




嵌入模型的作用
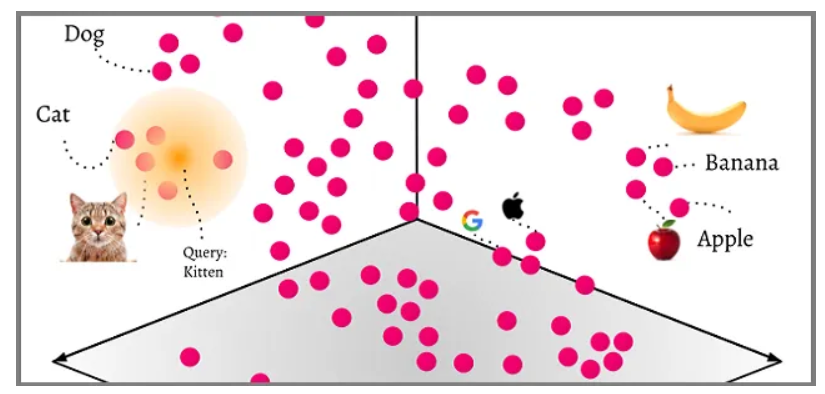
嵌入模型不仅能够编码词汇本身的含义,还能捕捉词与词之间、句子与句子之间的关联关系。这意味着在向量空间中,语义相似的词会拥有相似的位置,比如:
- "queen"和"king"在向量空间中距离相近
- "man"和"woman"在向量空间中距离相近
- 搜索"男人"可能会得到"女人"、“男孩”、"丈夫"等语义相近的词
这种语义相似性搜索是基于向量空间中的距离计算,而非简单的关键词匹配,能够更好地理解自然语言的语义关系。
几乎每一个大模型公司都开发了自己的嵌入模型,并且还在不断迭代。比如
OpenAI的嵌入模型经历了多次迭代:
-
2022年版本text-embedding-ada-002:
- 默认维度为1536
- 上下文长度8192
- 不支持直接调整维度,需要通过L2标准化等方法进行降维
-
最新版本(text-embedding-3系列)
text-embedding-3-small:更小更快的模型
text-embedding-3-large:性能最好的模型- 可以控制输出向量的维度
- text-embedding-3-small默认维度为1536(常用的维度选择:512或256,能显著减少计算量的同时保留足够的语义信息)
- text-embedding-3-large默认维度为3072(最高维度)
- 成本更低
- 支持中文
Embedding如何选择
业界公认批判指标是Huggingface推出的 CMTEB(Massive Text Embedding Benchmark)。
该指标体现Embedding模型在分类(Classification)、聚类(Clustering)、对分类(Pair Classification)、重排序(Reranking)、检索(Retrieval)等任务的表现
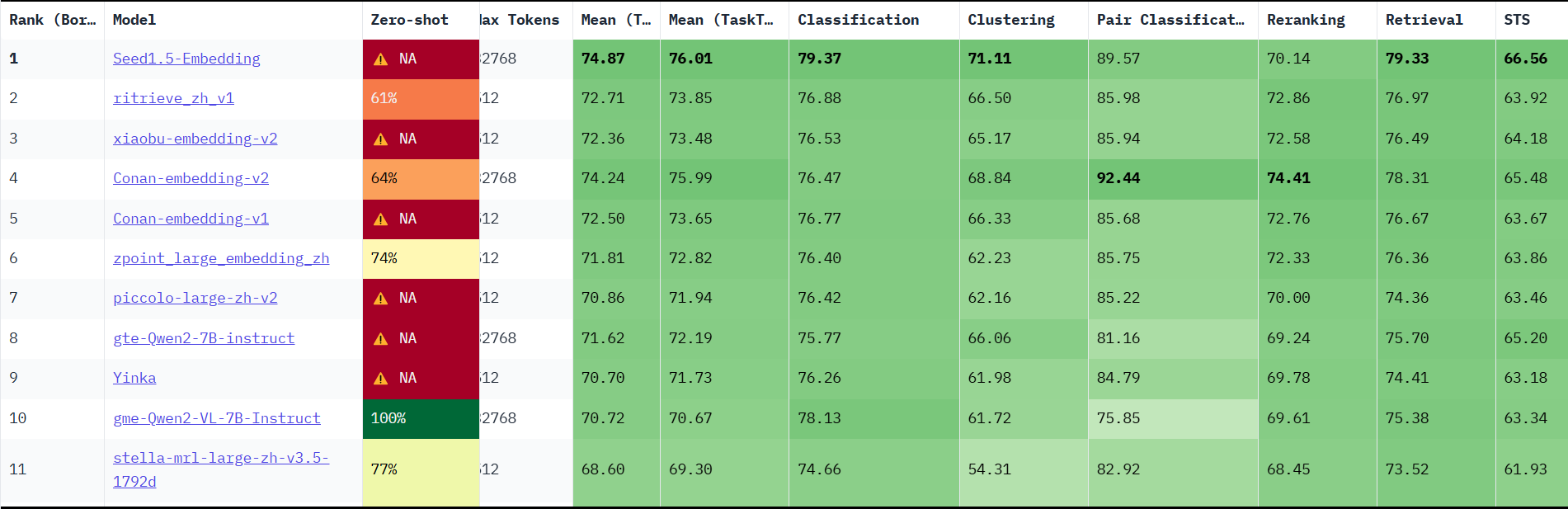
中文RAG如何选择适合的Embedding模型
目前约由200个模型,我们需要从中选择适合自己的。可以从以下方法作为参考
-
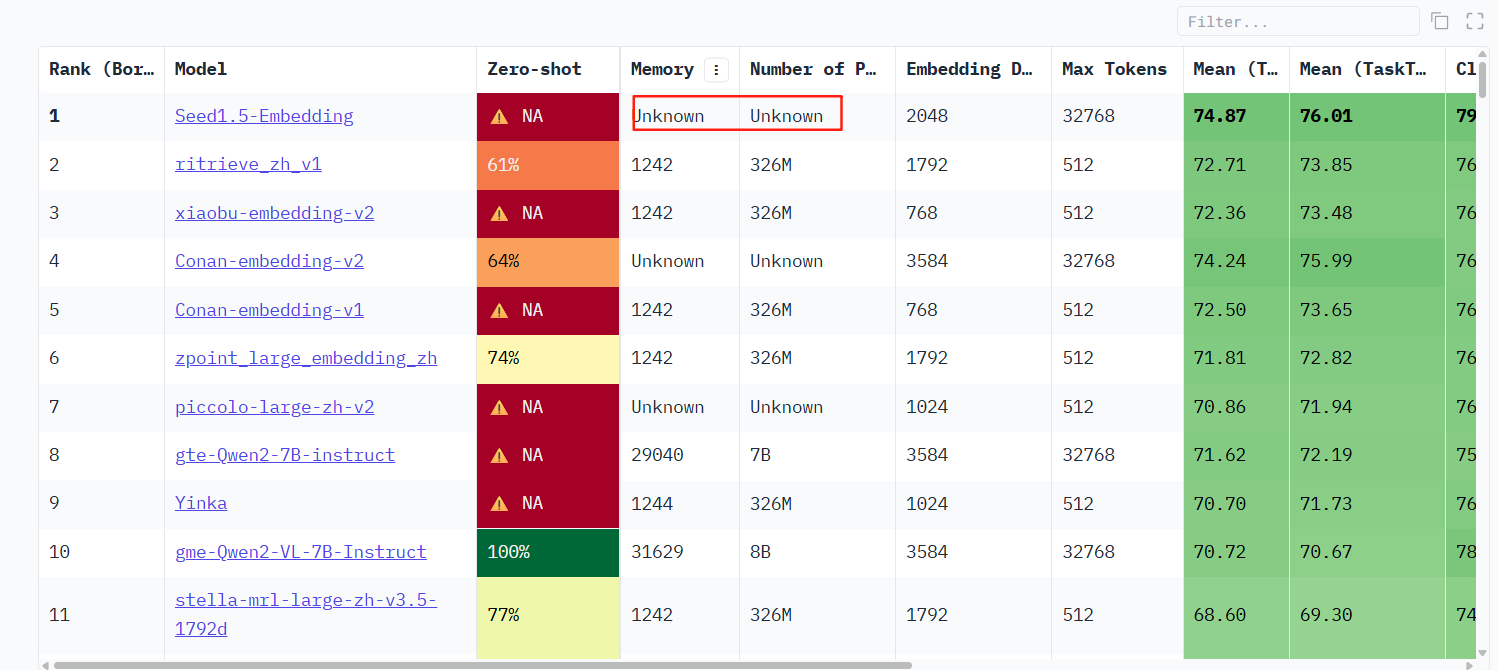
选开源的模型,如果没开源的我们没法使用。查看它的参数如果评估是未知就是没开源
-
筛选中文版本的,即关注C-MTEB Retrieval指标。排序看看。目前可以筛选出
-
RAG一般选embeding 维度>512的
-
评分高的也不一定效果好,所以我们可以快速用代码测试自己文本,从而比较相似度
-
下载前顺便看看该embedding当月的下载量
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
model_name = 'BAAI/bge-small-zh'
model = SentenceTransformer(model_name)
sentences = [
"我喜欢吃苹果",
"我爱吃水果",
"今天天气很好",
"明天会下雨",
"人工智能很有趣",
"机器学习是AI的分支",
"猫咪很可爱",
"小狗很活泼"
]
embeddings = model.encode(sentences)
print(f"✅ Embedding生成完成!")
print(f"📊 向量维度: {embeddings.shape}")
print(f"📝 测试句子数量: {len(sentences)}")
similarity_matrix = cosine_similarity(embeddings)
# 打印相似度矩阵
print("\n📈 句子间相似度矩阵:")
for i, sentence1 in enumerate(sentences):
for j, sentence2 in enumerate(sentences):
if i < j: # 只打印上三角,避免重复
similarity = similarity_matrix[i][j]
print(f"'{sentence1}' 和 '{sentence2}': {similarity:.3f}")


















 7288
7288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











