







目录
一、程序地址空间图

在学习C++的内存管理的时候,我们看到过这样一张图,我们先来回顾一下
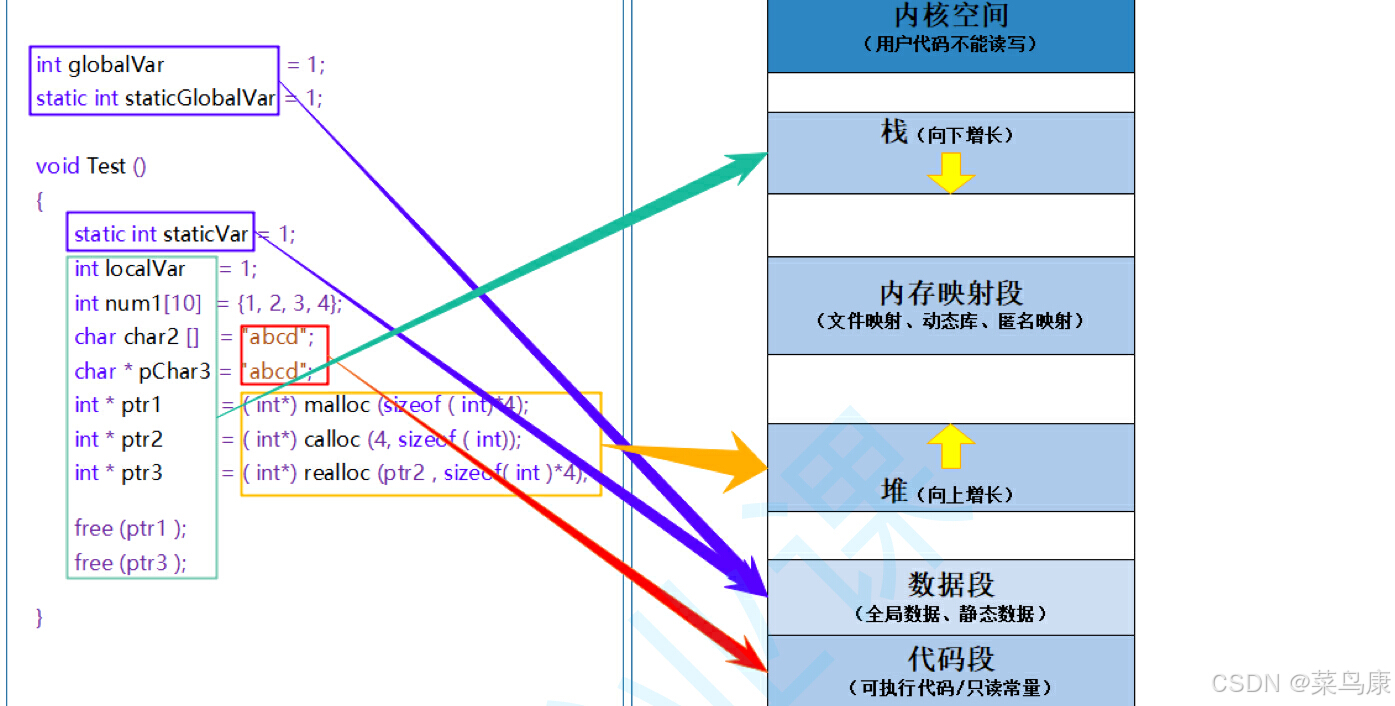
- 栈,又叫堆栈,放的是非静态局部变量、函数参数、返回值等,栈是向下增长的,且栈是一段线性空间,遵从先进后出的规则,小内存,自动化,可能会溢出。我们通常会在函数栈帧中创建很多变量,我们称这个变量具有临时性,这个变量即为局部变量,存于栈上。
- 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库,用户可以使用系统接口创建共享内存,作进程间通(后面学到通信的时候会讲到) 。
- 堆用于程序运行时动态内存分配,我们的手动开辟空间都是在这一部分上的。堆是向上增长的,是一段非连续的空间,特点是大内存,手工分配管理、申请的大小是随意的,但是可能会导致内存泄漏问题。
- 在堆区上开辟空间后会返回一个指针,这个指针是指向堆区上开辟的内存块的,其中存放的是从堆区上开辟的空间,但是这个指针本身是在函数中定义的,因此属于一个局部变量,存在栈上。
- 数据段存储的是全局数据和静态数据。
- 代码段存放的是可执行的代码、只读常量。
- 数据段和代码段属于编译时编译器分配的空间(静态存储区域),其他的属于运行时系统分配的空间(动态存储区域)。
- 内核空间用户后面会讲到。
- 命令行参数和环境变量:命令行参数指的是在命令行上敲入的一些参数,main函数的第二个参数就是负责获取命令行参数的,比如选项和命令等
环境变量:main函数的第三个函数就是负责接收环境变量的,在上篇文章(环境变量)中已经着重进行讲解。
二、进程地址空间
1、前言
接下来,我们看这么一个现象:
我们实现一个代码让父子进程打印同一代码段里的同一数据
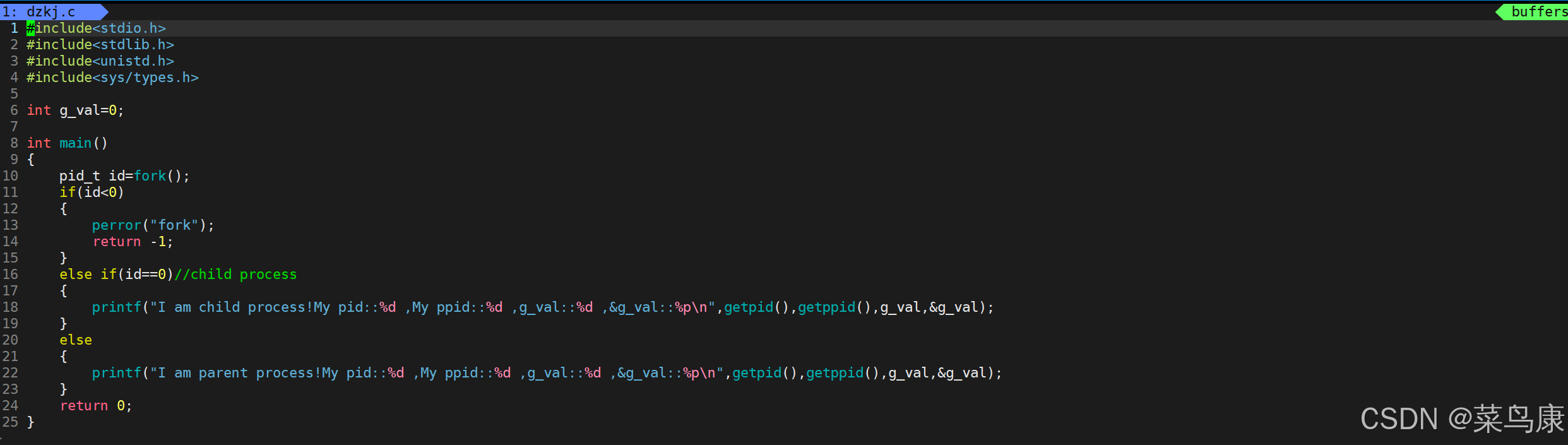

可以看到父子进程打印的该数据的地址都是相同的, 这无可厚非,因为我们之前在进程那一节说到过,子进程和父进程的代码和数据(只要任意一方不修改数据)是共享的。
现在对这个代码稍稍做一个改动,在子进程片段中对数据进行修改如下
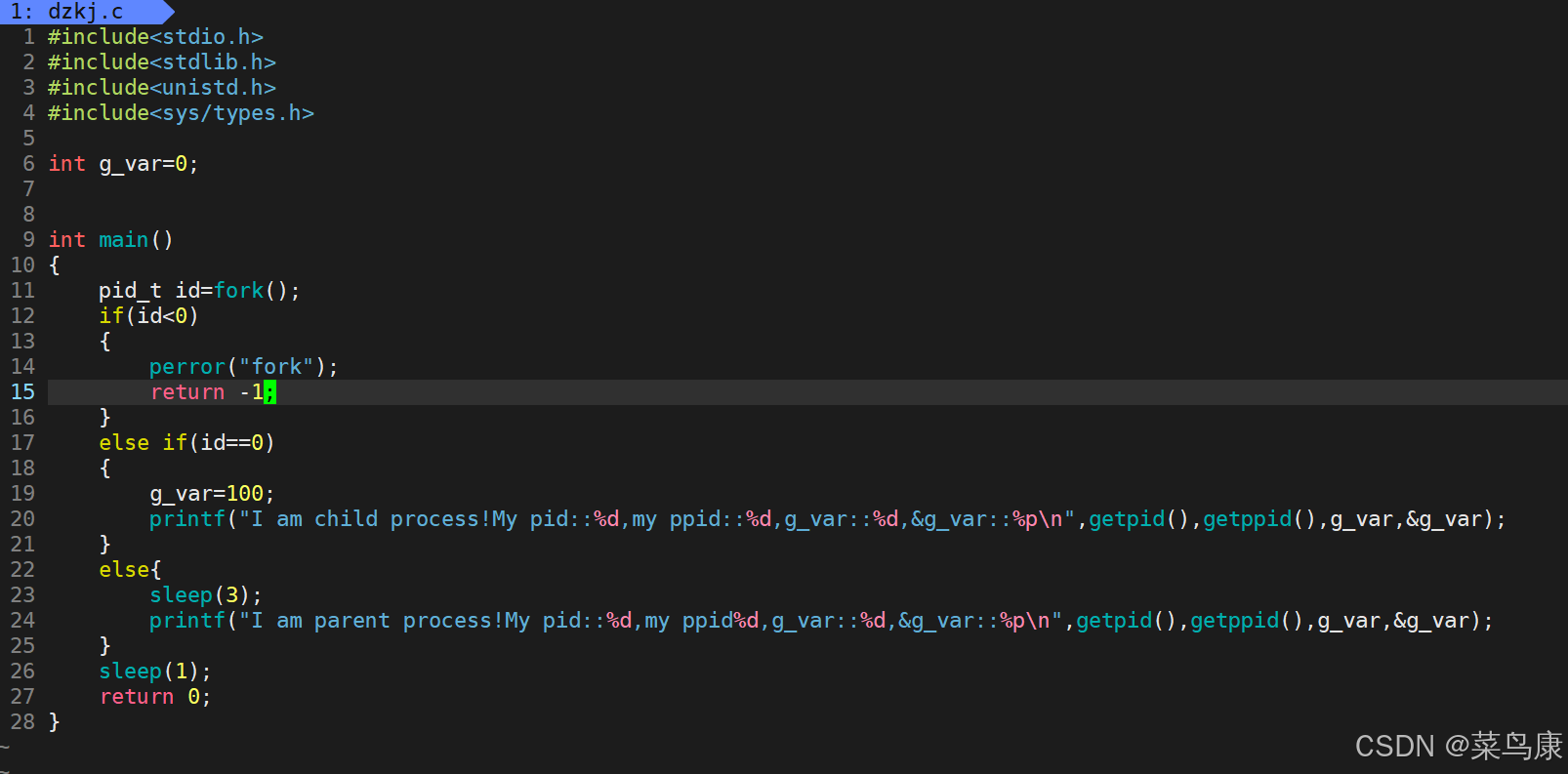

可以看到实验结果是,尽管子进程对数据进行了修改,但是父子进程对不同的数据打印出来的地址却是一样的,这个现象我们在进程初见面那一节也讲到过,因为如果父子进程有一方对数据进行修改时,其便以写时拷贝的方式单独存储一份副本,但是尽管它“单独”保存了一份副本,这个副本怎么还跟原版的地址是一样的呢?这就要提到下面我们要说的进程地址空间的概念了。
2、虚拟地址空间
由上面的现象我们肯定能推断出这两份数据的地址一定不会是真实的物理地址(物理地址独一份),它是虚拟地址空间,所以我们在C/C++中看到的所有的地址都是虚拟地址,物理地址用户一概看不到,是由操作系统统一管理的。
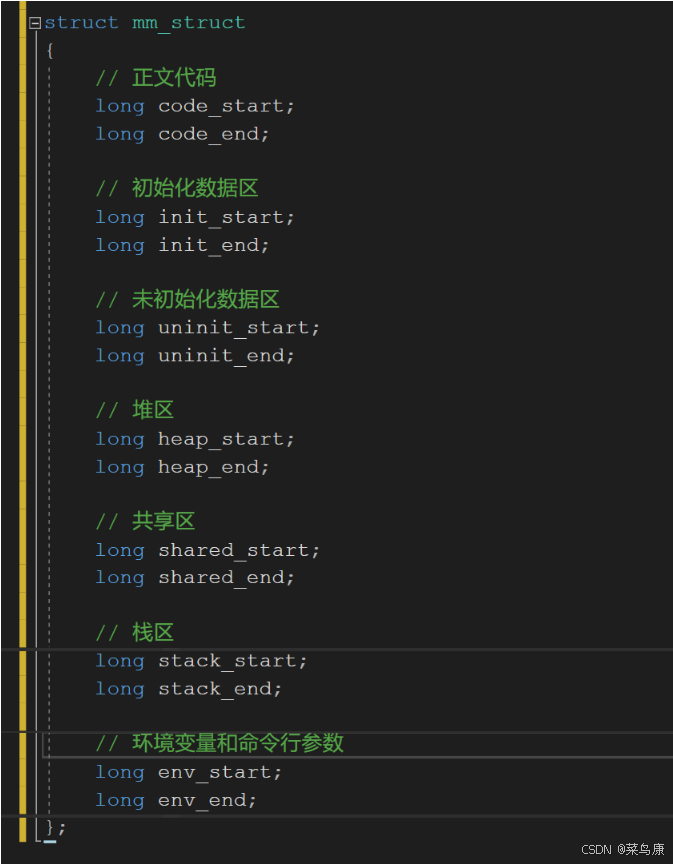
- 在每一个进程建立的时候,操作系统不仅会为进程创建一个PCB,同时还会为每一个进程创建一个进程地址空间,即每一个进程都会有自己独立的进程地址空间,那么问题就来了,系统中那么多进程,这样系统中的进程地址空间就会非常多,那么操作系统就要对这些空间进行管理和操作,于是系统就为进程地址空间创建了一个mm_struct,其中对虚拟地址的每个区域都进行了划分,每一个进程都是相对独立互不影响的,每一个进程的PCB和mm_struct都是相互独立的,这就是进程的独立性。
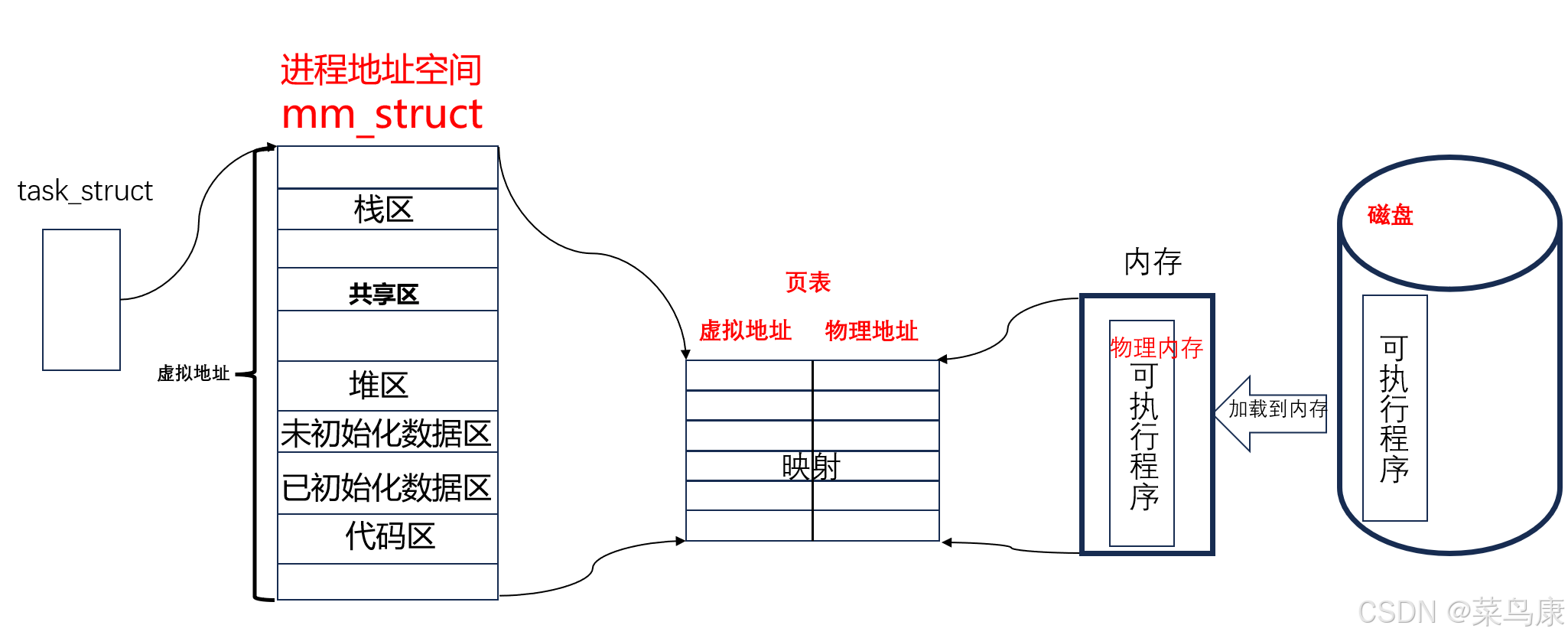
- task_struct中描述着进程的诸多属性,其中也包含着该进程的程序地址空间。
- 进程地址空间的结构和前边的程序地址空间结构是一样的。
- 我们可以发现,每一个区域都是由对应的start和end来维护的,也就是说,如果我们向改变对应区域的大小,我们可以通过设置对应区域的start和end进行修改即可,在每一个区域的start和end中会包含很多的地址,这个地址就是所谓的虚拟地址,不是物理地址,物理地址是存在于内存中的,不是存在进程地址空间的。
- 内存中加载的进程的代码和数据, 会通过一个叫页表的东西映射到虚拟地址空间中。
- 页表是进程地址空间和物理内存之间存在的一个工具,其作用就是负责利用其中虚拟地址和物理地址的映射关系实现虚拟地址和物理地址之间的相互转化,也就是说有了虚拟地址和页表,我就可以找到对应的物理地址。
- 磁盘是代码被编译形成可执行程序之后未加载到内存存在的地方,属于外设。
3、程序从磁盘到内存
还是看我们上面的那张图,我们可执行程序的数据和代码是怎么加载到内存中的,CPU又是怎么读取它们的。首先我们需要明确几个点:
- 在磁盘中的时候,我们写好一个程序,运行它,这时候源文件会经历编译器预处理、编译、汇编、链接过程以形成可执行程序,这个时候,在可执行程序还没有加载到内存的时候,其就已经有了地址了,这个地址我们在磁盘上称为逻辑地址(其实在汇编的时候就有了)。
- 地址空间那一套规则不止在操作系统遵守,编译器也在遵守。编译器在编译我们的代码的时候就是按照虚拟地址空间的方式对我们的代码和数据进行编址的,也就是程序地址空间的方法。其实只有堆或者栈在编译的时候是不给空间的,其他的数据什么的都给好了空间。
- 逻辑地址是我们程序内部使用的地址(即函数内部在调用其他函数的时候),当程序加载到内存的时候,其就天然具备了一个外部的物理地址。
接下来我们看他是怎么加载到内存的
- 程序载入内存后,对应的代码在内存中就会确定地址,但是程序中代码的相对位置是保持不变的,所以载入内存之后,在内存中确定的地址都需要考虑偏移量的问题,这个偏移量与内存和代码在程序中的位置(逻辑地址)有关系,此时确定出的地址就是虚拟地址。
- 通过上述形成的虚拟地址映射出对应的物理地址之后就可以形成页表,页表的作用就是方便通过虚拟地址找到对应的物理地址。
例子
当程序加载到内存的时候,其物理地址就会填进页表的物理地址那一半。
接着CPU就开始读取指令,假设就从main函数开始(能将程序加载到内存当然就能读取它),且会读到main函数代码所占的字节大小,于是在mm_struct中就会移动start和end指针初始化同样大小一块区域存放main函数代码,此时main函数的虚拟地址就创建好了,于是页表中的虚拟地址和物理地址就可以形成映射关系,接着假设需要调用一个fun函数,这时候就根据逻辑地址从程序内部读到fun函数,接着和main函数的过程一样,最后形成对应关系。
三、父子进程数据和代码的共享关系
下面我们来深挖之前讨论的问题,为什么尽管父子进程有一方进行写入数据时,不同的数据打印出来的地址却一摸一样的。这里的地址就是虚拟地址。
1、写时拷贝
在子进程被创建的时候,系统就会为它创建一个task_struct,当然这个PCB里面也包含了独属于子进程的进程地址空间mm_struct,在父子进程都未修改数据时, 父子进程的数据的物理地址也是共享的, 也就是说在父子进程都未修改数据的时候, 虽然父子进程都有属于自己的进程地址空间, 但内存中实际只加载了一份代码与数据。
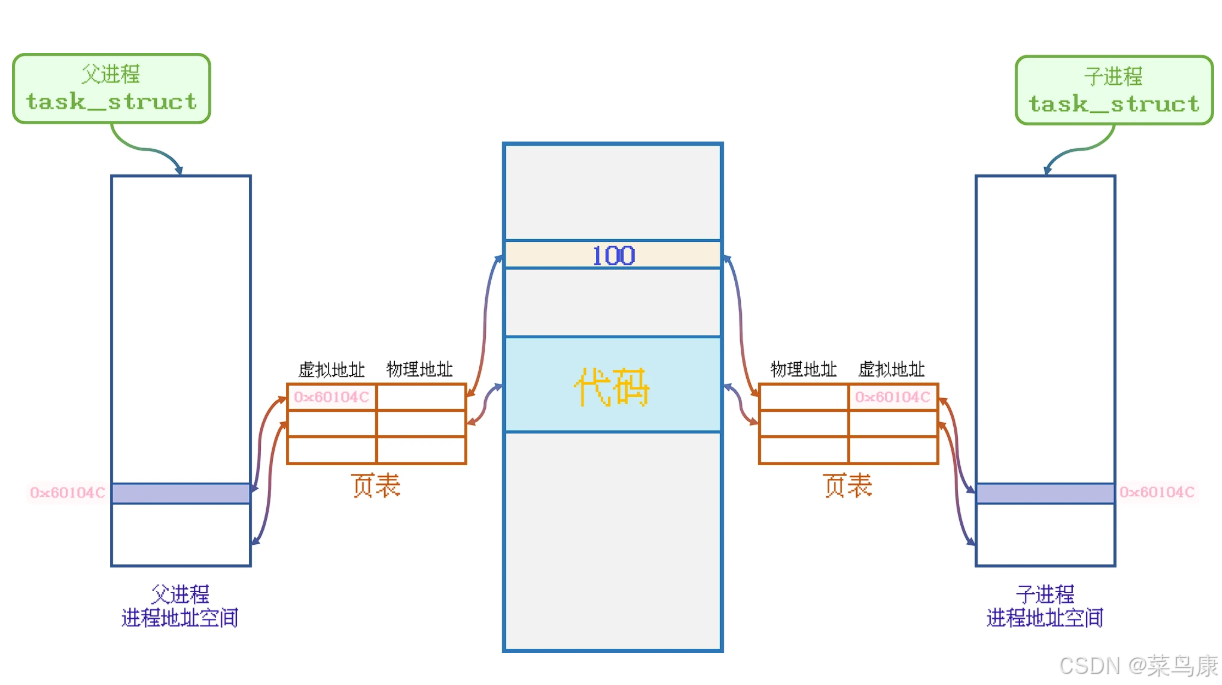
当子进程继续执行代码, 修改了0x60104C地址所存储的值时, 操作系统就会在在物理空间中申请一个新的地址供子进程存储数据使用, 同时修改子进程页表内容:
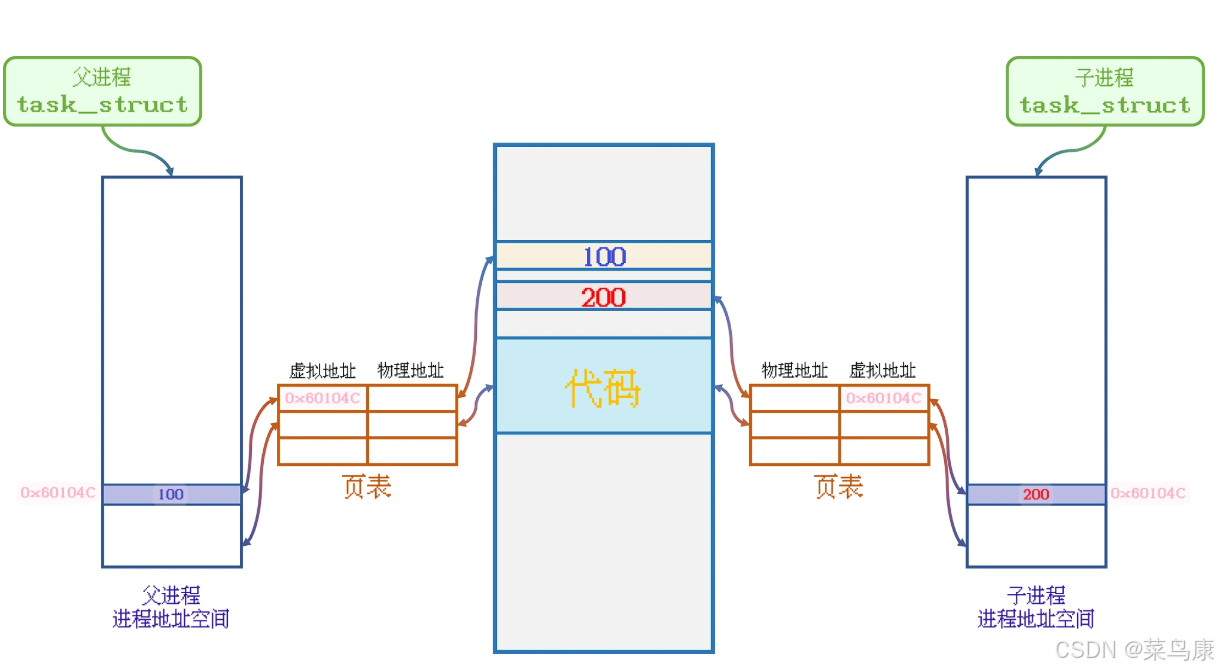
2、为什么需要写时拷贝
- 在子进程被创建出来的时候, 就将父进程的所有代码和数据拷贝一份, 当然可行.但是, 如果父子进程所执行的代码从头到尾都没有对数据进行修改的操作, 或者只修改了非常小的一部分数据, 那为什么要全部拷贝一份呢?在这种情况下是否存在空间浪费的嫌疑?
- 创建子进程的时候, 关于数据的拷贝最理想的情况是什么? 一定是在创建子进程的时候, 就只将父子进程需要修改的数据拷贝一份.但是, 这样的做法从技术的角度来讲, 是很复杂的, 至少相对于写时拷贝来讲, 是非常复杂的。
- 如果在创建子进程的时候, 就执行数据和代码的拷贝工作, 那是否给fork()这个原本只是为了创建子进程而诞生的系统调用增加了一定的成本?无论是从内存还是从时间的成本上. 毕竟fork()在执行结束的时候子进程已经创建完成了, 也就是说在创建子进程的时候执行拷贝工作, 其实一定是交给fork()来做的.
Tips:父子进程的写时拷贝工作是由操作系统的内存管理模块完成的
四、进程地址空间存在的意义
- 保护内存:如果没有进程地址空间,那么就是task_struct直接对物理地址进行访问,那么如果有时出现代码写错,出现访问越界,或者野指针,或者指针指向操作系统的代码,那么当我们修改的时候,就会对其他代码造成影响,同时也会会导致物理内存的利用率低下,且访问控制薄弱。
- 实现功能模块的解耦:当我们向系统申请一块空间,比如使用malloc函数来申请空间的时候,系统不会马上去实际的物理内存中申请,只会在进程地址空间中的堆区上将对应的区域放大,当系统检测到此时需要访问到那块内存的时候,系统才会马上向内存申请对应空间,这样就大大地增大了内存资源的利用率。
简化进程的设计与实现:程序编译时确定的地址都是虚拟地址,但是访问的时候操作系统会将这个虚拟地址在页表中映射得到物理内存地址,进而访问物理内存区域,这样的话,每个进程都有自己独立的虚拟地址,跟其他进程互不影响,但是数据可以在物理内存任意位置存储,因为可以通过页表映射访问到实际物理存储的位置,实现了数据在物理内存上的离散存储,提高了内存利用率,并且可以在页表中对地址访问加以权限访问,提高了内存访问控制,程序运行时,其中中的数据和指令被打散在物理内存中存储,同时在页表中记录对应数据虚拟地址和物理地址的映射关系,以便于进程在虚拟地址访问的时候,操作系统能够通过映射找到物理地址进而访问物理内存。
Tips:不同的进程的虚拟地址可以完全一样吗?是可以的,因为每个进程都有其各自的页表,是通过映射关系去找寻代码和数据的,所以不影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









