



为什么传统规则防护失效了?🤔 目前,大多数 Web 应用防火墙(WAF)依赖规则匹配来识别和阻断攻击流量。然而,随着 Web 攻击的低成本、复杂多样的手段和频繁爆发的高危漏洞,管理人员不得不频繁调整防护规则,以保障业务的安全和稳定性。即使如此,误报和漏报问题仍然频发,影响业务运行,甚至可能导致 Web 服务被攻破。
传统规则匹配的根本问题在于其先天不足。根据乔姆斯基文法体系,编写规则所用的正则文法属于 3 型文法,而构造攻击 Payload 的程序语言则是 2 型文法。二者在表达能力上存在差距,导致防护效果不尽如人意。

雷池:突破传统规则的 WAF 🌟 SafeLine(中文名 “雷池”)是一款简单易用且效果显著的 Web 应用防火墙。它通过监控和过滤 Web 应用与互联网之间的 HTTP 流量,保护 Web 服务免受多种攻击,如 SQL 注入、XSS、代码注入等。
雷池的核心在于其语义分析算法,它不再依赖简单的特征匹配,而是深入理解流量中的用户输入,识别潜在攻击行为。例如,在 SQL 注入场景中,雷池不仅会检测流量中是否存在符合语法的 SQL 语句,还会进一步分析其意图,判断是否包含恶意行为。
通过这样的深度分析,雷池不仅能有效阻断恶意流量,还能减少误报,确保业务正常运行。
雷池通过阻断流向 Web 服务的恶意 HTTP 流量来保护 Web 服务。雷池作为反向代理接入网络,通过在 Web 服务前部署雷池,可在 Web 服务和互联网之间设置一道屏障。
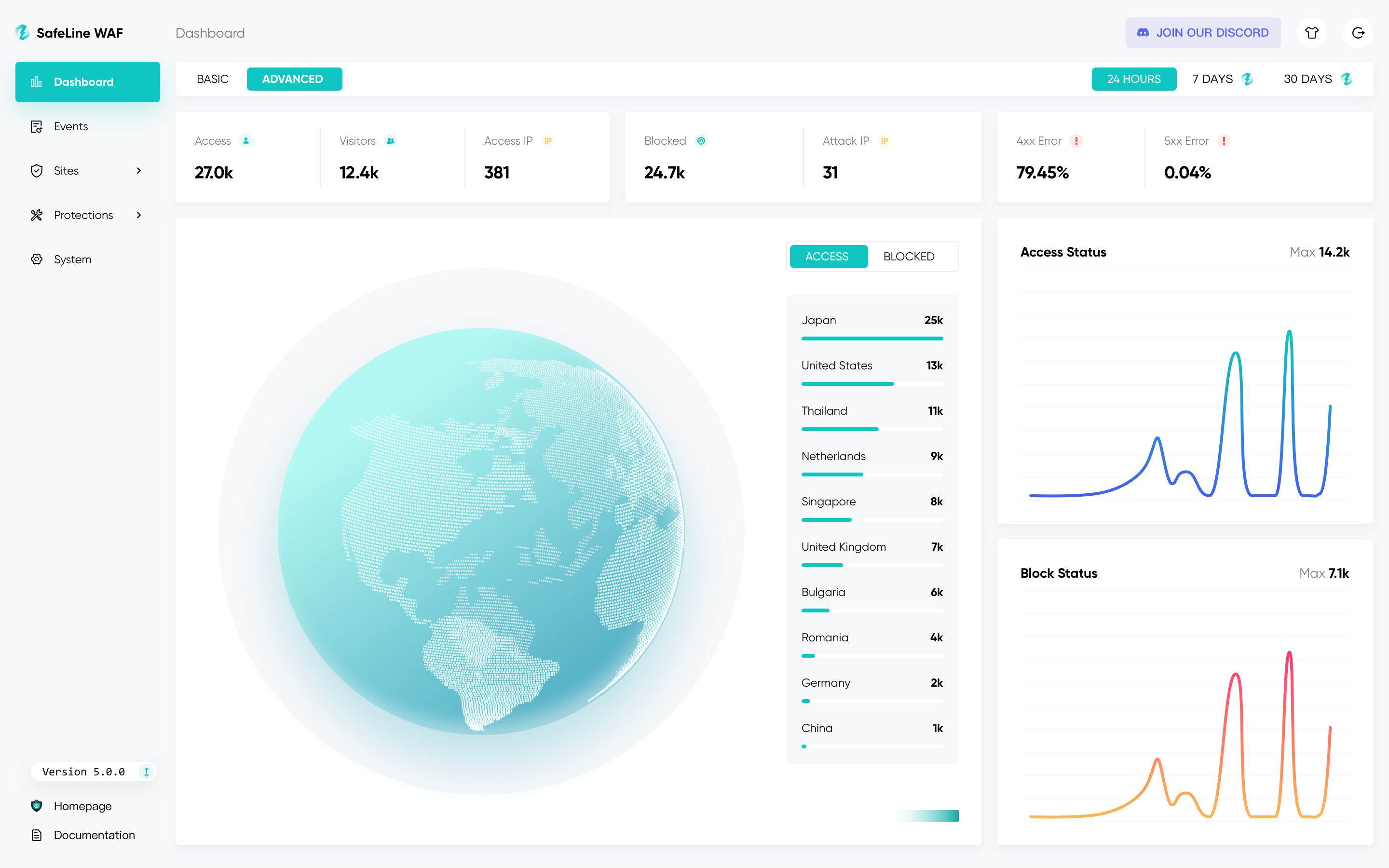
雷池的核心功能如下:
防护 Web 攻击 防爬虫, 防扫描 前端代码动态加密 基于源 IP 的访问速率限制 HTTP 访问控制
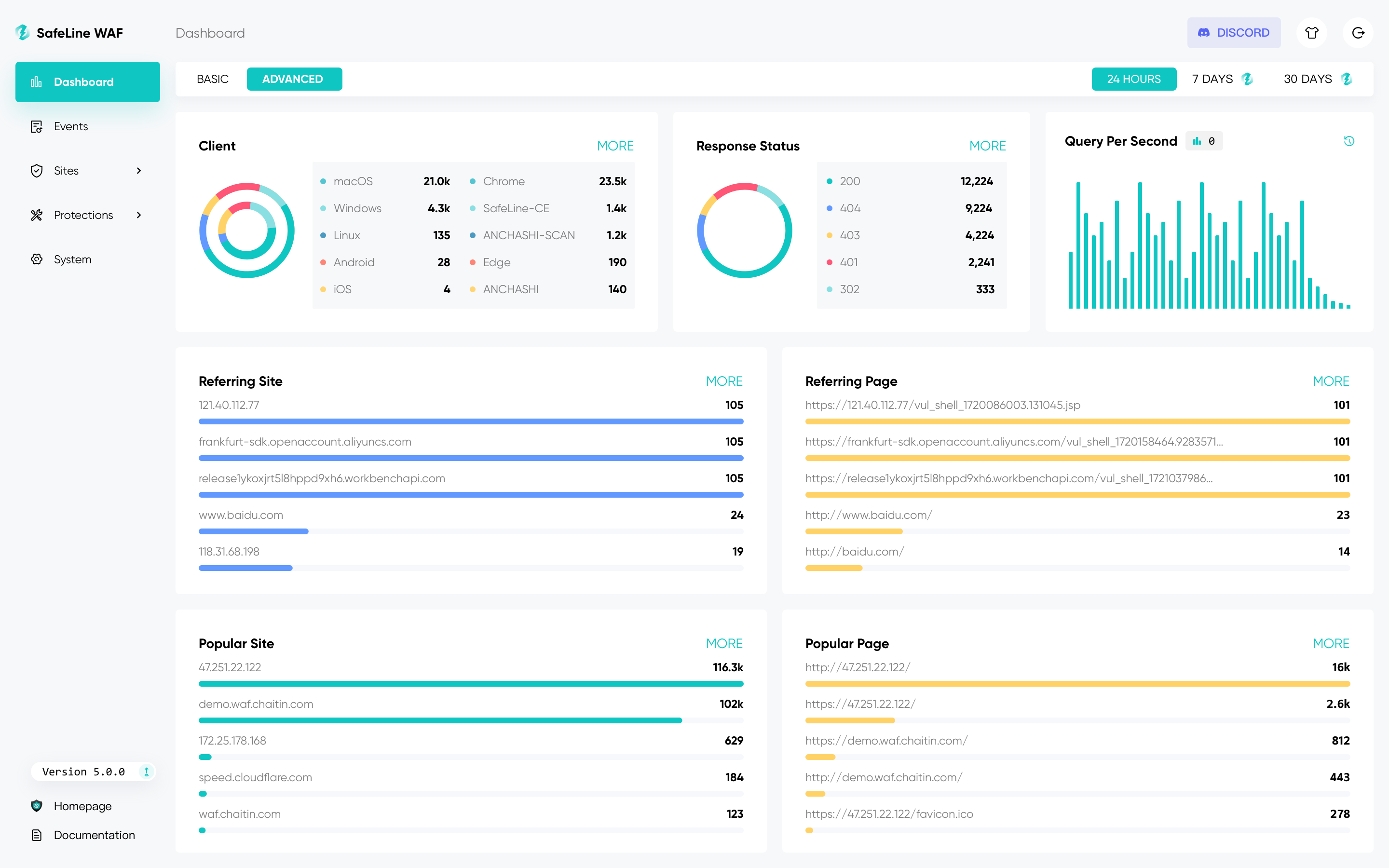
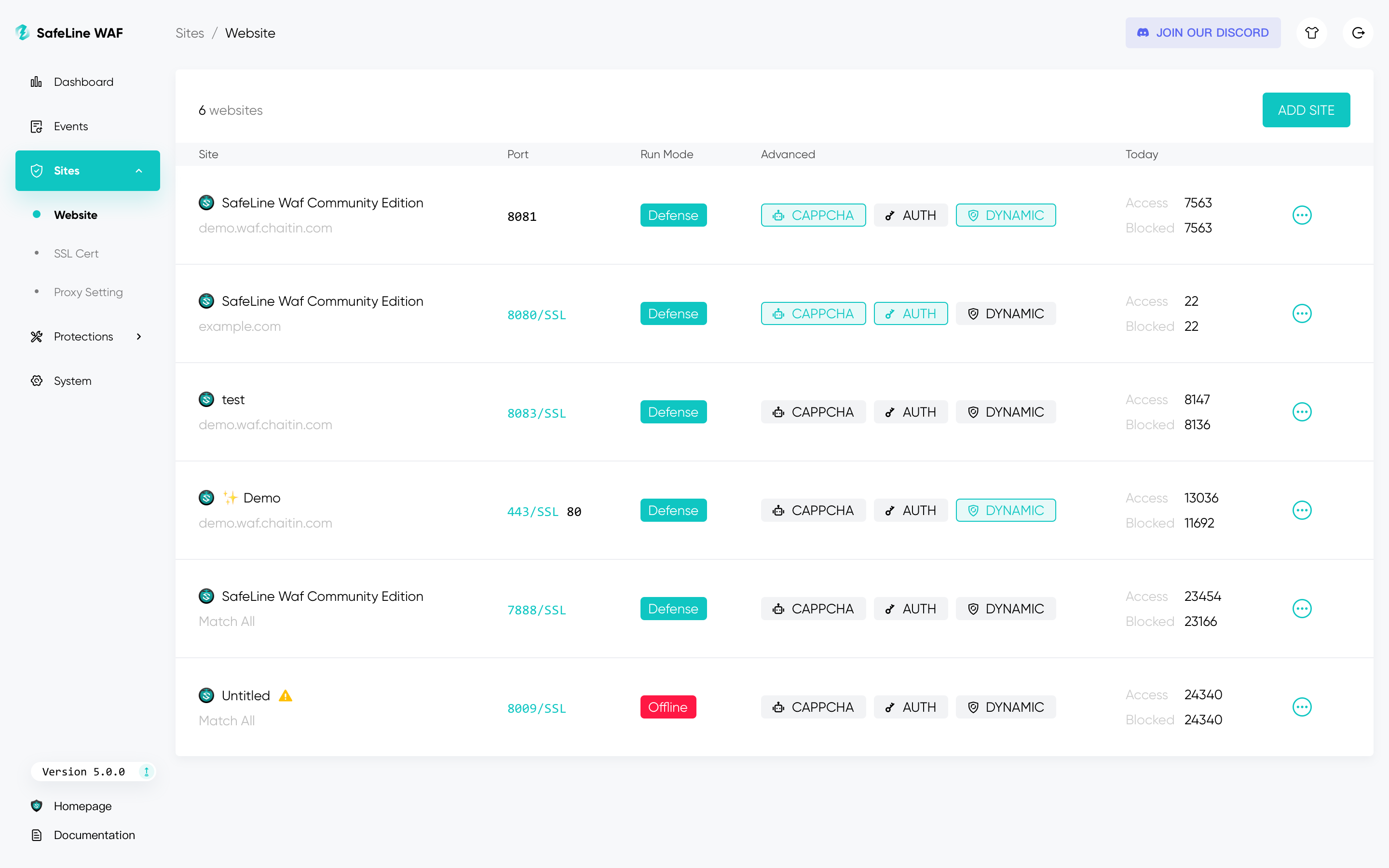

















 2576
2576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









