




目录
数据库层面基本操作
显示当前的数据库
show databases;
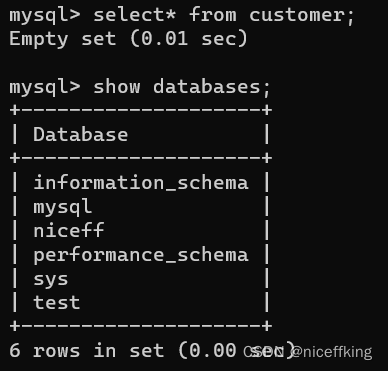
里面包含了:
information_schema,
mysql,
niceff....等数据库
创建数据库
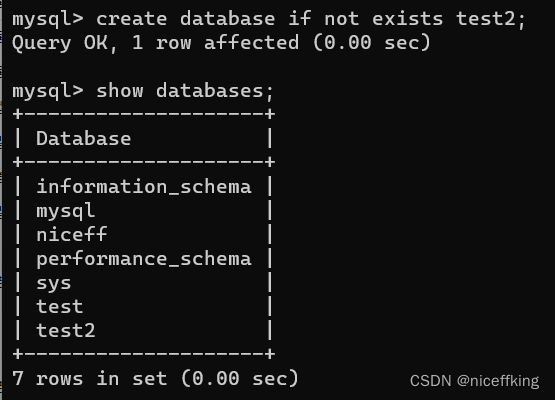
create database 数据库名;
直接创建

create database if not exists 数据库名;
使用数据库
use 数据库名;
使用use + 数据库名,进入到当前数据库:

删除数据库
drop database 数据库名;
drop database if exists 数据库名;

删除数据库是一个非常危险的行为,一定要谨慎再谨慎(删除表同样危险),数据库一旦删除,里面的表和数据也会被全部删除.
常用数据类型
int:整型
decimal(M, D):浮点数类型
varchar(SIZE):字符串类型
timestamp:日期类型
表的操作
如果需要对某一个数据库里面的表进行操作,首先需要使用改数据库,也就是使用use + 数据库名的形式
创建表
create table 表名(field1 dataType, field2 dataType, field3 dataType, ..........);
例如:

也可以使用comment增加字段说明:

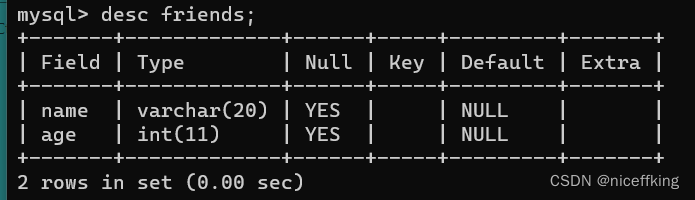
查看表的结构
desc 表名;
desc为describe的缩写,意为描述.
注意:describe为MySQL中的关键字,如果使用describe 表名的结构会创建失败
删除表
drop table 表名;
drop table if exists 表名;
注释
在SQL中可以使用“--空格+描述”来表示注释说明
例如:

练习
有一个商店的数据,记录客户及购物情况,有以下三个表组成:
-
商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供
应商provider)
-
客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证
card_id)
-
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
create database datas default character set utf8;
use datas;
create table if not exists goods
(
goods_id int comment '商品编号',
goods_name varchar(32) comment '商品名称',
unitprice int comment '商品价格',
category varchar(50) comment '商品类别',
provider varchar(50) comment '供应商'
);
create table if not exists customer
(
customer_id int comment '客户号',
name varchar(50) comment '姓名',
address varchar(100) comment '住址',
email varchar(50) comment '邮箱',
sex varchar(20) comment '性别',
card_id varchar(20) comment '身份证'
);
create table if not exists purchase
(
order_id varchar(20) comment '订单号',
customer_id int comment '客户号',
goods_id varchar(20) comment '商品号',
nums int comment '购买数量'
);
表的增删改查
表的增删改查也称作CRUD:
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
增
使用insert into语句:
insert into 表名 values(value1, value2, value3, ..... );
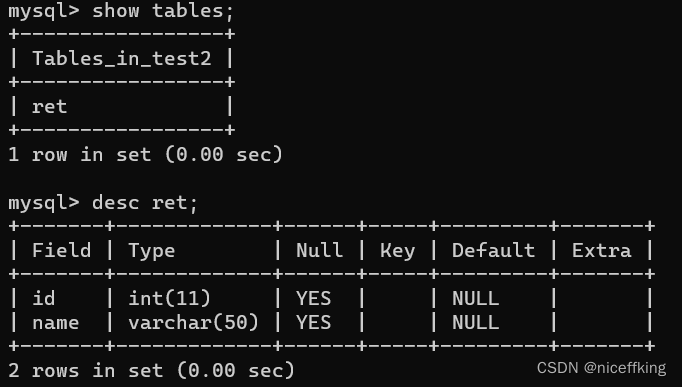
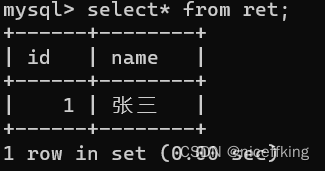
首先新建一个表:

如下:
单行插入
insert into 表名 values( value1, value2, value3, ..... );
写入的参数必须和创建表的时候的数据参数顺序一致;

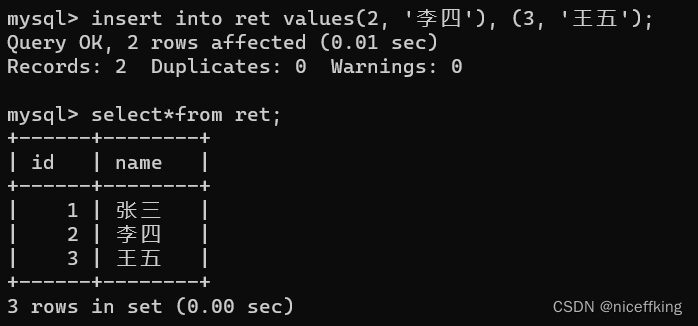
全列插入
insert into 表名 values( value1, value2, value3, ..... ), ( value1, value2, value3, .....);
写入的参数必须和创建表的时候的数据参数顺序一致;
指定参数顺序插入
insert into 表名(valueA, valueB, valueC,......) values(valueA, valueB, valueC,......)
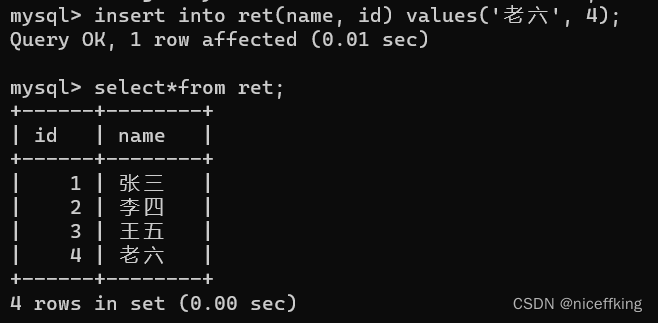
name 为varchar类型的数据,id为int类型的数据,所以在插入记录的时候,首先需要按顺序输入name的参数,然后输入id的参数.
多行和单行插入的性能对比
由于MySQL是一个'客户端服务器'结构的程序, 在MySQL中使用insert into语句的时候,会向服务器发送一次请求, 那么如果是多行输入, 只需要一次请求就可以插入多行记录, 如果是单行输入,那么多行记录就只能向服务器请求多次, 所以多行插入的性能消耗是比单行出入少的.
时间类型的插入
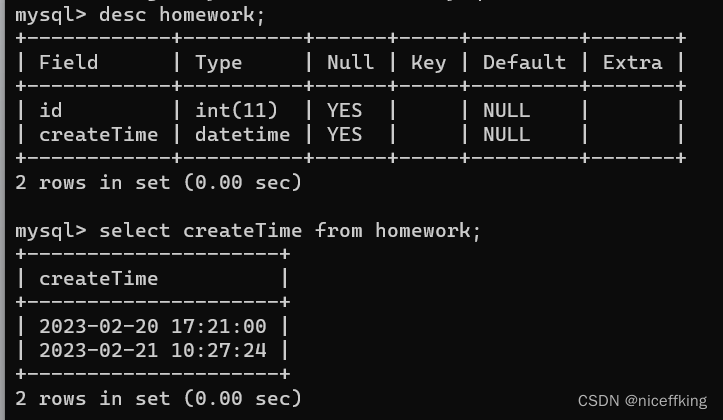
在ret数据库中创建一个表,表名为homework:
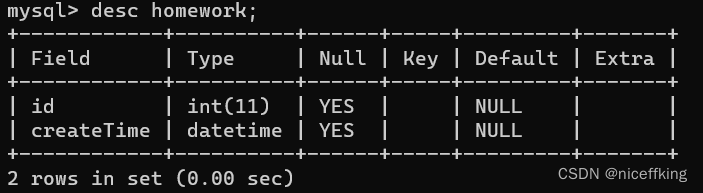
往这个homework里面插入数据(记录),使用特定格式字符串:
形如:
'2023-02-20 17:21:00'
自定义输入时间
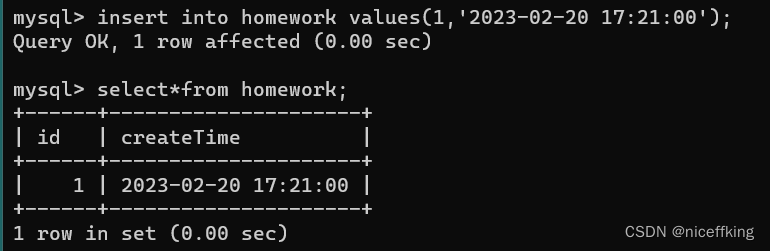
例如:
insert into homework values(1,'2023-02-20 17:21:00');
设置为当前时间
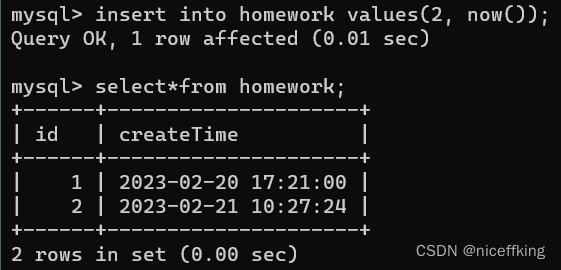
假如我想直接输入当前的时间,该怎么做? MySQL提供了一个特殊的函数: now()
例如:
insert into homework values(2, now());
查
使用select语句
全列查找
select*from 表名;
'*' 表示所有列,这种符号在计算机当中称为'通配符', 通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正的字符
例如:
话说回来,MySQL是一个'客户端服务器'结构的程序, 如果当select* 时数据量过大, 单个数据通道的传输的数据量就会变大, 这就会沾满硬盘带宽或者影响网络的使用.
指定列查询
select 列名1,列名2,列名3...... from 表名;
例如:
表达式查询
(以下查找都是基于列与列之间的计算)
创建一个表(exam_result):
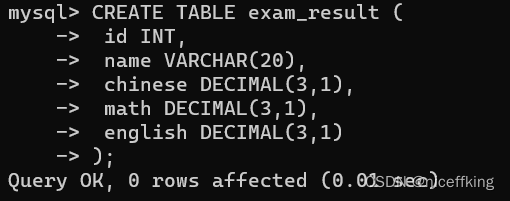
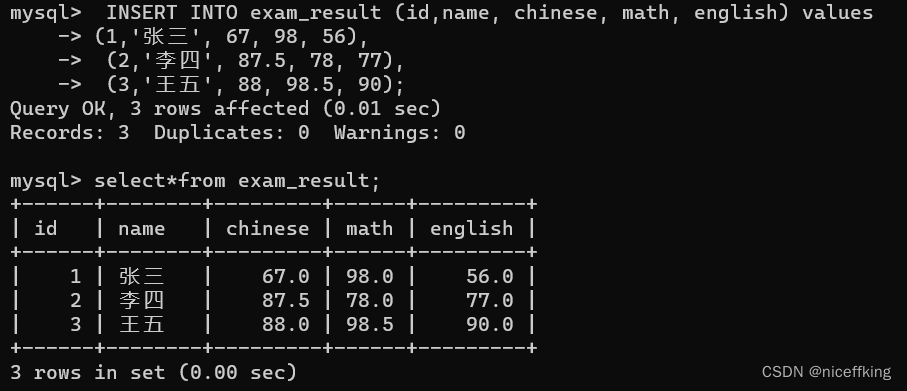
插入:
(1, '张三', 67, 98, 56),
(2, '李四', 87.5, 78, 77),
(3, '王五', 88, 98.5, 90)
不包含字段
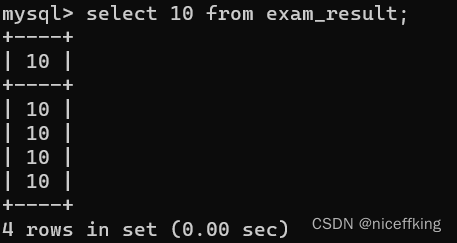
一个字段
如果要对chinese + 10 的方式进行查询,如下
select name, chinese + 10 from exam_result;
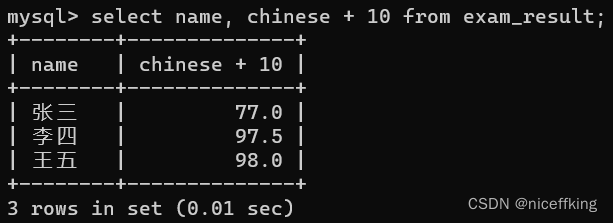
结果如上.
多个字段
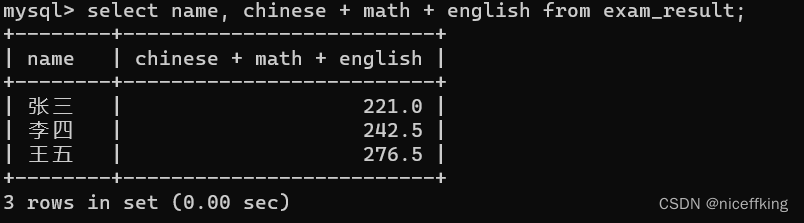
或者查询chinese,matzh,english的综合成绩:
select name, chinese + math + english from exam_result;
查询对原数据是否有影响
但是我们当前存储的结果是否发生改变?
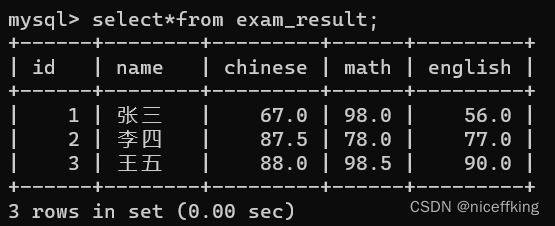
再次全列查找,发现原始的数据是没有发生改变的.
MySQL是一个'客户端服务器'结构的程序, 此时用户输入的sql, 通过请求发送给服务器,服务器解析并执行sql, 把查询的结果从硬盘上读取出来,然后用网络的形式响应, 返还给用户, 客户端再把这些数据以临时表的形式展现出来.所以不会改变原来的数据.
有时候这种chinese + math + english的表达式在理解上可能不够直观,需要进行简化:可以在查询的时候指定别名,指定别名相当于给这个chinese + math + english取了一个小名,让它理解起来更加容易.
使用:全名 as 小名的方式
select chinese + math + english as 小名
select chinese + math + english as total from exam_result;
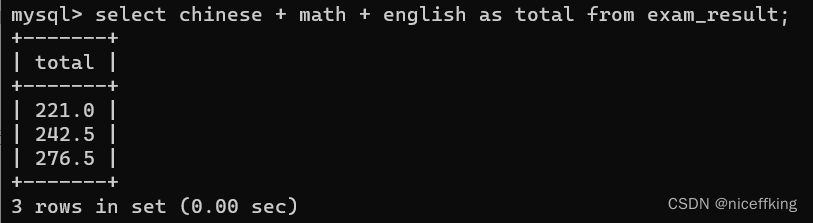
当小名为中文的时候,不需要加上单引号或者双引号.
查询结果去重
例如:
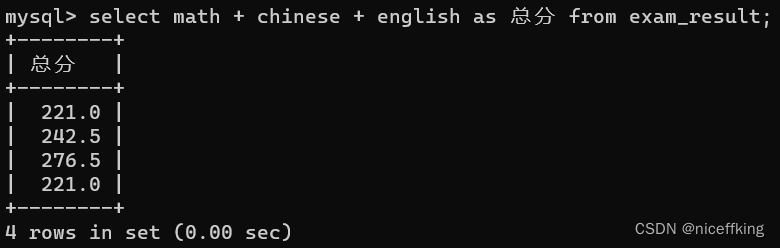
里面有221分的重复项,使用distinct关键字,如下
select distinct math + chinese + english as 总分 from exam_result;
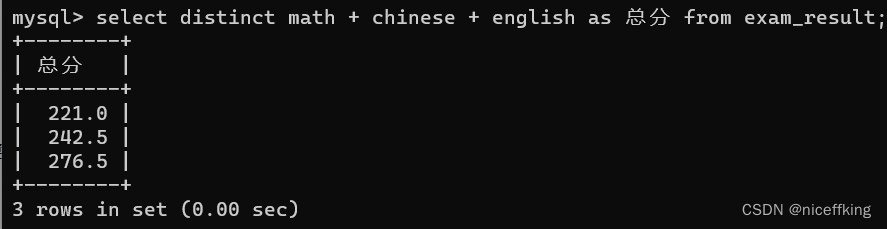
他会把重复的去掉,只留下一个数据.
如果distinct指定多个列的话,则这些列的值都相同,才视为重复.
查询结果排序
单权重
使用order by 来对查询结果排序.可能是升序~~也可能是降序~~
例如,存在以下表:
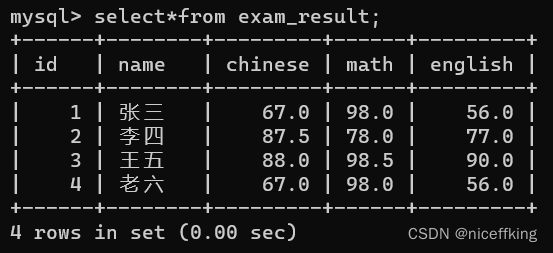
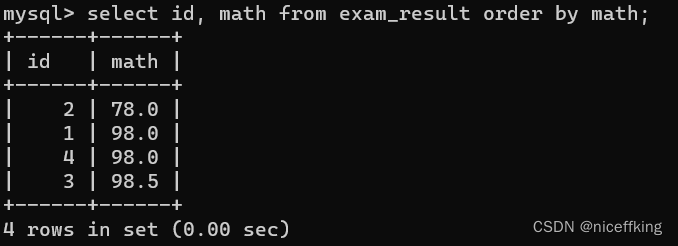
以math的数据为权重,来对查询结果进行一个排序:
select id, math from exam_result order by math;
默认升序(从上往下递增)
或者在order by 权重 后面加一个 desc(descend)来让它以降序排序:
select*from exam_result order by math desc;
还可以使用asc表示升序.
但是,如果在查询的时候没有指定使用order by,则此时的查询结果的顺序时不可预期的.
多权重
如果一个order by 权重后面还有一个权重,形如:
select*from 表名 order by weight1, weight2, weight3.....
那么,排序就会先按照weight1的权重进行升序或者是降序排序,如果weight1这一列里面有相同的数据,那么这些相同的数据会根据weight2的权重进行升序或者是降序排序....以此类推.
条件查询
在筛选,查询的过程中指定查找的条件(符合条件的数据留下,不符合的去除)
描述条件
MySQL中使用一系列的运算符,搭配where来描述:
比较运算符
| 运算符 | 说明 |
| < <= > >= | 小于,小于等于,大于,大于等于 |
| = | 等于,NULL不安全,NULL = NULL的结果为NULL |
| <=> | 等于,NULL安全,NULL <=> NULL结果为TRUE(1) |
| between a0 and a1 | 范围匹配,[a0, a1], a0 <= value <= a1, 返回TRUE(1) |
| in(ex1,ex2,ex3, ..... ) | 如果数据属于ex1,ex2,ex3,......其中任意一个,返回TRUE(1) |
| is NULL | 是空(NULL) |
| is not NULL | 不是空(NULL) |
| like | 模糊匹配, %表示任意多个(包括0个)字符; _表示任意一个字符 |
不支持+=运算符
例如:查找英语分数<60的人
select*from exam_result where english < 60;
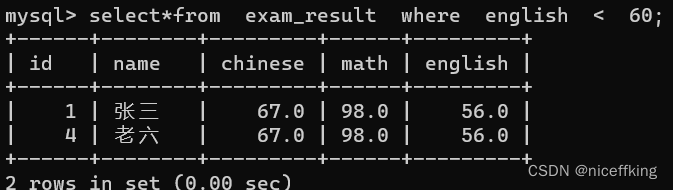
相当于对当前表进行遍历,取出每一条数据,看条件是否满足如果满足,这个记录就会被保留,作为结果集的一部分,否则这个记录就不会被记录,然后继续遍历下一个数据.
也可以直接拿两个列进行比较:
select*from exam_result where math > chinese;
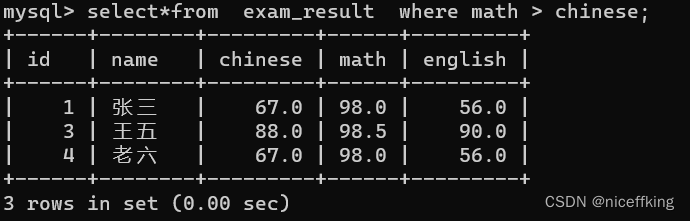
但是要注意null的比较,例如:
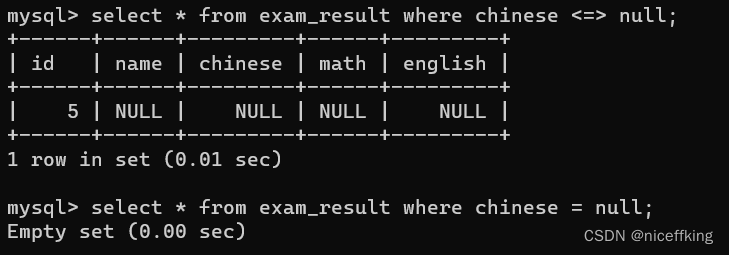
如果使用=对含有null的表达式进行比较,结果还是null => 相当于false,其数据就不会被记录
所以要使用<=>来比较含有null的数据,例如 null <=> null 结果为true;
逻辑运算符
| 运算符 | 说明 |
| and | 多个条件都为TRUE(1),结果才为TRUE(1) |
| or | 任意条件为TRUE(1),结果才为TRUE(1) |
| not | 条件为TRUE(1),结果为FALSE(0) |
注意:and 和 or 存在一个优先级问题, and 的优先级 > or 的优先级,所以先执行and ,后执行or
例如:
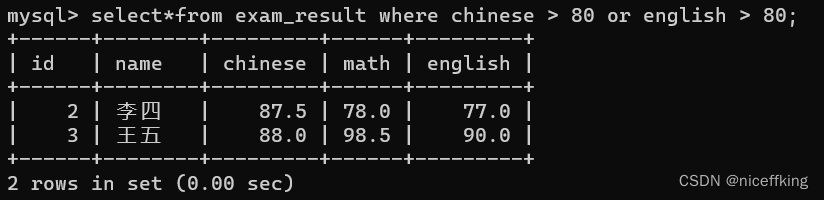
select*from exam_result where chinese > 80 and english > 80;
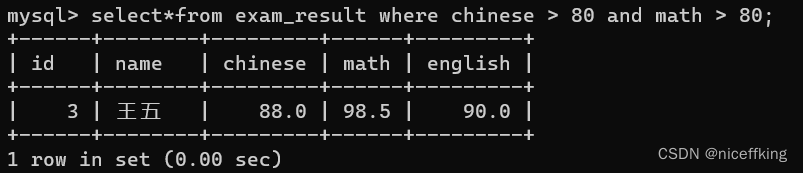
select*from exam_result where chinese > 80 or math > 80;
比较或者逻辑运算中的表达式查询
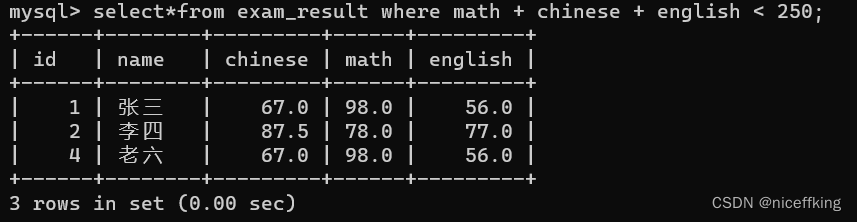
例如
select*from exam_result where math + chine + english< 250;
但是,条件查询里面的比较的对象不能是前面数据的小名,例如:
select id, math + chinese + english as total from exam_result where total < 250;

写下一个sql不是从前往后的执行, 执行顺序是有特殊规定的:
-
遍历每一行
-
把这一行带入到where后面的条件判断里面去
-
符合条件的结果,再根据select指定的列,进行查询/计算.
模糊查询
不要求元素完全相同,只要满足一定的规则就可以了,正则表达式就是模糊匹配的典型实现.
like支持两个用法:
-
使用 %表示0个或者n个字符,例如 '张%'就是匹配所有以张开头的数据,如果是'张三%',就匹配所有以张三开头的数据.同理'%张'是查询以'张'结尾的数据.若是'%张%',则是查询包含'张'的数据.
-
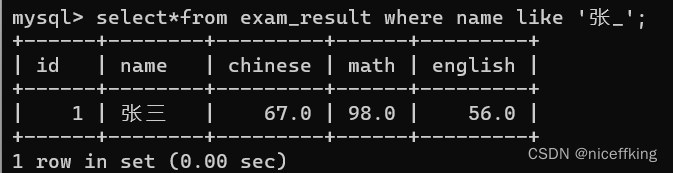
使用 _ 代表任意一个字符,例如'张_' ,就会匹配张开头,后面_可以代表任意的字符
例如:
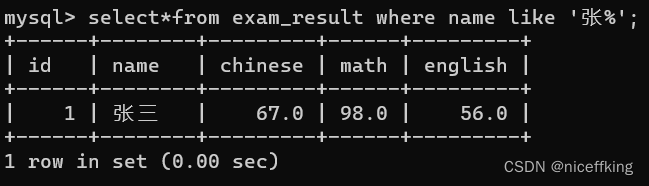
select*from exam_result where name like '张%';
查询name中以'张'开头的数据有哪些
select*from exam_result where name like '张_';
分页查询
有时候数据量太大了,大量数据在一页里面显示, 查看者难免有时候会看不过来, 一方面系统压力也比较大,所以就设置了分页查询,这也是我们生活中经常看到的例子,如下:

对于一个表:
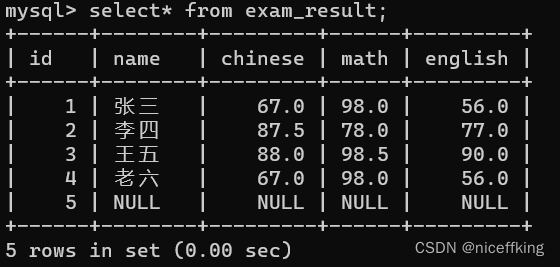
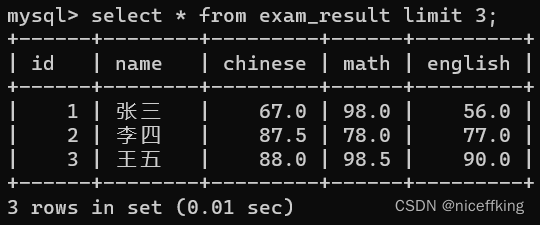
如果我只想看前三条,该怎么办?使用:
select * from exam_result limit 3;
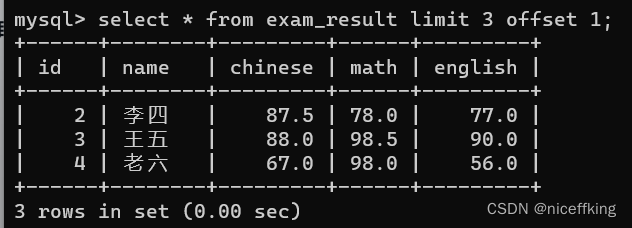
如果需要选定某几条,可以使用offset来改变偏移量,可以类比数组,第一行数据的下标为0,第二行的数据下标为1,.....以此类推:
select * from exam_result limit 3 offset 1;
这种写法等价于:
select * from exam_result limit 1,3;
改
存在表:
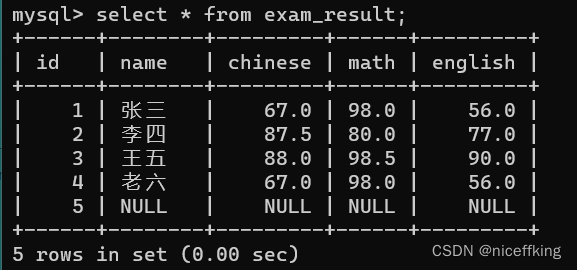
使用update关键字来修改:
update 表名 set value1 = xx, value2 = xx, value3 =xx, ... where 条件
例如:
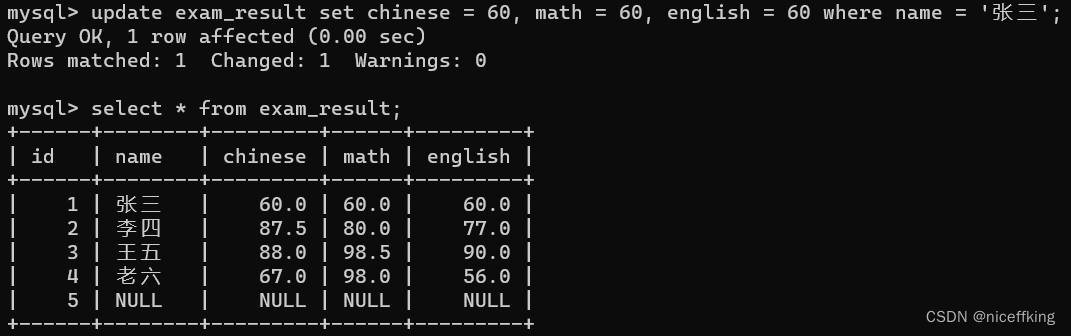
update exam_result set chinese = 60, math = 60, english = 60 where name = '张三';
结果如下:
但是如果加30之后超过了math的decimal(4,2)的范围,就会出现out of range 的异常
若对表中的chinses数据减半操作如下:
update exam_result set chinese = chinses / 2;
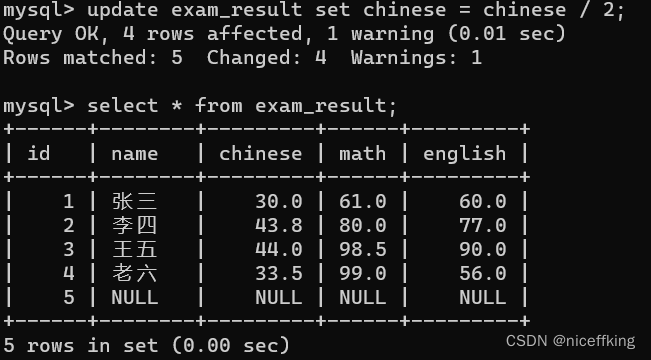
但是下面的执行结果出现了:

其中包含一个warnings
使用:show warnings; 来显示错误
结果如下:
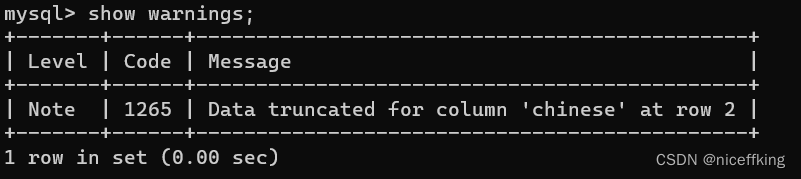
Message:Data truncated for column 'chinses' at row 2;
意为数据截断,小数点后面不够用了,只能截断.错误出现在第二行
正常来讲,60.5 / 2 的结果为30.25,但是由于decimal(3,1)只能保留小数点一位,而0.25有两位小数,所以发生了截断,其中的0.05被直接舍弃.
注意:update这个操作非常危险!!!
删
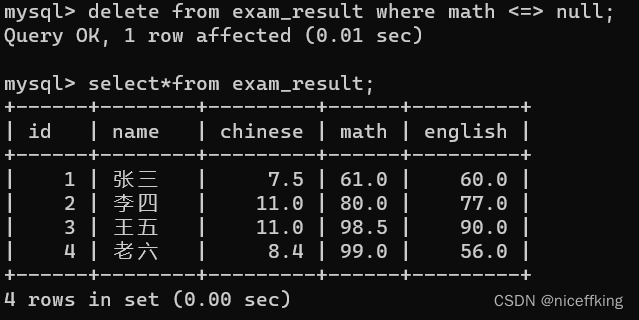
使用delete,意为删除,是按照行(记录)来删除的.
delete from 表名 where 条件;
例如:
delete from exam_result where math <=> null;
同时也可以搭配like(模糊匹配);
直接删除表中的所有数据:
delete from 表名;
这种情况表还存在,但是表中的数据已经全部清除了.

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









