值:本次操作删除的元素个数。
示例:
首先插入四个元素:

然后删除分数在1~2之间的分数,包含1和2:
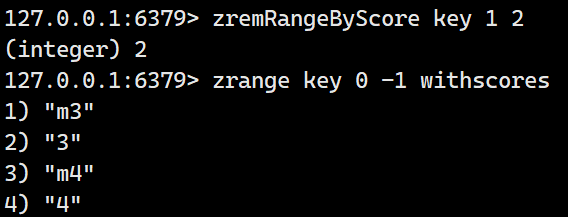
zincrby
为指定的元素的关联分数添加指定的分数值。
语法:zincrby key increment member
- 时间复杂度:O(log(N))
- 返回值:增加后元素的分数。
示例:
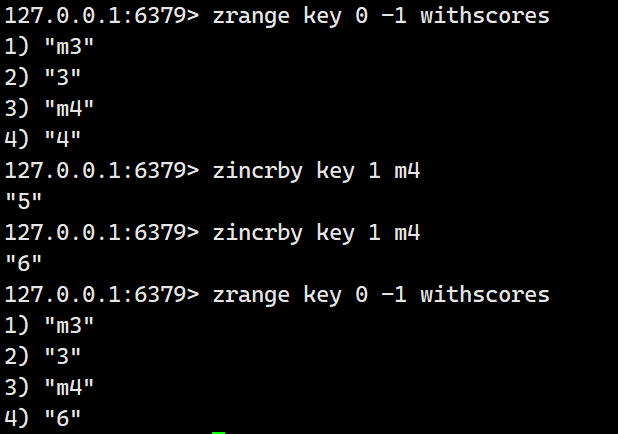
如果想要实现减法,就将increment设置为负数:
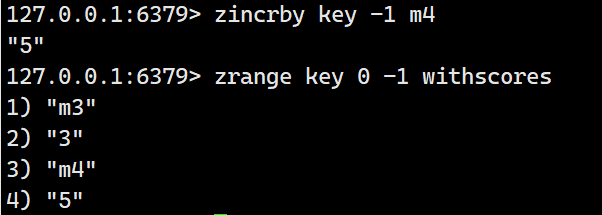
集合间操作
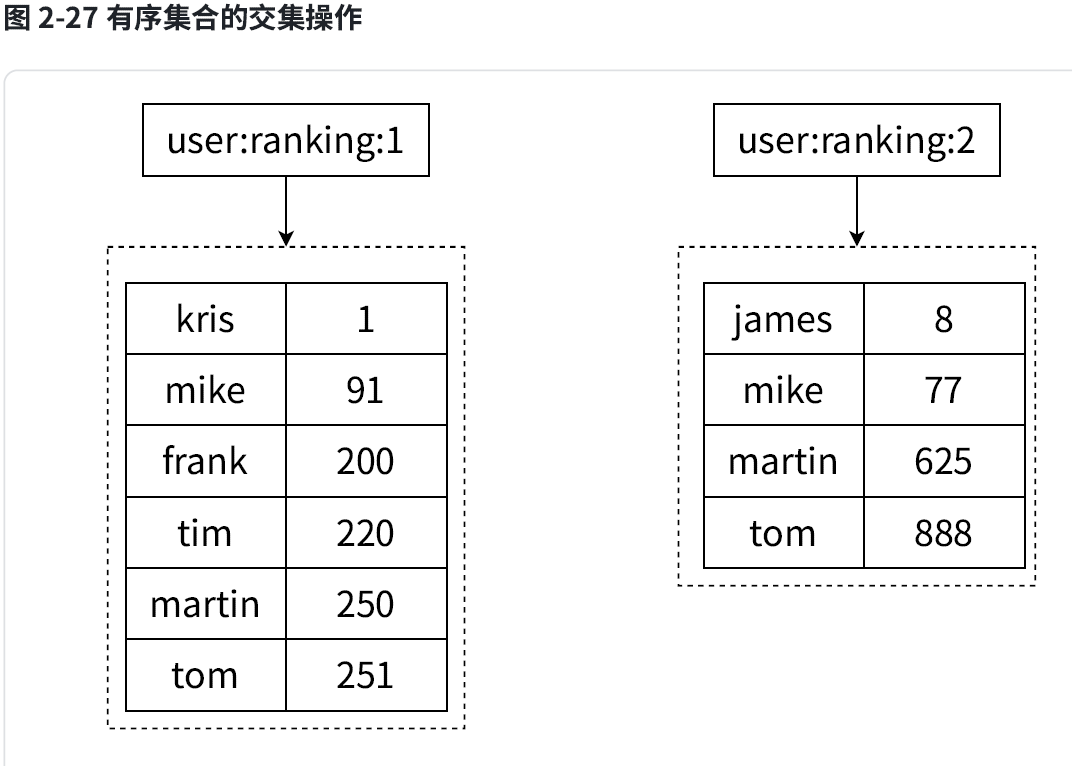
之前的集合使用的集合间命令:sdiff, sunion,sinter。
对于此处的有序集合zset同样存在这种操作,这里不做过多讲解,其使用方法和sdiff等相同。
zinterstore
求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
语法:
zinterstore desKey numsKeys key [key ... ] [weights weight [weight ... ]] [aggregate < sum | min | max>]- desKey表示最终的结果存放到哪个key。
- numkeys描述后续有几个key参与运算。如果是三个key求交集,那么numkeys = 3
- 为什么需要numkeys来描述?这是因为在key的参数后面还有weight参数,如果不设置numkeys,那么就无法区分后面的weight参数。这个就类似于http协议中面向字节流的一种粘宝问题。
- weight:权重,
- 时间复杂度:O(N*K)+O(M*log(M)) N 是输入的有序集合中, 最小的有序集合的元素个数; K 是输入了几个有序集合; M 是最终结果的有序集合的元素个数.
- 返回值:目标集合中的元素个数
示例:
在有序集合中,member才是主体,score只是辅助排序的工具。因此在比较相同的时候,只需要member相同即可,首先这里有两个key:

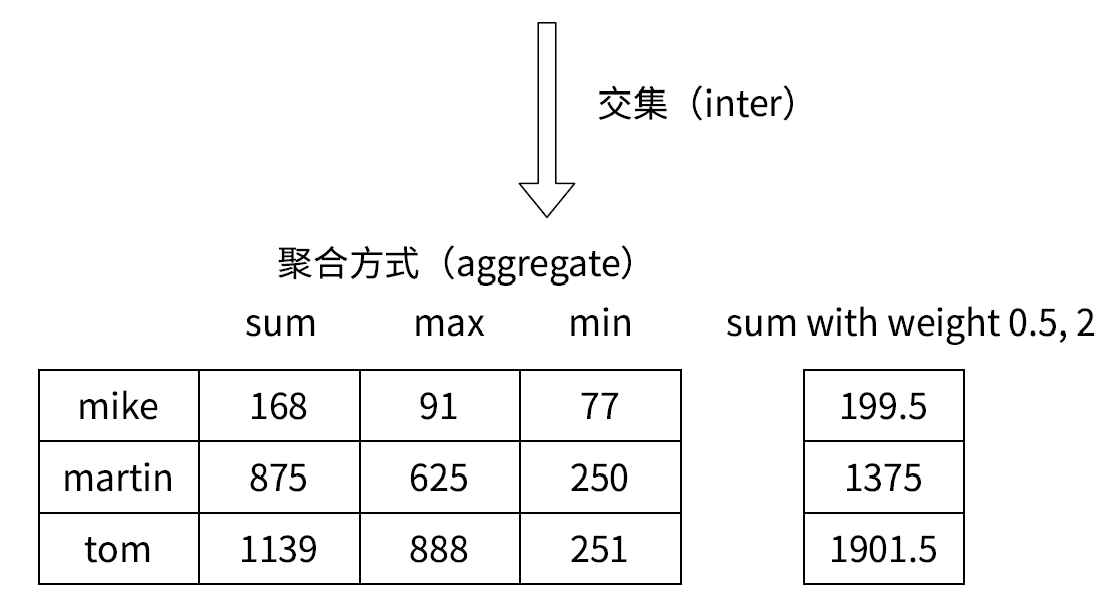
在进行zinterstore的时候, 如果是sum,那么具有相同member的就相加,如果是max,那么就去最大的,反之min就取最小的:
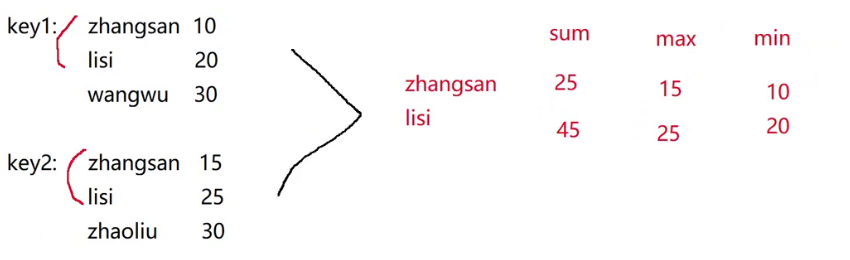
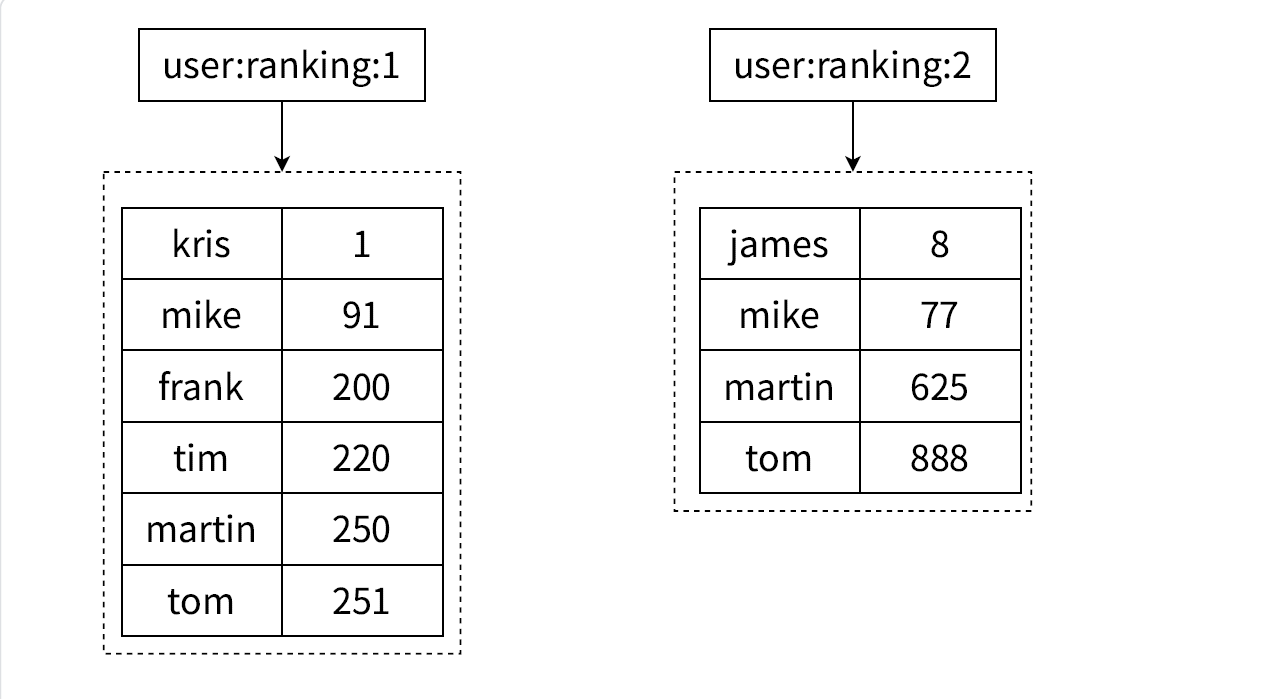
下面正式举例子,加入我们有两个key,一个是key,另外一个是key2:
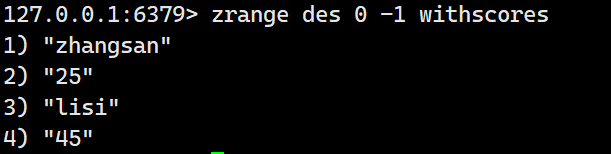
 也就是如上面的手绘图一样:
也就是如上面的手绘图一样:

不加任何参数:

如果加上权重weight:
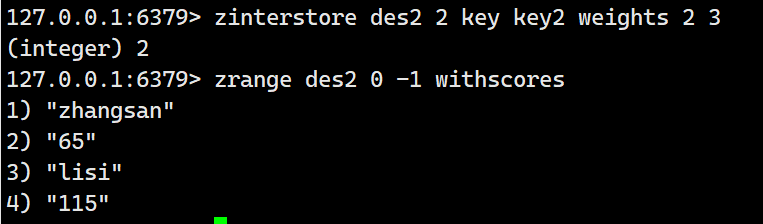
这里的权重的意思就是,将key中的分数乘以2,然后将key2中的分数乘以3,然后相加。
这里默认是将多个key相加,但是也可以进行修改,变成其他的策略,可以在weight参数后面添加上计算方式的参数:
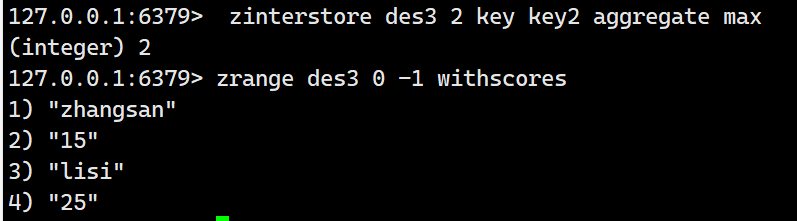
这里取最大值:
取最小值: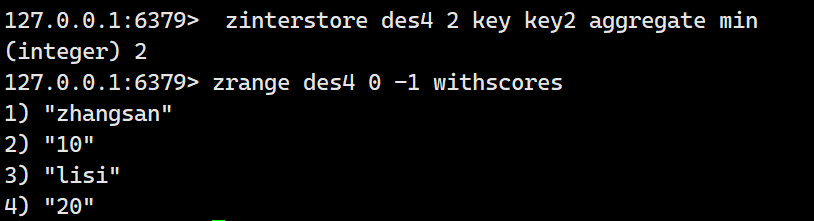
zunionstore
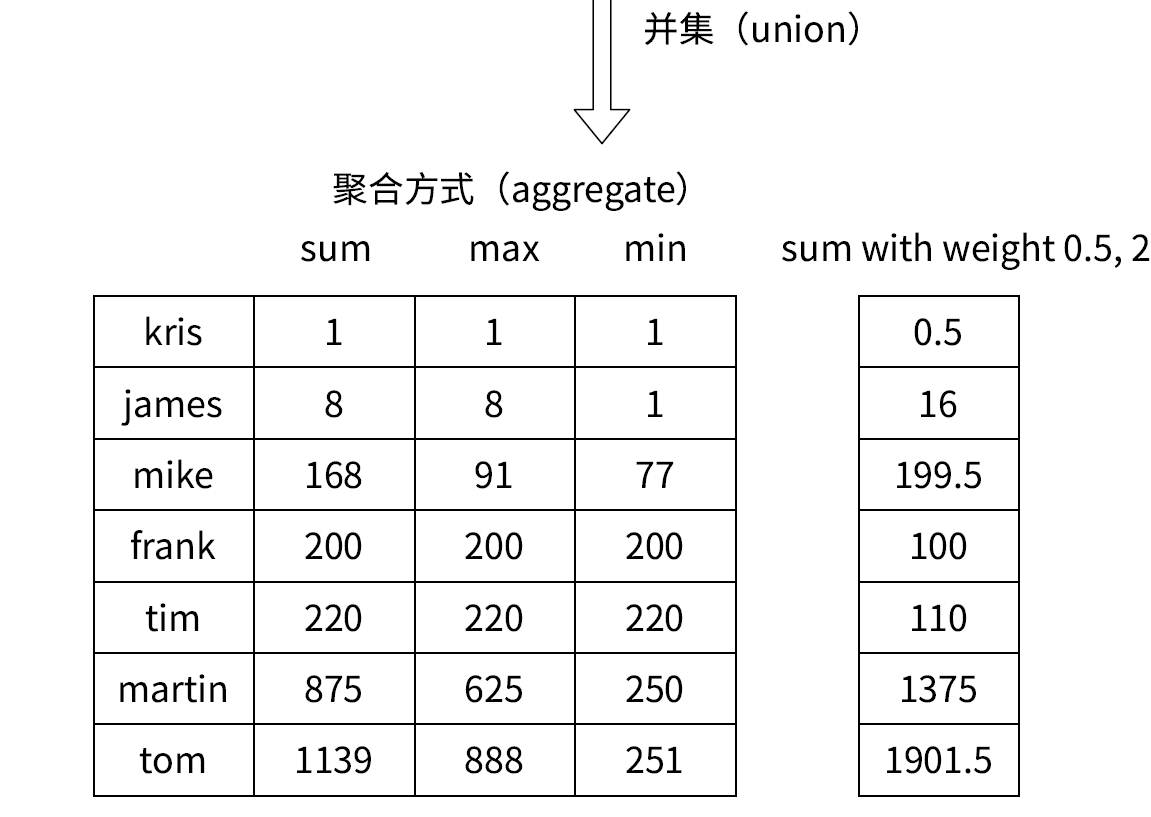
求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
- 命令有效版本:2.0.0 之后
- 时间复杂度:O(N)+O(M*log(M)) N 是输入的有序集合总的元素个数; M 是最终结果的有序集合的元素个数.
- 返回值:目标集合中的元素个数
示例:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZUNIONSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 3
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "three"
4) "9"
5) "two"
6) "10"这里代码我就不多敲了~~~
小结
| 命令 | 时间复杂度 |
|---|---|
| zadd key score member [score member ...] | O(k * log(n)),k 是添加成员的个数,n 是当前有序集合的素个数 |
| zcard key | O(1) |
| zscore key member | O(1) |
| zrank key member zrevrank key member | O(log(n)),n 是当前有序集合的元素个数 |
| zrem key member [member ...] | O(k * log(n)),k 是删除成员的个数,n 是当前有序集合的元素个数 |
| zincrby key increment member | O(log(n)),n 是当前有序集合的元素个数 |
| zrange key start end [withscores] | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元素个数 |
| zrevrange key start end [withscores] | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元素个数 |
| zrangebyscore key min max [withscores] zrevrangebyscore key max min [withscores] | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元素个数 |
| zcount | O(log(n)),n 是当前有序集合的元素个数 |
| zremrangebyrank key start end | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元素个数 |
| zremrangebyscore key min max | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元素个数 |
| zinterstore destination numkeys key [key ...] | O(n * k) + O(m * log(m)),n 是输入的集合最小的元素个数,k 是集合个数, m 是目标集合元素个数 |
| zunionstore destination numkeys key [key ...] | O(n) + O(m * log(m)),n 是输入集合总元素个数,m 是目标集合元素个数 |


















 1341
1341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









