



基于YOLO算法的自动驾驶物体检测
摘要
本文介绍了我们在物体检测方面所做的工作,旨在辅助自动驾驶车辆进行导航。检测通过最先进的YOLO模型实现,该模型在自定义数据集上进行了训练。本文的主要目标是突出在低成本计算资源上构建模型的过程。训练完成后,我们将该模型应用于视频数据以及网络摄像头。
关键词 —YOLO, 自定义训练, 计算机视觉, 自动驾驶汽车.
一、引言
自动驾驶领域的研究不断兴起,催生了多种尝试可视化汽车周围环境的技术。在自动驾驶中,对目标周围环境进行感知构建并全面理解其状况至关重要。这是计算机视觉在自动驾驶中最显著的应用之一,涉及分类、定位、检测等任务。本文仅讨论物体检测部分,这本身就是一个庞大的子任务,因为汽车需要知晓其导航路径中存在的障碍物。目前存在许多性能出色的物体检测器,但几乎所有的主流检测器都存在一定的不足之处。需要解决的主要问题包括:
- 准确性至关重要,因为在此参数上的妥协可能对相关利益方造成严重后果。
- 检测速度也需要得到充分重视,因为我们将在实时环境中运行该算法,因此实现高帧每秒的检测非常重要。
- 计算资源需求在实现精确的物体检测时也可能非常高。
- 检测速度也需要给予高度重视,因为我们将在视频数据上实施该模型,检测应是同时进行的,并且与正在运行的视频保持同步。
II. 文献综述
A. Over Feat
一个同时执行定位、检测和识别任务的卷积神经网络模型。在用于检测的最成功模型中,Over Feat 成功赢得了2013年ImageNet定位挑战赛。该模型具有八层深度,并依赖于一种在多个尺度上重叠框进行检测的方案,通过多次迭代并基于平均值生成检测结果。
B. VGG-16
为了在物体检测与分类领域超越Over Feat,研究人员设计了分别具有16层和19层的分层模型,即VGG 16和 VGG 19。这些模型凭借其极深的层数取得了卓越表现,并成功赢得了2014年的ImageNet挑战赛,成为计算机视觉领域的一项突破性成就。
C. Fast-RCNN
通过尝试理解更深层次模型的准确率,从而提升速度和检测效果。Fast-RCNN 所采用的方法是通过区域建议进行预测,并共享其计算,以加快训练过程和模型的预测时间。
D. YOLO(你只看一次)
YOLO模型的准确率并非最高,但它在计算机视觉领域是最具突破性的发现之一,因为其检测速度非常惊人。YOLO算法总共在80个不同类别上进行了训练,这需要大量的数据和极高的计算资源,而且该模型还达到了12层的较深深度。
E. 自定义训练的YOLO
为了降低YOLO模型的计算资源需求,并能够将其应用于我们关注的场景,我们使用以下类别的图像对模型进行了训练:汽车、人、卡车、公交车、树木、交通灯、交通标志、自行车。由于我们决定训练一个用于自动驾驶的目标检测器,因此我们基于上述类别训练了模型,并将该模型应用于从街道采集的视频片段以及网络摄像头画面,以获得模型在真实世界模拟中的最佳直观效果。
III. 物体检测
当我们使用卷积神经网络进行物体检测时,会采用一种称为滑动窗口方法的技术。在本项目中,我们通过截取所关注类别物体的裁剪后的图像,训练模型以检测道路上可能出现的物体。因此,该窗口以小步长在整个图像上滑动,并对它能够检测到的、且属于训练集中类别的物体返回0或1的标签。窗口的大小不断变化,并多次遍历整个图像。但这种方法存在一个巨大缺点,即由于需要在不同尺寸下多次处理每幅图像,导致计算成本非常高。使用单一的窗口尺寸可能导致无法完整捕捉全部信息,因此我们不能通过增大步长和窗口尺寸来加快处理每幅图像的速度。
在滑动窗口方法中,窗口需要在整个图像上运行卷积操作,这可能不是最高效的做法,因为图像的大部分区域并不包含我们关注的物体。为了解决这一缺陷,开发了一种名为R-CNN的算法,该算法仅在存在物体的区域上运行卷积操作,从而显著降低了模型的计算开销。他们生成区域建议的方式是通过运行分割算法来识别给定图像中可能存在的物体。当分割算法在图像中找到不同的斑点时,便会在这些斑点上运行分类器,并尝试用边界框将其包围,进而确定物体的类别。唯一的局限性在于,该过程往往过于缓慢,因为需要先在图像中提出候选区域,然后逐一对每个候选区域进行窗口扫描以分类物体。
为了改进这一点,开发了快速R-CNN,它基本上在第一步提出候选区域,然后同时对所有感兴趣区域运行卷积,从而显著加快了处理速度。之后出现了更快的R-CNN,其中不再使用传统的分割算法来确定感兴趣区域,而是采用卷积方法同时提出所有区域,随后再次运行卷积,同时对所有区域进行分类,使过程更加快速。但它仍然是一个两阶段过程,这意味着仍有改进空间,而单阶段检测器YOLO算法正是在此背景下应运而生,在检测物体的速度方面实现了巨大的飞跃。
IV. YOLO的工作原理
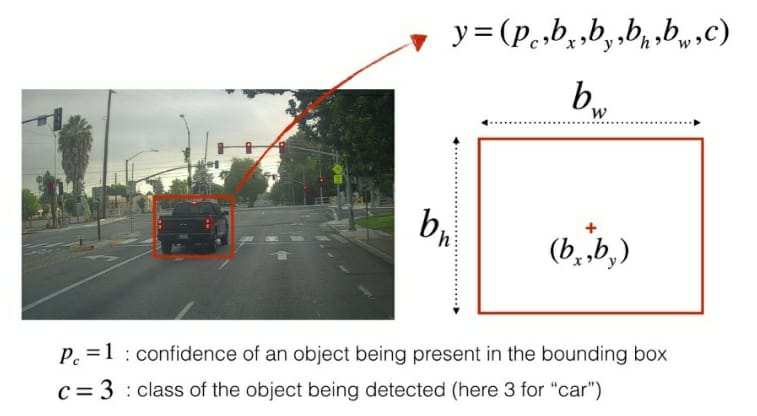
YOLO的速度明显高于其他任何算法。训练YOLO算法时,我们首先要准备一个包含所有我们关注的物体类别的训练集。我们不需要为背景类别训练模型。当将训练图像输入模型以创建自定义训练检测器时,整个过程在单阶段完成,而不像多阶段检测器那样分多个阶段。整个图像被划分为大小相等的网格单元,算法同时在所有单元上运行。我们可以调整在某一时刻生成的锚框数量,我们所考虑的值是2,这基本意味着每个网格单元上最多可以有2个锚框,如下方第一张图像所示,但这会导致画面过于杂乱,因为到处都能看到太多边界框。为解决此问题,我们应用非极大值抑制,以去除概率值较低的所有边界框。它会独立地为模型已训练的所有类别生成最终输出。如下方图像所示,第一张图像表示包含所有边界框的图像,第二张图像表示经过非极大值抑制处理后的图像。

对象编码表示下图中突出显示的元素,其中Pc表示对象的存在,后跟边界框的坐标
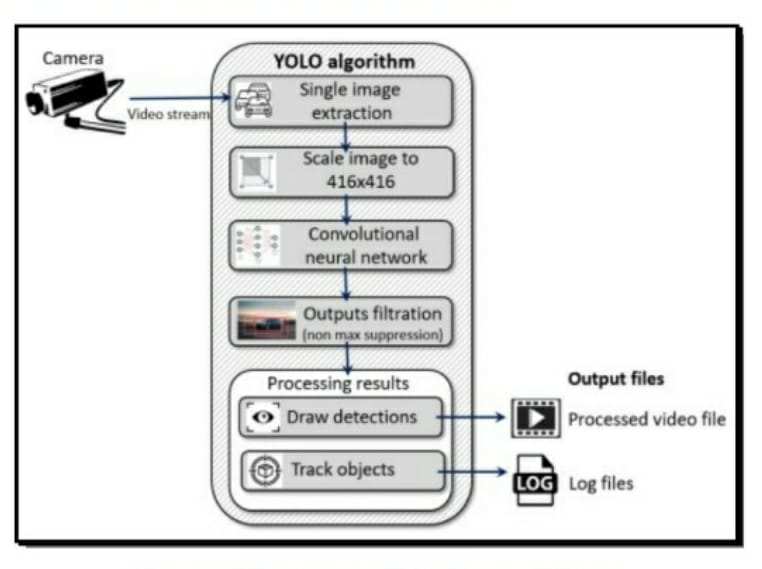
下图将通过流程图的形式展示所有步骤的工作流程。摄像头捕捉视频,从中提取图像并将其缩放至416*416。对图像帧进行卷积运算,输出结果通过非极大值抑制进行过滤,检测结果被绘制在图像上,最终得到包含所有检测的处理后视频文件。
V. 方法论
a) 设置 OIDv4工具包 以准备数据集。
b) 下载类别图像——汽车、人、卡车、公交车、树木、交通灯、交通标志和自行车,以及对应的标签。
c) 生成 YOLO标注。
d) 上传图像和标注的压缩文件后,在谷歌云盘上设置所需的目录。
e) 准备在谷歌colab上训练模型的代码。
f) 将所有权重存储在备份文件夹中。
g) 在本地机器上下载权重。
h) 在本地机器上配置 darknet、CMake、微软Visual Studio、OpenCV。
i) 在视频数据和网络摄像头运行模型。
j) 将检测结果存储在本地机器上。
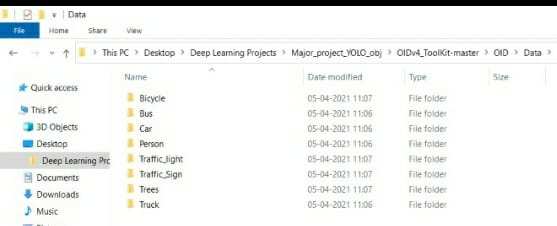
VI. 数据集
该数据集是从包含600个类别的谷歌开放图像数据集中提取的。由于我们希望开展自动驾驶项目,因此仅选择在道路上可能出现的物体类别进行模型训练。最终选定的类别如下:汽车、人、卡车、公交车、树木、交通灯、交通标志、自行车。
VII. 自定义训练
为了开始自定义训练,我们首先设置环境以获取模型将要训练的数据。在下载OIDv4工具包后,我们获取我们所关注类别的图像。这些数据会连同对应的标签一并获取,因此需要将其转换为YOLO可理解语言,即标注。该标注包含每个图像中相应类别及其对象坐标的独立编码。接下来第一步是将整个数据压缩,然后上传到与云端笔记本关联的云盘,模型将在该云端笔记本中进行训练。
根据任务的不同,会在云盘上创建相应的嵌套文件夹。我们创建一个文件夹,其中包含模型训练所需的所有类别名称。我们编写一个Python脚本用于生成test.py和train.py。然后创建一个备份文件夹,用于在模型训练过程中持续保存所有的权重。有时在训练过程中,内核可能会因某些原因停止,导致到该时间点为止的所有已训练权重丢失。因此,我们会在每次完成1000th迭代后,将权重保存到单独的文件夹中。这样,如果训练内核因某种原因中断,或者因为我们耗尽了分配的时间而被踢出内核,我们可以利用已保存的权重从上次停止的精确位置立即恢复训练。
完成所有目录结构的创建后,我们将Colab笔记本与云盘连接,以便在其中训练模型。我们首先克隆了包含YOLO算法的Darknet仓库,并为darknet配置完整的环境,安装所有必需的库。下一步是测试算法是否正常运行,为此我们在安装OpenCV后下载YOLOv3权重,并在测试图像上运行它。
下一步是开始模型的训练,最初需要我们将压缩文件复制到虚拟机并在内核运行时解压。现在我们着手将所有必要的超参数设置为最优值。对于超参数调优,我们倾向于将细分数设置为16,尽管这需要通过试错法进行尝试。将所有图像的大小缩放至416*416,批量大小设置为64。最大批次数的值基于公式类别数量乘以2000来选择,因此在本例中为16000。我们在整个过程中选择了不同类型的激活函数,如Leaky ReLU、线性等。
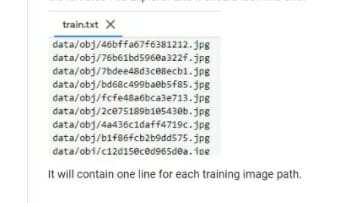
现在我们通过编写Python脚本为所有图像生成文本文件。我们分别表示训练集中的每幅图像。
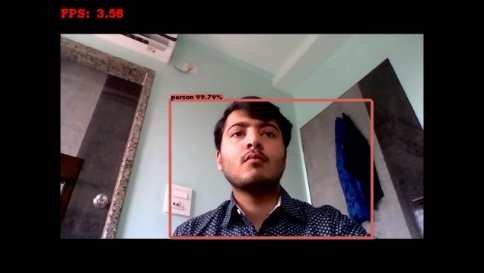
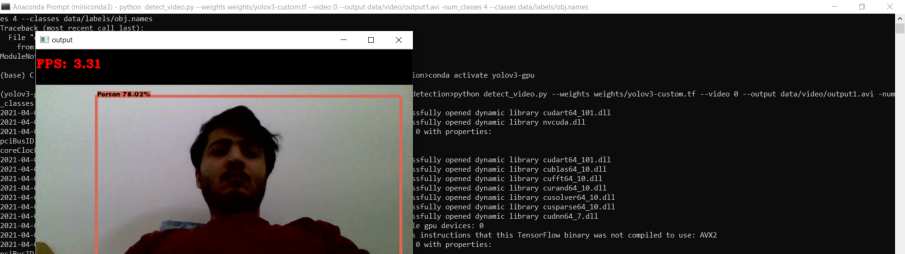
现在我们开始模型的训练,并让其训练6000次迭代。训练完成后,我们生成关于图像的迭代次数图表。为了完成项目的主要目标,我们需要在真实世界视频帧数据以及网络摄像头中运行已训练的权重模型。我们首先下载NVIDIA GPU驱动程序以及CMake,然后在本地机器上安装OpenCV。在本地机器上设置完整的darknet环境后,我们从云盘下载自定义训练权重,然后将权重转换为TensorFlow可理解的形式。以下是自定义训练的YOLO目标检测模型在视频帧数据和网络摄像头视频上的输出截图。第一张图像显示了在繁忙街道拍摄的视频上运行模型的截图,第二张图像显示了在网络摄像头上运行自定义模型的情况。
VIII. 结果
视频数据以每秒4.06帧的速度传输,而网络摄像头的运行速度为每秒3.31帧,如下方所示。

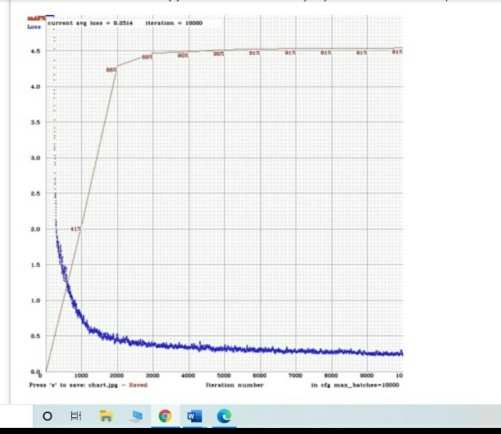
该图表基本展示了模型训练完成后所获得的最终结果。图表绘制了损失函数与迭代次数之间的关系。在第3000th次迭代后,损失不再下降,因此我们通过引入早停法在此处停止训练,以防止模型发生过拟合。
网络摄像头的检测帧率达到78.21%,检测速度为3.31 FPS。在上述类别上运行模型后,测得的mAP值接近74%。
IX. 结论
自定义训练的YOLO模型已在上述类别汽车、人、卡车、公交车、树木、交通灯、交通标志和自行车上进行训练,并成功在本地机器上的视频帧中实现。我们意识到在此处可以进行的改进包括提高帧每秒值和提升准确性。图像数据以93毫秒的速度被检测。


















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









