



 本文详细解析了Unicode与UTF8编码的关系,介绍了如何通过C++和Java代码实现Unicode十六进制字符串与UTF8编码之间的相互转换。
本文详细解析了Unicode与UTF8编码的关系,介绍了如何通过C++和Java代码实现Unicode十六进制字符串与UTF8编码之间的相互转换。
问题描述:要把类似 "\x4E00\x6735\x82B1\x1F339" 这样的字符串转换成UTF8编码的可见字符串 "一朵花🌹"
先简单说明一下Unicode与UTF8的关系:
Unicode标准可以理解为一个给世界上所有的字符统一编号的字典,一个字符的Unicode码就是一个编号,也仅仅是一个编号而已,并没有规定这个字符具体要怎么编码bit位来存储和发送。
而UTF8就是具体的编码规则,编码规则如下:
| Unicode码范围 十六进制 | 标量值(scalar value) 二进制 | UTF-8 二进制/十六进制 | 注释 |
|---|---|---|---|
| 000000 - 00007F 128个代码 | 00000000 00000000 0zzzzzzz | 0zzzzzzz(00-7F) | ASCII字符范围,字节由零开始 |
| 七个z | 七个z | ||
| 000080 - 0007FF 1920个代码 | 00000000 00000yyy yyzzzzzz | 110yyyyy(C0-DF) 10zzzzzz(80-BF) | 第一个字节由110开始,接着的字节由10开始 |
| 三个y;二个y;六个z | 五个y;六个z | ||
| 000800 - 00D7FF 00E000 - 00FFFF 61440个代码 [Note 1] | 00000000 xxxxyyyy yyzzzzzz | 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz | 第一个字节由1110开始,接着的字节由10开始 |
| 四个x;四个y;二个y;六个z | 四个x;六个y;六个z | ||
| 010000 - 10FFFF 1048576个代码 | 000wwwxx xxxxyyyy yyzzzzzz | 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz | 将由11110开始,接着的字节由10开始 |
有人可能会疑惑为什么不直接使用Unicode编号来存储和传送字符呢?
主要是因为区分开字符集和编码方案,可使字符的编码存储处理逻辑更清晰、更灵活。
由于Unicode编号只是个数字而已,具体来讲就是short(2字节的Unicode)或者int(4字节扩展Unicode),是定长的, 这对于编号在1字节内的那些常用字符(ASCII字符范围)来说是一种浪费,所以需要UTF8这样的变长编码来节省空间。另一方面,如果是为了更简便快速地进行字符串截断操作,则可考虑使用UTF32这样的定长(4字节)编码。
接下来直接上代码
C++11
Unicode转UTF8
#include <string>
#include <iostream>
#include <locale>
#include <codecvt>
#include <regex>
using namespace std;
/**
* @description: Unicode码的16进制字符串组成的字符串转UTF8字符
* @param src 例:\x4E00\x6735\x82B1\x1F339
* @return UTF8编码的字符串,例:一朵花🌹
*/
string UniHexStrToUtf8(const string& src) {
static regex re(R"(\\x([0-9a-zA-Z]{4,5}))");
regex_token_iterator<string::const_iterator> rend;
regex_token_iterator<string::const_iterator> it(src.begin(), src.end(), re, 1);
wstring_convert<codecvt_utf8<char32_t>, char32_t> conv;
string result;
while (it!=rend) {
result += conv.to_bytes( (char32_t)strtoul((*it).str().c_str(), NULL, 16) );
++it;
}
return result;
}
int main() {
cout << UniHexStrToUtf8(R"(\x4E00\x6735\x82B1\x1F339)") << endl;
return 0;
}运行结果:
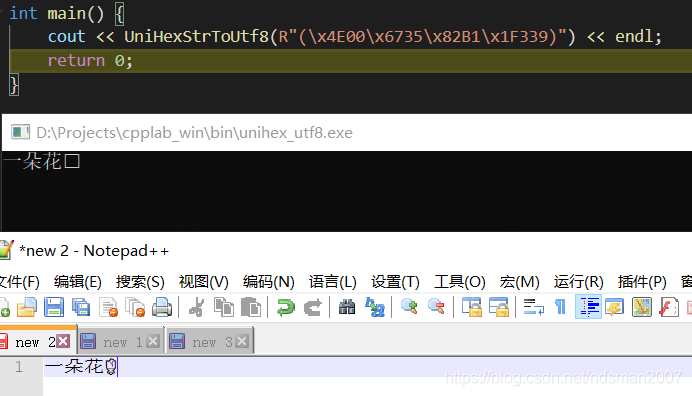
控制台里显示不了emoji,把结果复制粘贴到notepad++里,可以看出没有问题。
UTF8转Unicode
#include <string>
#include <iostream>
#include <locale>
#include <codecvt>
#include <iomanip>
using namespace std;
/**
* @description: UTF8字符串转Unicode码的16进制字符串组成的字符串
* @param src 例:一朵花🌹
* @return Unicode码的16进制字符串组成的字符串,例:\x4E00\x6735\x82B1\x1F339
*/
string Utf8ToUniHexStr(const string& src) {
wstring_convert<codecvt_utf8<char32_t>, char32_t> conv;
u32string u32str = conv.from_bytes(src);
stringstream result;
for (char32_t ch : u32str) {
result << "\\x" << hex << setw(4) << setfill('0') << ch;
}
return result.str();
}
int main() {
cout << Utf8ToUniHexStr(u8"一朵花🌹") << endl;
return 0;
}运行结果:
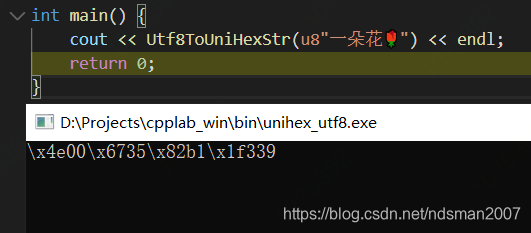
JAVA (8+)
Unicode转UTF8 和 UTF8转Unicode
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringUtils {
public static String UniHexStrToUtf8(String src) {
Pattern r = Pattern.compile("\\\\x([0-9a-zA-Z]{4,5})");
Matcher m = r.matcher(src);
StringBuilder result = new StringBuilder();
while (m.find()) {
result.append(Character.toChars(Integer.parseInt(m.group(1), 16)));
}
return result.toString();
}
public static String Utf8ToUniHexStr(String src) {
StringBuilder result = new StringBuilder();
for (int ch : src.codePoints().toArray()) {
result.append(String.format("\\x%04x", ch));
}
return result.toString();
}
public static void main(String[] args) {
System.out.println(UniHexStrToUtf8("\\x4E00\\x6735\\x82B1\\x1F339"));
System.out.println(Utf8ToUniHexStr("一朵花\uD83C\uDF39"));
}
}运行结果:
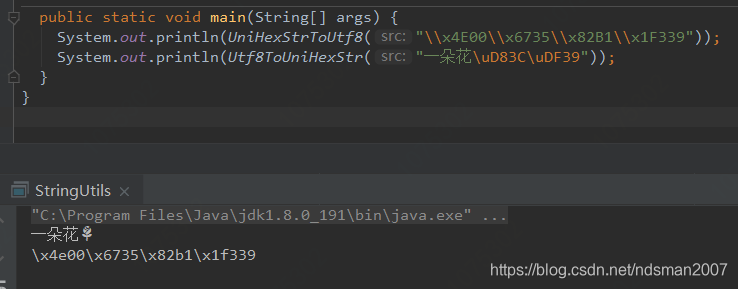

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









