




先来看看这个课程设计1的要求:
本课程设计的难度,是到目前为止最难的。
首先,涉及到第8章的实验七的内容,也就是对Power idea公司的数据的分析和程序的编写,关于这一部分内容,可以复习一下千哥前面写的笔记:《千哥读书笔记:汇编语言(王爽第四版)第8章实验七》。
其次,涉及到本章的三个程序的编写,即“显示字符串(show_str)”、“解决除法溢出的问题(divdw)”、“数值显示(dtoc)”。
关于这一部分内容,可以复习一下千哥前面写的两篇笔记:
《千哥读书笔记:汇编语言(王爽第四版)第10章实验10第2题divdw程序编写》
《千哥读书笔记:汇编语言(王爽)第10章实验10三个子程序的源码》
进一步说,如果不搞清楚以上内容,要想写出课程设计1的程序,几乎是不可能完成的任务。
接下来,根据前面的基础内容,捋一下编写这个程序的思路:
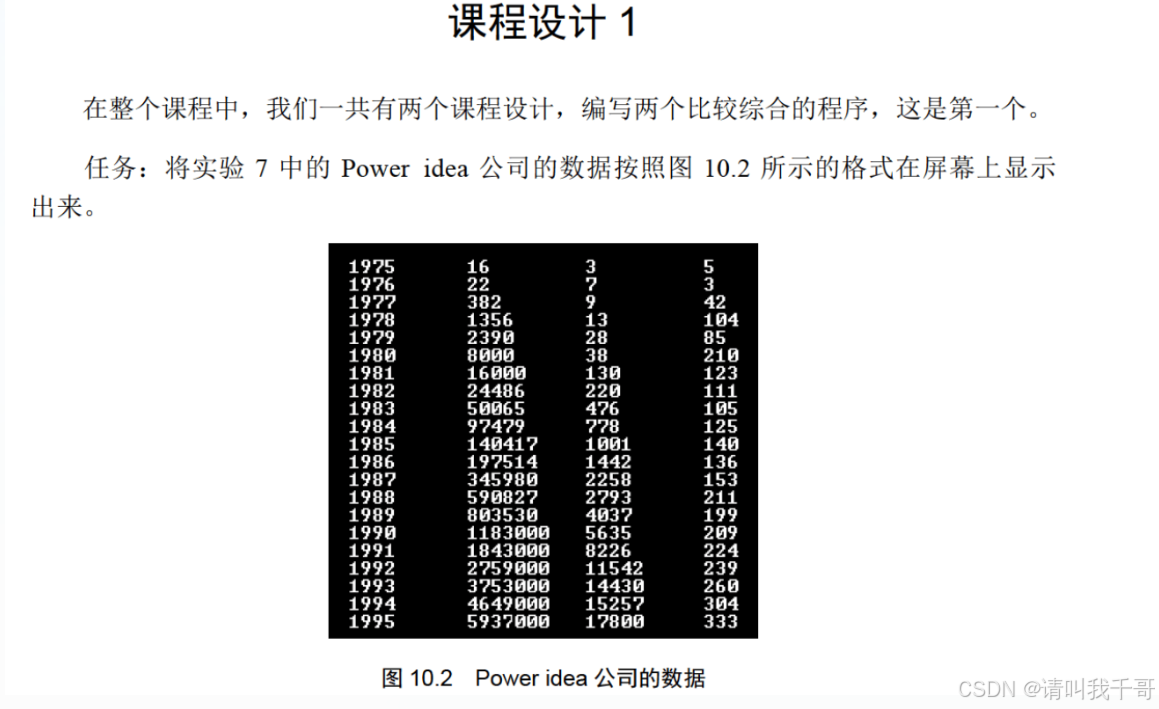
1、Power idea公司的相关数据,也就是年份、收入、雇员人数、人均收入这4组数据,要向b800H显示缓冲区输出,最终显示在屏幕上。因此编程的思路和《汇编语言(王爽第四版)第8章实验七》是完全不一样的,实验七是要求将数据存放在table段中,并覆盖原先的“year summ ne ??”字符串。
2、整个编程的流程,主要分为两个大的部分:一是将年份、收入、雇员人数、人均收入这4组数据进行初始化,将相关数据转化为以0结尾的字符串;二是将这些字符串按照上述字段顺序排列,显示在屏幕上。
3、对于该流程的第一部分,需建立相应数据的缓冲区,将转化后的字符串保存在相应的缓冲区;对于该程序的第二部分,从相应的缓冲区中读取转化后的字符串,然后输出到b800H显示缓冲区,完成字符串在屏幕的显示。
4、在原书的设定中,收入数据定义了21个dword型数据。每一个数据(比如最后一个收入数据5937000,16进制为5A9768H)必须用到两个寄存器(AX、DX)作为被除数、10作为除数,进行32位的除法运算,以获得在字符串转化过程中所需的余数(即:字符=余数+30H)。但一些数据在进行除法运算的时候,会导致溢出,为防止这一过程产生,就会调用到divdw子程序。因此,对divdw子程序的理解和调用,在编程的过程中非常重要。
5、对于其他不会产生32位除法溢出的数据,只需要调用原生的DIV指令进行32位除法运算,得到字符串转化过程中的所需的余数即可。
6、在所有字段的字符串初始化完毕之后,调用show_str子程序,将相关字符串显示在屏幕上。
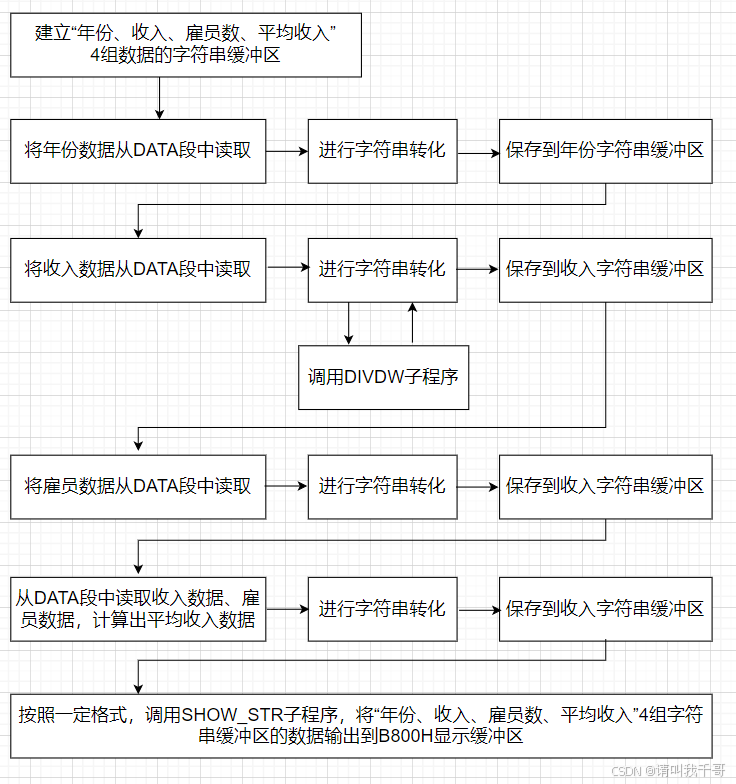
基本的设计流程如下图:
根据以上思路,贴出一部分代码:
一、建立相应的字符串缓冲区
===================
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21组字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
year_buffer segment
db 105 dup(0);年份数据缓冲区,每个年份数据占4个字节,再加上1个0占1个字节,21组年份数据共105个字节
year_buffer ends
gross_buffer segment
db 147 dup(0);收入数据缓冲区,以最大数值5937000的字符串长度7为标准,每个数字的字符占1个字节,21组收入数据占147个字节
gross_buffer ends
employee_buffer segment
db 105 dup(0);雇员人数数据缓冲区,以最大数值17800的字符串长度5为标准,每个数字的字符占1个字节,21组雇员人数数据共105个字节
employee_buffer ends
average_buffer segment
db 63 dup(0);人均收入数据缓冲区,以最大数值5937000/17800=333的字符串长度3为标准,每个数字的字符占1个字节,21组人均收入数据共63个字节
average_buffer ends
===================
在这一步很简单,建立了四个缓冲区:year_buffer 、gross_buffer、employee、average。建立的过程中,进行初步测算,确立每个缓冲区的大小。
二、始化21个年份数据
====================
codesg segment
start:
;初始化21个年份数据,让每个年份数据的尾部加上0使其成为一个字符串,然后保存在year_buffer中
mov ax,data
mov ds,ax
mov bx,0
mov si,0
mov di,0
mov cx,21
year_save:
mov ax,year_buffer
mov es,ax
mov ax,ds:[si]
mov es:[bx],ax
mov ax,ds:[si+2]
mov es:[bx+2],ax
mov ax,0;每个年份数据的尾部加上0
mov es:[bx+4],al
add si,4
add bx,5
loop year_save
====================
这一步相对比较简单,因为年份数据本身是以字符的形式保存在data段的,所以在读取相应的字符之后,在其尾部加上0,然后保存在year_buffer中即可。
三、初始化21个收入数据
====================
;初始化21个收入数据,将每组数据转换为字符串,然后保存在gross_buffer中
mov ax,data
mov ds,ax
mov ax,gross_buffer
mov es,ax
mov bx,0
mov si,84;21个收入数据,从第84字节开始
mov di,0
mov cx,21
gross_save:
push cx
mov ax,ds:[si];将每一个收入数据的低16位数据保存在AX中
mov dx,ds:[si+2];将每一个收入数据的高16位数据保存在DX中
mov bp,0;BP作为计数器,用于记录每次调用divdw的次数
divdw_loop:
mov cx,0ah;让CX为10,作为除数
call divdw;调用防止溢出的divdw子程序,每次调用一次,获得一个余数,最后一次调用获得AX的低16位商0
inc bp;BP每次加1,记录每次调用divdw循环的次数
push cx;将每次获得的余数保存在栈中
mov cx,ax;将每次调用divdw获得的商AX的低16位数据保存在CX中,如果商AX为0,表示最后一次调用
jcxz divdw_ok;比较CX是否为0,为0表示最后一次调用
jmp short divdw_loop
divdw_ok:
mov cx,bp;将每次读取一组收入数据调用的divdw程序的次数,保存在CX中,作为出栈的次数
gross_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在缓冲区中
inc di;DI每次加1,位移1个字节
loop gross_trans
mov al,0;将0保存在AL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在缓冲区中
add si,4;在21个收入数据中,每次循环SI加4,指向下一个收入数据
pop cx
loop gross_save
===================
这一步相对比较复杂,特别是涉及对divdw子程序的理解和调用,其基本原理在我写的《千哥读书笔记:汇编语言(王爽第四版)第10章实验10第2题divdw程序编写》有详细介绍,这里不作过多阐述。
总之,调用一次divdw子程序,就会产生一个与相关数据对应的余数。比如最后一个收入数据5937000,第一次调用的时候会产生余数0,第二次调用的时候会产生余数0,以此类推,在最后一次调用之后,会产生余数5。而这些余数最终于30H相加,就会得到相应数字的字符串编码。
在这个过程中,必须将调用divdw子程序所产生的余数,压入栈中,然后通过一个循环体来弹出这些余数。而根据栈操作“后进先出”的原则,就可以按照人类书写数字的习惯,从左到右将相关数字进行排列。
比如5937000,其压栈的顺序是0,0,0,7,3,9,5;出栈的顺序则是5,9,3,7,0,0,0。通过这种方式,将转化后的字符16进制值(余数+30H),在gross_buffer缓冲区中,从低字节向高字节方向保存。
之所以用到一个寄存器BP,来记录并保存调用divdw子程序的次数,是因为每次进行一个收入数据(比如5937000)到字符串的转化过程中,每个收入数据的字符串长度是不一样的。
每一个收入数据(比如5937000)进行字符串转化时,当寄存器BP获得调用divdw子程序的次数后,再通过BP将循环次数赋值给CX,最后通过 loop gross_trans循环,实现每一个转化后的字符串在gross_buffer缓冲区的保存。
下面是divdw子程序代码:
===================
;防止溢出的除法子程序,利用公式:X/N = int(H/N)*65536 + [rem(H/N)*65536+L]/N。例如:被除数为5A9768H(十进制5937000),除数是0aH(十进制10)
divdw:
mov bx,ax;将AX中保存了被除数5A9768H的低16位数据9768H,保存到BX中,BX作为临时变量。
mov ax,dx;将DX中保存了被除数5A9768H的高16位数据005aH,保存到AX中,AX作为除法运算被除数的低16位。
mov dx,0;将DX清零,作为除法运算被除数的高16位。
div cx ;CX作为除数,这时被除数是32位的,即0000005aH,DX是0000H,AX是005aH。运行后,DX存放余数,AX存放商。
push ax ;通过压栈操作,保存AX中的商,即是最后商的高16位。
mov ax,bx ;将临时变量BX中的被除数5A9768H的低16位数据9768H,恢复到AX,作为新一轮除法运算中被除数的低16位数据。
div cx ;此时在上一轮除法运算中DX中的余数,作为被除数的高16位,AX中的数据作为被除数的低16位,进行除法运算。
mov cx,dx ;得到的余数保存在DX中,然后通过DX保存到cx
pop dx ;将最后商的高16位弹出栈,保存在DX中,成为最后商的高16位,低16位已经在ax中。
ret
===================
而本课程设计中的divdw子程序,仅仅是对原有《千哥读书笔记:汇编语言(王爽第四版)第10章实验10第2题divdw程序编写》的divdw子程序进行了略微的修改,以适应始化21个收入数据的需要。
四、初始化21个雇员人数数据
===================
;初始化21个雇员人员数据,将每组数据转换为字符串,然后保存在employee_buffer中
mov ax,data
mov ds,ax
mov ax,employee_buffer
mov es,ax
mov si,168;21个雇员人数数据,从第168字节开始
mov di,0
mov cx,21
employee_save:
push cx
mov ax,ds:[si];将每一个雇员人数数据的低16位数据保存在AX中
mov bp,0;BP作为计数器,用于记录每次调用div的次数
mov bx,0ah;让bX为10,作为除数
employ_div:
mov dx,0;使用32位除以16位的除法,被除数的高16位设置为0,存放在DX中,被除数的低16位存放在AX中
div bx;32位除以16位除法,商默认保存在AX中,余数默认保存在DX中
inc bp;BP每次加1,记录每次调用div循环的次数
mov cx,ax;将商赋值给CX
push dx;将DX保存的余数压入栈中
jcxz ediv_ok;如果CX为零就跳出循环,进入ediv_ok
jmp short employ_div
ediv_ok:
mov cx,bp;将每次调用div的次数,保存在CX中,作为出栈的次数
employee_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在缓存区中
inc di;DI每次加1,位移1个字节
loop employee_trans
mov al,0;将0保存在aL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在缓存区中
add si,2;在21个雇员人数数据中,每次循环SI加2,指向下一个雇员人数数据
pop cx
loop employee_save
===================
这一步的基本思路,和第三步(始化21个收入数据)差不多,只是运用除法运算的方式上有所差别。由于21个雇员人数数据都不是超长数据,在进行32位除法的时候,不会产生溢出,因此直接调用原生DIV指令就可以达到相应效果。
五、初始化21个人均收入数据
===================
;初始化21个人均收入数据,将每组数据转换为字符串,然后保存在average_buffer中
mov ax,data
mov ds,ax
mov ax,average_buffer
mov es,ax
mov si,84;21个收入数据,从第84字节开始
mov bx,168;21个雇员人数数据,从第168字节开始
mov di,0
mov cx,21
average_save:
push cx
mov ax,ds:[si];将每一个收入数据的低16位数据保存在AX中,AX保存被除数的低16位数据
mov dx,ds:[si+2];将每一个收入数据的高16位数据保存在DX中,DX保存被除数的高16位数据
div word ptr ds:[bx];21个雇员人数数据,从第168字节开始,每个雇员人数作为除数,商默认保存在AX中
push bx;将bx保存在栈中
mov bx,0ah;让bX为10,在标号average_div中作为除数,进行字符串转化
mov bp,0;BP作为计数器,用于记录每次调用div的次数
average_div:
mov dx,0;使用32位除以16位的除法,被除数的高16位设置为0,存放在DX中,被除数的低16位存放在AX中
div bx;32位除以16位除法,商默认保存在AX中,余数默认保存在DX中
inc bp;BP每次加1,记录每次调用div循环的次数
mov cx,ax;将商赋值给CX
push dx;将DX保存的余数压入栈中
jcxz adiv_ok;如果CX为零就跳出循环,进入adiv_ok
jmp short average_div
adiv_ok:
mov cx,bp;将每次调用div的次数,保存在CX中,作为出栈的次数
average_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在average_buffer缓存区中
inc di;DI每次加1,位移1个字节
loop average_trans
mov al,0;将0保存在AL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在average_buffer缓存区中
add si,4;在21个收入数据中,每次循环SI加4,指向下一个收入数据
pop bx;恢复BX数据
add bx,2;在21个雇员人数数据中,每次循环BX加2,
pop cx
loop average_save
===================
在这一步的字符串转化和存储过程中,由于21个人均收入数据并不是一个事先设定好的数据,需要通过收入数据和雇员人数进行除法运算才能得到,因此才有了这段代码:
mov ax,ds:[si];将每一个收入数据的低16位数据保存在AX中,AX保存被除数的低16位数据
mov dx,ds:[si+2];将每一个收入数据的高16位数据保存在DX中,DX保存被除数的高16位数据
div word ptr ds:[bx];21个雇员人数数据,从第168字节开始,每个雇员人数作为除数,商默认保存在AX中
通过对AX、DX的赋值,然后直接除以DATA段中保存了雇员人数数据的内存单元内容,即div word ptr ds:[bx],获得相应的商,这个商值就是人均收入数据,默认保存在AX中,然后又可以进行下一步的字符串转化。
六、逐次向显示缓冲区输出年份、收入、雇员人数、人均收入这4组数据转化后的字符串
===================
;调用show_year子程序,显示年份数据。
mov bx,644;从显示缓冲区的第4行第2列开始
mov ax,year_buffer;将year_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示收入数据。
mov bx,662;从显示缓冲区的第4行第11列开始
mov ax,gross_buffer;将gross_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示总雇员人数数据。
mov bx,686;从显示缓冲区的第4行第23列开始
mov ax,employee_buffer;将employee_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示人均收入数据。
mov bx,706;从显示缓冲区的第4行第33列开始
mov ax,average_buffer;将average_buffe地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
mov ax,4c00h
int 21h
===================
这一步没什么可多讲的,无非就是计算好每一组字符串应在屏幕显示的位置,然后调用show_str子程序,下面是show_str子程序代码:
===================
;字符串显示子程序
show_str:
mov ax,0b800h;将显示缓冲区地址保存在AX中,并将ES指向该地址
mov es,ax
mov al,111B;将白色属性00000111赋值给al
mov cx,21
mov si,0
str_loop1:
push cx
mov di,0
str_loop2:
mov cl,ds:[si];按字节读取1个字符
mov ch,0
jcxz str_loop_ok
mov ch,al;将白色属性00000111赋值给CH
mov es:[bx+di],cx;
inc si
add di,2;di的位移为2,也是因为每一列的字符,实际占了两个字节
jmp short str_loop2
str_loop_ok:
pop cx
inc si
add bx,160
loop str_loop1
ret
codesg ends
end start
===================
以上即是千哥对本课程设计的所有思路和方法,当然,如果你有更好的思路,欢迎交流。
最后,贴出完整的代码:
===================
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21组字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
year_buffer segment
db 105 dup(0);年份数据缓存区,每个年份数据占4个字节,再加上1个0占1个字节,21组年份数据共105个字节
year_buffer ends
gross_buffer segment
db 147 dup(0);收入数据缓存区,以最大数值5937000的字符串长度7为标准,每个数字的字符占1个字节,21组收入数据占147个字节
gross_buffer ends
employee_buffer segment
db 105 dup(0);雇员人数数据缓存区,以最大数值17800的字符串长度5为标准,每个数字的字符占1个字节,21组雇员人数数据共105个字节
employee_buffer ends
average_buffer segment
db 63 dup(0);人均收入数据缓存区,以最大数值5937000/17800=333的字符串长度3为标准,每个数字的字符占1个字节,21组人均收入数据共63个字节
average_buffer ends
codesg segment
start:
;初始化21个年份数据,让每个年份数据的尾部加上0使其成为一个字符串,然后保存在year_buffer中
mov ax,data
mov ds,ax
mov bx,0
mov si,0
mov di,0
mov cx,21
year_save:
mov ax,year_buffer
mov es,ax
mov ax,ds:[si]
mov es:[bx],ax
mov ax,ds:[si+2]
mov es:[bx+2],ax
mov ax,0;每个年份数据的尾部加上0
mov es:[bx+4],al
add si,4
add bx,5
loop year_save
;初始化21个收入数据,将每组数据转换为字符串,然后保存在gross_buffer中
mov ax,data
mov ds,ax
mov ax,gross_buffer
mov es,ax
mov bx,0
mov si,84;21个收入数据,从第84字节开始
mov di,0
mov cx,21
gross_save:
push cx
mov ax,ds:[si];将每一个收入数据的低16位数据保存在AX中
mov dx,ds:[si+2];将每一个收入数据的高16位数据保存在DX中
mov bp,0;BP作为计数器,用于记录每次调用divdw的次数
divdw_loop:
mov cx,0ah;让CX为10,作为除数
call divdw;调用防止溢出的divdw子程序,每次调用一次,获得一个余数,最后一次调用获得AX的低16位商0
inc bp;BP每次加1,记录每次调用divdw循环的次数
push cx;将每次获得的余数保存在栈中
mov cx,ax;将每次调用divdw获得的商AX的低16位数据保存在CX中,如果商AX为0,表示最后一次调用
jcxz divdw_ok;比较CX是否为0,为0表示最后一次调用
jmp short divdw_loop
divdw_ok:
mov cx,bp;将每次读取一组收入数据调用的divdw程序的次数,保存在CX中,作为出栈的次数
gross_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在缓存区中
inc di;DI每次加1,位移1个字节
loop gross_trans
mov al,0;将0保存在aL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在缓存区中
add si,4;在21个收入数据中,每次循环SI加4,指向下一个收入数据
pop cx
loop gross_save
;初始化21个雇员人员数据,将每组数据转换为字符串,然后保存在employee_buffer中
mov ax,data
mov ds,ax
mov ax,employee_buffer
mov es,ax
mov si,168;21个雇员人数数据,从第168字节开始
mov di,0
mov cx,21
employee_save:
push cx
mov ax,ds:[si];将每一个雇员人数数据的低16位数据保存在AX中
mov bp,0;BP作为计数器,用于记录每次调用div的次数
mov bx,0ah;让bX为10,作为除数
employ_div:
mov dx,0;使用32位除以16位的除法,被除数的高16位设置为0,存放在DX中,被除数的低16位存放在AX中
div bx;32位除以16位除法,商默认保存在AX中,余数默认保存在DX中
inc bp;BP每次加1,记录每次调用div循环的次数
mov cx,ax;将商赋值给CX
push dx;将DX保存的余数压入栈中
jcxz ediv_ok;如果CX为零就跳出循环,进入ediv_ok
jmp short employ_div
ediv_ok:
mov cx,bp;将每次调用div的次数,保存在CX中,作为出栈的次数
employee_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在缓存区中
inc di;DI每次加1,位移1个字节
loop employee_trans
mov al,0;将0保存在aL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在缓存区中
add si,2;在21个雇员人数数据中,每次循环SI加2,指向下一个雇员人数数据
pop cx
loop employee_save
;初始化21个人均收入数据,将每组数据转换为字符串,然后保存在average_buffer中
mov ax,data
mov ds,ax
mov ax,average_buffer
mov es,ax
mov si,84;21个收入数据,从第84字节开始
mov bx,168;21个雇员人数数据,从第168字节开始
mov di,0
mov cx,21
average_save:
push cx
mov ax,ds:[si];将每一个收入数据的低16位数据保存在AX中,AX保存被除数的低16位数据
mov dx,ds:[si+2];将每一个收入数据的高16位数据保存在DX中,DX保存被除数的高16位数据
div word ptr ds:[bx];21个雇员人数数据,从第168字节开始,每个雇员人数作为除数,商默认保存在AX中
push bx;将bx保存在栈中
mov bx,0ah;让bX为10,在标号average_div中作为除数,进行字符串转化
mov bp,0;BP作为计数器,用于记录每次调用div的次数
average_div:
mov dx,0;使用32位除以16位的除法,被除数的高16位设置为0,存放在DX中,被除数的低16位存放在AX中
div bx;32位除以16位除法,商默认保存在AX中,余数默认保存在DX中
inc bp;BP每次加1,记录每次调用div循环的次数
mov cx,ax;将商赋值给CX
push dx;将DX保存的余数压入栈中
jcxz adiv_ok;如果CX为零就跳出循环,进入adiv_ok
jmp short average_div
adiv_ok:
mov cx,bp;将每次调用div的次数,保存在CX中,作为出栈的次数
average_trans:
pop ax;将每次获得的余数出栈,保存在AX中
add ax,30h;将余数加上30H,得到余数对应的字符
mov es:[di],ax;将余数字符保存在average_buffer缓存区中
inc di;DI每次加1,位移1个字节
loop average_trans
mov al,0;将0保存在AL中,作为字符串的结束符
inc di;DI再加1,指向最后一个0字符
mov es:[di],al;将0保存在average_buffer缓存区中
add si,4;在21个收入数据中,每次循环SI加4,指向下一个收入数据
pop bx;恢复BX数据
add bx,2;在21个雇员人数数据中,每次循环BX加2,
pop cx
loop average_save
;调用show_year子程序,显示年份数据。
mov bx,644;从显示缓冲区的第4行第2列开始
mov ax,year_buffer;将year_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示收入数据。
mov bx,662;从显示缓冲区的第4行第11列开始
mov ax,gross_buffer;将gross_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示总雇员人数数据。
mov bx,686;从显示缓冲区的第4行第23列开始
mov ax,employee_buffer;将employee_buffer地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
;调用show_str子程序,显示人均收入数据。
mov bx,706;从显示缓冲区的第4行第33列开始
mov ax,average_buffer;将average_buffe地址保存在AX中,并将DS指向该地址
mov ds,ax
call show_str
mov ax,4c00h
int 21h
;防止溢出的除法子程序,利用公式:X/N = int(H/N)*65536 + [rem(H/N)*65536+L]/N。例如:被除数为5A9768H(十进制5937000),除数是0aH(十进制10)。
divdw:
mov bx,ax;将AX中保存了被除数5A9768H的低16位数据9768H,保存到BX中,BX作为临时变量。
mov ax,dx;将DX中保存了被除数5A9768H的高16位数据005aH,保存到AX中,AX作为除法运算被除数的低16位。
mov dx,0;将DX清零,作为除法运算被除数的高16位。
div cx ;CX作为除数,这时被除数是32位的,即0000005aH,DX是0000H,AX是005aH。运行后,DX存放余数,AX存放商。
push ax ;通过压栈操作,保存AX中的商,即是最后商的高16位。
mov ax,bx ;将临时变量BX中的被除数5A9768H的低16位数据9768H,恢复到AX,作为新一轮除法运算中被除数的低16位数据。
div cx ;此时在上一轮除法运算中DX中的余数,作为被除数的高16位,AX中的数据作为被除数的低16位,进行除法运算。
mov cx,dx ;得到的余数保存在DX中,然后通过DX保存到cx
pop dx ;将最后商的高16位弹出栈,保存在DX中,成为最后商的高16位,低16位已经在AX中。
ret
;字符串显示子程序
show_str:
mov ax,0b800h;将显示缓冲区地址保存在AX中,并将ES指向该地址
mov es,ax
mov al,111B;将白色属性00000111赋值给al
mov cx,21
mov si,0
str_loop1:
push cx
mov di,0
str_loop2:
mov cl,ds:[si];按字节读取1个字符
mov ch,0
jcxz str_loop_ok
mov ch,al;将白色属性00000111赋值给CH
mov es:[bx+di],cx;
inc si
add di,2;di的位移为2,也是因为每一列的字符,实际占了两个字节
jmp short str_loop2
str_loop_ok:
pop cx
inc si
add bx,160
loop str_loop1
ret
codesg ends
end start
===================
将该代码命名为:p10104.asm,编译通过,然后在DOSBOX下运行,如下图所示:
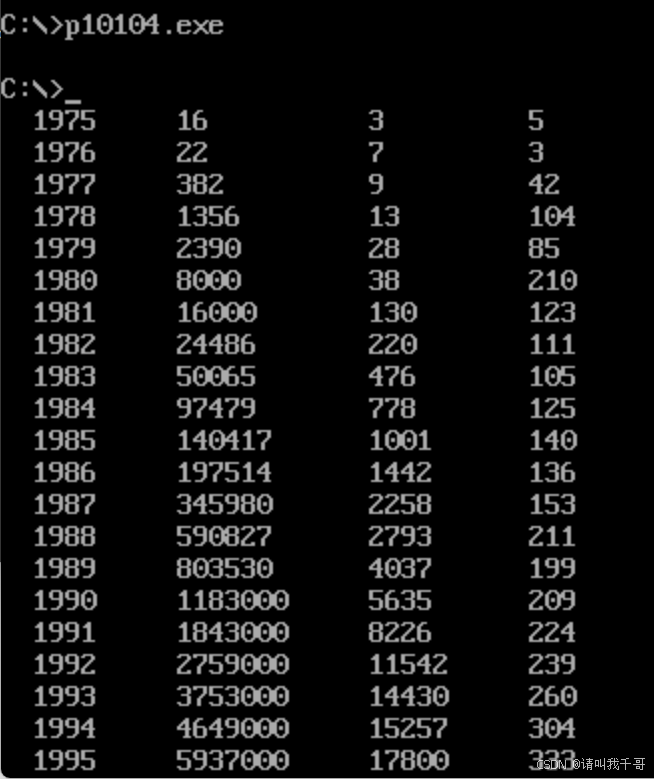
完美实现本课程设计要求。打完收工。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









